译者 | 朱先忠
审校 | 重楼
简介
在一款完美的信息类游戏中,如果你所需要的一切都能够让每一个玩家在游戏规则中看到,这不是一件很神奇的事情吗?
但遗憾的是,对于像我这样的普通玩家来说,阅读有关一款新游戏的玩法规则只是学习玩复杂游戏旅程中的一小部分,而大部分时间都花在玩游戏当中,当然最好是与实力相当的玩家(或者有足够耐心帮助我们暴露弱点的更好些的玩家)比赛。经常输掉游戏和希望获胜有时会带来一定的心理惩罚和奖励,不过这将引导我们逐渐把游戏玩得更好。
也许,在不久的将来,AI语言模型能够读取类似于国际象棋这样的复杂游戏的规则,并从一开始就尽可能达到最高水平。与此同时,我提出了一种更温和的挑战方式——通过自我游戏学习。
在本文提供的这个实战项目中,我们将训练一个AI助理,它能够通过观察以前版本的游戏结果来学习玩完美信息的双人游戏。其中,AI助理负责近似化此游戏状态的任何数值(游戏预期结果)。作为一个额外的挑战,我们的AI助理将不被允许维护状态空间的查找表,因为这种方法对于复杂的游戏来说是不可管理的。
求解SumTo100游戏
游戏规则简介
我们要讨论的游戏是SumTo100。此游戏的目标是通过对1到10之间的数字进行加法运算来达到100的总和。以下是此游戏遵循的规则:
- 初始化总和为0。
- 选择第一个玩家;两名选手轮流上场。
- 当总和小于100时:
- 玩家选择一个介于1和10之间的数字(包括1和10)。所选数字将添加到总和中,但不超过100。
- 如果总和小于100,则另一个玩家进行游戏(即,我们回到第3步的开始处)。
- 加上最后一个数字(达到100)的玩家获胜。

两只蜗牛自顾自的样子(作者本人图片,基于OpenAI推出的第二代图像生成式人工智能模型DALL-E2制作)
我们选择从这样一款简单的游戏开始,这样的做法存在很多优点:
- 状态空间只有101个可能的值。
- 这些状态可以绘制在1D网格上。这种特性将使我们能够将AI助理学习的状态值函数很容易表示为1D条形图。
- 最佳策略是已知的:-求和为11n+1,其中n∈{0,1,2,…,9}于是,我们可以很容易地对游戏中最优策略的状态值进行可视化展示:
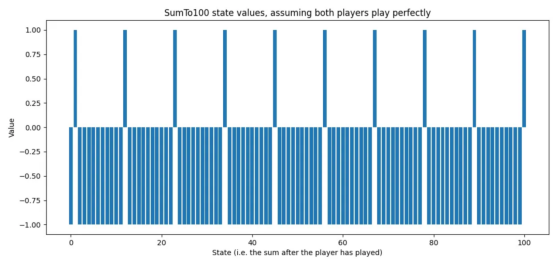 图1:SumTo100游戏的最佳状态值(作者本人的图片)
图1:SumTo100游戏的最佳状态值(作者本人的图片)
此图中,游戏状态为AI助理完成其回合后的总和。值为1.0意味着,AI助理肯定会赢(或已经赢);而值为-1.0意味着AI助理一定会输(假设对手发挥最佳);中间值表示估计的回报值。例如,状态值为0.2表示略微正的状态,而状态值为-0.8表示可能的损失。
