Kafka几乎是当今时代背景下数据管道的首选,无论你是做后端开发、还是大数据开发,对它可能都不陌生。开源软件Kafka的应用越来越广泛。
面对Kafka的普及和学习热潮,哪吒想分享一下自己多年的开发经验,带领读者比较轻松地掌握Kafka的相关知识。
今天系统的说一下Kafka的分区策略,实现步步为营,逐个击破,拿下Kafka。
一、Kafka主题的分区策略概述
理解Kafka主题的分区策略对于构建高性能的消息传递系统至关重要。深入探讨Kafka分区策略的重要性以及如何在分布式消息传递中使用它。
1、什么是Kafka主题的分区策略?
Kafka是一个分布式消息传递系统,用于实现高吞吐量的数据流。消息传递系统的核心是主题(Topics),而这些主题可以包含多个分区(Partitions)。
分区是Kafka的基本并行处理单位,允许数据并发处理。
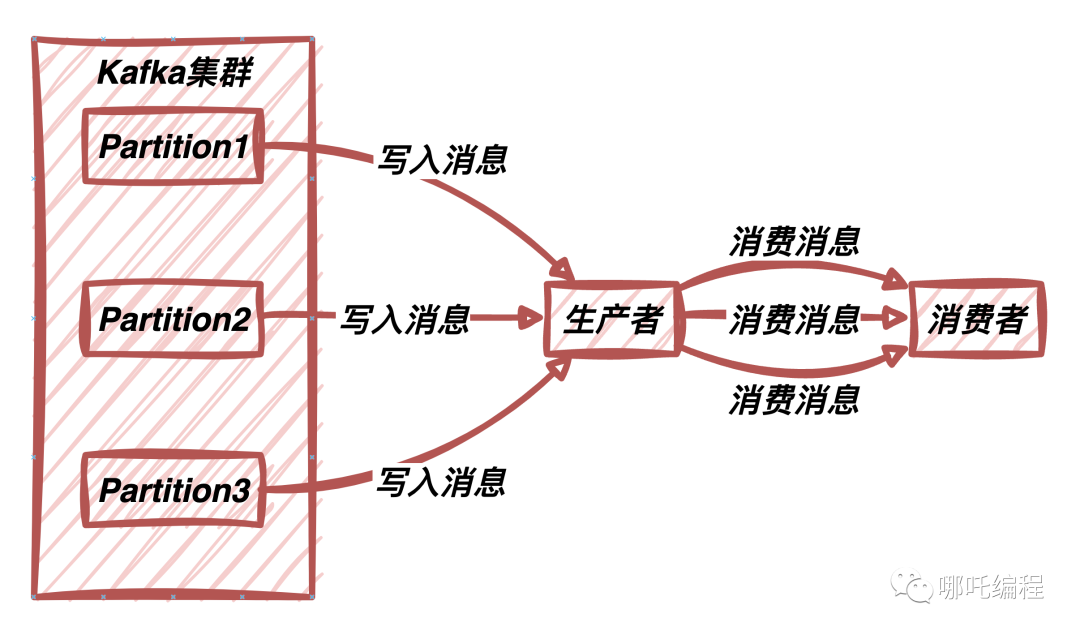
分区策略定义了消息在主题中如何分配到不同的分区。它决定了消息将被写入哪个分区,以及在消费时如何从不同分区读取消息。
分区策略是Kafka的关键组成部分,直接影响到Kafka集群的性能和数据的顺序性。
2、为什么分区策略重要?
