












PDF文件具有跨平台的特点,可以在不同的操作系统和设备上保持一致的显示效果。但是,PDF文件也有一些缺点,比如不易编辑、复制和搜索。如果我们想要从PDF文件中提取文本内容,该怎么办呢?
在本教程中,我们将介绍如何使用Python中的PyPDF2库来提取PDF文件中的内嵌文字内容。PyPDF2是一个纯Python的库,可以读取、分割、合并、裁剪和转换PDF文件。它不需要安装任何其他的依赖库,也不需要调用外部的程序或服务。
安装PyPDF2库
要使用PyPDF2库,我们首先需要安装它。我们可以使用pip命令来安装,如下所示:
pip install PyPDF2如果安装成功,我们可以在Python中导入PyPDF2模块,如下所示:
import PyPDF2读取PDF文件
要从PDF文件中提取文本内容,我们首先需要读取PDF文件。我们可以使用PyPDF2.PdfReader类来创建一个PDF文件的读取对象,然后传入一个文件对象或一个文件路径作为参数。例如,假设我们有一个名为sample.pdf的PDF文件,我们可以用以下代码来读取它:
# 通过文件对象来读取
with open("sample.pdf", "rb") as f: # 以二进制模式打开文件
reader = PyPDF2.PdfReader(f) # 创建一个PdfFileReader对象
# 通过文件路径来读取
reader = PyPDF2.PdfReader("sample.pdf") # 创建一个PdfFileReader对象注意,我们必须以二进制模式("rb")来打开PDF文件,否则会出现错误。
获取PDF文件的基本信息
在读取了PDF文件之后,我们可以使用PdfReader对象的一些属性和方法来获取PDF文件的基本信息,例如页数、作者、标题等。例如:
# 获取页数
num_pages = len(reader.pages) # 返回一个整数,表示PDF文件的总页数
print(f"该PDF文件共有{num_pages}页")
# 获取作者
author = reader.metadata.author # 返回一个字符串,表示PDF文件的作者信息
print(f"该PDF文件的作者是{author}")
# 获取标题
title = reader.metadata.title # 返回一个字符串,表示PDF文件的标题信息
print(f"该PDF文件的标题是{title}")提取单页文本内容
要从单页中提取文本内容,我们可以使用PdfReader对象的pages来获取指定页码的页面对象(PyPDF2.pdf.PageObject类),然后使用页面对象的extract_text()方法来获取页面中的文本内容。例如:
# 获取第一页的页面对象
page1 = reader.pages[0]# 传入一个整数作为参数,表示页码(从0开始)
# 提取第一页的文本内容
text1 = page1.extract_text() # 返回一个字符串,表示页面中的文本内容
# 打印第一页的文本内容
print(text1)注意,extract_text()方法只能提取内嵌文字内容,不能提取图像或其他元素。另外,提取出来的文本内容可能不完全符合原始格式,可能存在换行、空格、缺失等问题。
提取多页文本内容
要从多页中提取文本内容,我们可以使用一个循环来遍历PdfReader对象的每一页,然后使用extract_text()方法来获取每一页的文本内容,并将它们拼接成一个完整的字符串。例如:
# 创建一个空字符串,用于存储所有页面的文本内容
text = ""
# 遍历每一页
for i in range(num_pages):
# 获取当前页的页面对象
page = reader.pages[i]
# 提取当前页的文本内容
page_text = page.extract_text()
# 将当前页的文本内容添加到总字符串中
text += page_text
# 打印所有页面的文本内容
print(text)保存提取的文本内容
提取了PDF文件中的文本内容之后,我们可以将它保存到一个文本文件中,以便后续的处理或分析。我们可以使用Python的内置函数open()来创建一个文本文件对象,然后使用write()方法来写入提取的文本内容。例如:
# 创建一个名为output.txt的文本文件对象,以写入模式打开
with open("output.txt", "w", encoding="utf-8") as f: # 指定编码为utf-8,避免乱码
# 将提取的文本内容写入到文件中
f.write(text)注意,我们需要指定编码为utf-8,以避免出现乱码。
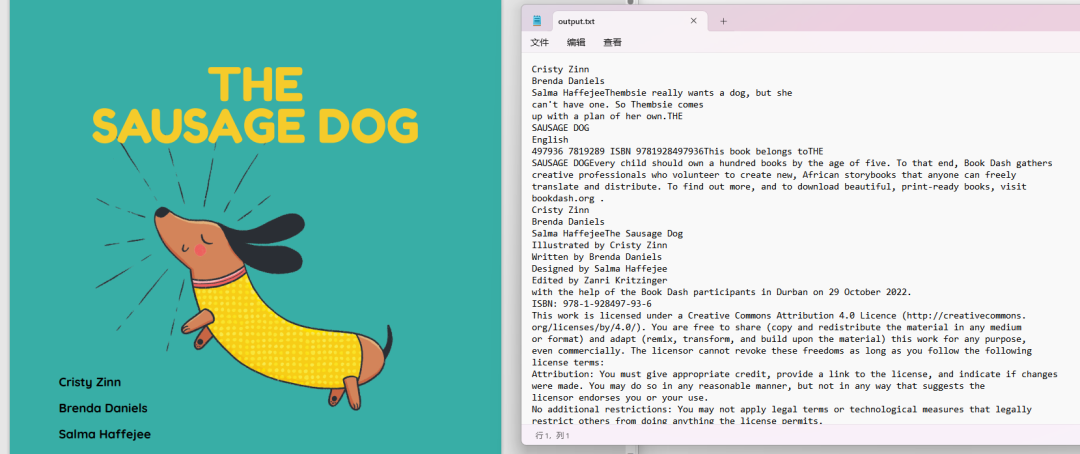
如下是:sample.pdf和output.txt文件的部分截图
总结
在本教程中,我们介绍了如何使用Python中的PyPDF2库来提取PDF文件中的内嵌文字内容。我们首先安装了PyPDF2库,并导入了PyPDF2模块。然后,我们使用PyPDF2.PdfReader类来读取PDF文件,并获取了PDF文件的基本信息。接着,我们使用pages和extract_text()方法来提取单页或多页的文本内容,并将它们保存到一个文本文件中。通过这些操作,我们可以实现Python自动化办公的一个功能,即从PDF文件中提取文本内容。




