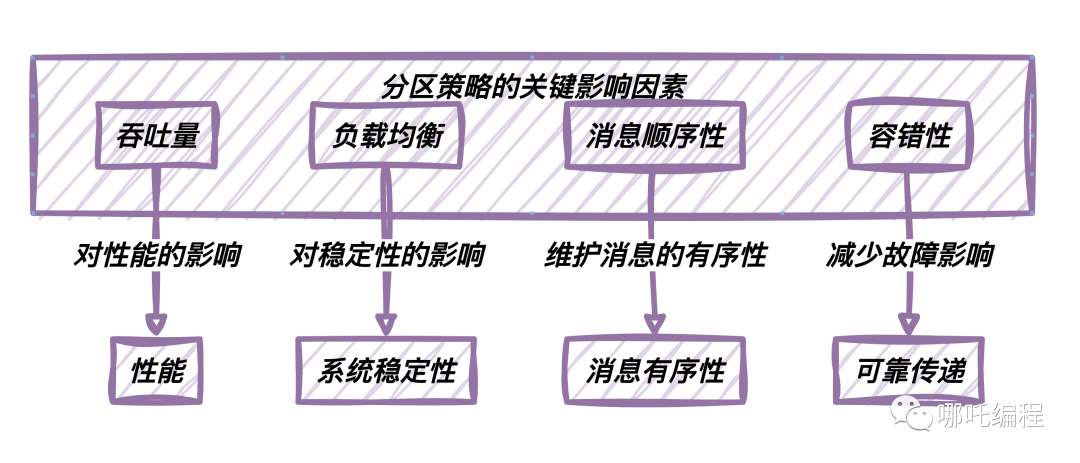
分区策略的选择对Kafka系统的性能、伸缩性和容错性产生深远影响。
以下是一些分区策略的关键影响因素:
- 吞吐量:合理的分区策略可以提高Kafka集群的吞吐量。它允许消息并行处理,提高了数据传递的效率。
- 负载均衡:分区策略有助于均衡Kafka集群中各个分区的负载。均衡的分区分布意味着没有过载的分区,从而提高了系统的稳定性。
- 顺序性:某些应用程序需要保持消息的顺序性,因此选择正确的分区策略对于维护消息的有序性至关重要。
- 容错性:合适的分区策略可以减少故障对系统的影响。在节点故障时,分区策略可以确保消息的可靠传递。
二、Kafka默认分区策略
1、Round-Robin分区策略
Kafka默认的分区策略是Round-Robin。这意味着当生产者将消息发送到主题时,Kafka会循环选择每个分区,以便均匀分布消息。
Round-Robin策略的工作原理如下:
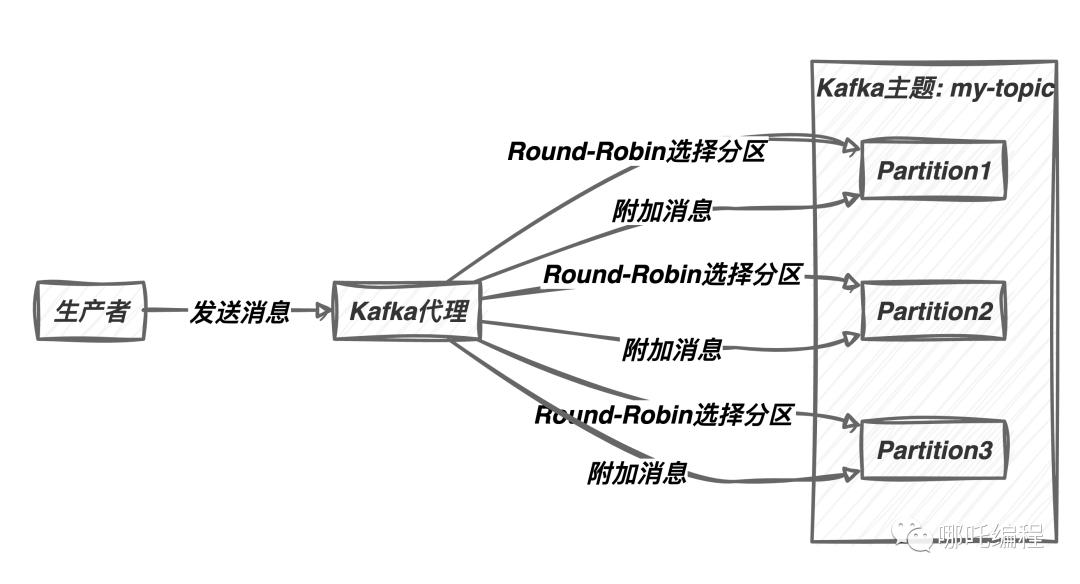
- 生产者发送消息到主题时,不指定目标分区。
- Kafka代理根据Round-Robin算法选择下一个可用分区。
- 消息被附加到选定的分区。
这个策略适用于以下情况:
- 当消息的键没有特定的含义或用途时,Round-Robin是一种简单的分区策略。
- 当你希望均匀地将消息分布到各个分区时,这是一种有效的策略。
这段代码示例展示了如何创建一个使用Round-Robin分区策略的Kafka生产者。以下是代码的详细说明:
导入所需的库:
设置Kafka生产者的配置属性:
- "bootstrap.servers": 这是Kafka代理的地址,生产者将与之建立连接。
- "key.serializer": 用于序列化消息键的序列化器。
- "value.serializer": 用于序列化消息值的序列化器。
创建Kafka生产者:
使用生产者发送消息到主题("my-topic"),这里演示了两个消息:
ProducerRecord用于指定要发送到的主题、消息的键和值。
最后,不要忘记在使用生产者结束时关闭它:
这段代码创建了一个Kafka生产者,使用Round-Robin分区策略将消息发送到名为"my-topic"的主题。这是一个简单但常见的用例,适用于那些不需要特定分区策略的情况,只需均匀地将消息分布到各个分区。
三、自定义分区策略
1、编写自定义分区器

有时,Kafka默认的Round-Robin策略不能满足特定的需求。在这种情况下,你可以编写自定义的分区策略。自定义分区策略为你提供了更大的灵活性,允许你根据消息的键来选择分区。
要编写自定义分区器,你需要实现org.apache.kafka.clients.producer.Partitioner接口,并实现以下方法:
- int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster): 该方法根据消息的键来选择分区,并返回分区的索引。
- void close(): 在分区器关闭时执行的清理操作。
- void configure(Map<String, ?> configs): 配置分区器。
下面是一个示例,展示了如何编写自定义分区器的Java类:
2、最佳实践:如何选择分区策略
选择适当的分区策略是关键,它直接影响到你的Kafka应用程序的性能和行为。
以下是一些建议,帮助你选择最合适的分区策略:
- 考虑消息的含义:消息的键如果具有特定的含义,例如地理位置或用户ID,可以使用自定义分区策略来确保相关消息被写入同一分区,以维护数据的局部性。
- 性能测试和评估:在选择分区策略之前,进行性能测试和评估非常重要。不同的策略可能会产生不同的性能影响。
- 负载均衡:确保分区策略能够均衡地分配负载到Kafka集群的各个节点。避免
出现过载的分区,以维持系统的稳定性。
你可以在生产者的配置中指定使用哪个分区器,如下所示:
四、分区策略的性能考量
1、数据均衡
在Kafka中,数据均衡是分区策略中的一个关键因素。如果分区不平衡,可能会导致一些分区处理的数据量远大于其他分区,从而引起负载不均匀的问题。
如何确保每个分区处理的数据量大致相等,以避免不均匀的负载。
在实际情况中,数据均衡的问题可能是由于消息的键分布不均匀而引起的。
为了解决这个问题,你可以考虑以下几种方法:
- 自定义分区策略:根据消息的键来选择分区,以确保相关消息被写入同一分区。这可以维护数据的局部性,有助于减少分区不均衡。
- 分区重分配:定期检查分区的数据量,如果发现不均衡,可以考虑重新分配分区。这可以是手动的过程,也可以借助工具来自动实现。
2、高吞吐量
高吞吐量是Kafka集群的一个关键性能指标,分区策略对Kafka集群吞吐量有哪些影响。同时,我们将提供性能优化的策略,包括深入分析吞吐量瓶颈和性能调整。
要实现高吞吐量,你可以考虑以下几个方面的性能优化:
- 调整生产者设置:通过调整生产者的配置参数,如batch.size和linger.ms,可以实现更高的吞吐量。这些参数影响了消息的批量发送和等待时间,从而影响了吞吐量。
- 水平扩展:如果Kafka集群的吞吐量需求非常高,可以考虑通过添加更多的Kafka代理节点来进行水平扩展。这将增加集群的整体吞吐量。
- 监控和调整:定期监控Kafka集群的性能,并根据需要进行调整。使用监控工具来检测性能瓶颈,例如高负载的分区,然后采取措施来解决这些问题。
3、顺序性
Kafka以其出色的消息顺序性而闻名。然而,分区策略可以影响消息的顺序性。分区策略如何影响消息的顺序性,以及如何确保具有相同键的消息被写入到同一个分区,以维护消息的有序性。
保持消息的有序性对于某些应用程序至关重要。如果消息被分散写入到多个分区,它们可能会以不同的顺序被消费。要确保有序性,你可以考虑以下几种方法:
- 自定义分区策略:使用自定义分区策略,根据消息的键来选择分区。这将确保具有相同键的消息被写入到同一个分区,维护消息的有序性。
- 单一分区主题:对于需要维护强有序性的数据,可以考虑将它们写入单一分区的主题。这样,无论你使用什么分区策略,这些消息都将在同一个分区中。
- 监控消息顺序性:定期监控消息的顺序性,确保没有异常情况。使用Kafka提供的工具来检查消息的分区分布和顺序。
这些策略可以帮助你在高吞吐量的同时维护消息的顺序性,确保数据的正确性和一致性。
以上内容详细介绍了分区策略的性能考量,包括数据均衡、高吞吐量和顺序性。理解这些性能因素对于设计和优化Kafka应用程序至关重要。希望这些信息对你有所帮助。
五、示例:使用不同分区策略
在这一部分,我们将通过示例演示如何使用不同的分区策略来满足特定的需求。
我们将提供示例代码、输入数据、输出数据以及性能测试结果,以便更好地理解每种策略的应用和影响。
1、示例1:Round-Robin策略
背景:
假设你正在构建一个日志记录系统,需要将各种日志消息发送到Kafka以供进一步处理。在这种情况下,你可能对消息的分区不太关心,因为所有的日志消息都具有相似的重要性。这是Round-Robin策略可以派上用场的场景。
示例:
输出:
- 日志消息1被写入分区1
- 日志消息2被写入分区2
- 日志消息3被写入分区3
性能测试:
Round-Robin策略通常表现出很好的吞吐量,因为它均匀地分配消息到不同的分区。
在这个示例中,吞吐量将取决于Kafka集群的性能和生产者的配置。
2、示例2:自定义分区策略
背景:
现在假设你正在构建一个电子商务平台,需要将用户生成的订单消息发送到Kafka进行处理。在这种情况下,订单消息的关键信息是订单ID,你希望具有相同订单ID的消息被写入到同一个分区,以维护订单消息的有序性。
示例:
输出:
- 订单消息1被写入分区2
- 订单消息2被写入分区1
- 订单消息3被写入分区2
性能测试:
自定义分区策略通常在维护消息的有序性方面表现出色。吞吐量仍然取决于Kafka集群的性能和生产者的配置,但在这个示例中,重点是保持订单消息的顺序性。
这两个示例展示了不同分区策略的应用和性能表现。根据你的特定需求,你可以选择适当的分区策略以满足业务要求。
以上内容详细介绍了示例,包括Round-Robin策略和自定义分区策略的实际应用。示例代码和性能测试结果将有助于更好地理解这些策略的使用方式。
六、总结
在文章中,我们深入探讨了Kafka主题的分区策略,这是Kafka消息传递系统的核心组成部分。我们从基础知识入手,了解了分区策略的基本概念,为什么它重要,以及它如何影响Kafka集群的性能和数据的顺序性。
首先介绍了Kafka默认的分区策略,即Round-Robin策略,它将消息均匀分配到各个分区。
通过示例,我们展示了Round-Robin策略的应用场景和性能特点,然后,深入研究了如何编写自定义分区策略。我们提供了示例代码,演示了如何根据消息的键来选择分区,以满足特定需求。
我们还分享了一些建议,帮助你选择适当的分区策略,并进行性能测试和评估。在分区策略的性能考量中,讨论了数据均衡、高吞吐量和顺序性等关键因素。提供了性能优化的策略和示例代码,以帮助你优化分区策略的性能。