如果您想对代码进行深入研究,那么执行整个训练过程的脚本就是learn_sumTo100.sh,对应的开源存储库地址是https://github.com/sebastiengilbert73/tutorial_learnbyplay。如果感觉不必要,那么请耐心等待,因为接下来我们将对AI助理如何通过自我游戏学习进行详细的描述。
生成随机玩家玩的游戏
我们希望我们的AI助理能够从以前版本的游戏中学习。但是,在游戏第一次迭代中,由于AI助理还没有学到任何东西;所以,我们将不得不模拟随机玩家玩的游戏。在每一个回合中,玩家都会从游戏管理库(即编写游戏规则的类)获得当前游戏状态下的合法动作列表。随机玩家将从该列表中随机选择一次移动。
图2展示了两个随机玩家玩游戏的示例:
 图2:随机玩家玩的游戏示例(作者本人的图片)
图2:随机玩家玩的游戏示例(作者本人的图片)
在这种情况下,第二个玩家通过达到100的总和赢得了游戏。
现在,我们来实现一个可以访问神经网络的AI助理,该神经网络将游戏状态(在助理玩过之后)作为输入,并输出该游戏的预期回报值。对于任何给定的状态(在助理进行游戏之前),助理都会获得有效动作的列表及其相应的候选状态(我们只考虑具有确定性转换的游戏)。
图3显示了AI助理、对手(其移动选择机制是未知的)和游戏状态管理库之间的互动:
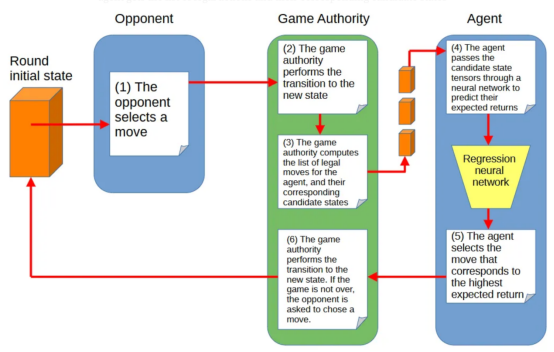 图3:AI助理、对手和游戏管理库之间的交互(作者本人的图片)
图3:AI助理、对手和游戏管理库之间的交互(作者本人的图片)
在这种设置中,AI助理依靠其回归神经网络来预测游戏状态的预期回报值。神经网络越能预测哪一个候选移动产生最高回报值,助理就越能发挥其作用。
我们的随机玩法列表将为我们提供第一次训练的数据集。以图2中的示例游戏为例,我们想惩罚玩家1的动作,因为它的动作导致了失败。最后一个动作产生的状态值为-1.0,因为它允许对手获胜。其他状态通过γᵈ因子得到负值折扣。其中,d是相对于助理到达的最后状态的距离;γ代表折扣因子,这个数范转是[0,1],它表达了游戏进化中的不确定性:我们不想与最后一个决策那样严厉地惩罚早期的决策。图4显示了与玩家1所做决策相关的状态值:
 图4:从玩家1的角度来看的状态值列表(作者本人的图片)
图4:从玩家1的角度来看的状态值列表(作者本人的图片)
随机游戏生成具有目标预期回报的状态。例如,达到97的和时将对应值为-1.0的目标预期回报,而达到73的和时则对应于值为-γ³的目标预期收益。一半的状态从玩家1的角度出发,另一半从玩家2的角度出发(尽管在SumTo100游戏中这并不重要)。当一场比赛以AI助理获胜的结果结束时,相应的状态会得到类似的折扣正值。
训练AI代理以便预测比赛的结果
现在,我们准备好了开始训练所需的一切:一个神经网络(我们将使用两层感知器)和一个(状态,预期回报)数据对的数据集。接下来,让我们看看预测预期回报值的损失是如何演变的:
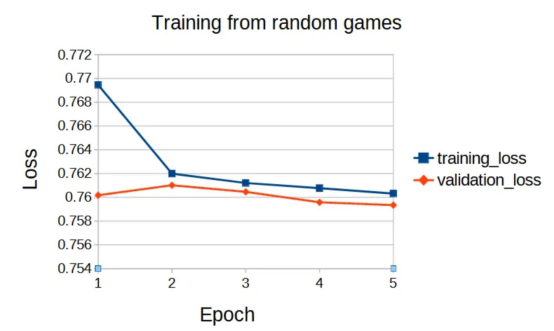 图5:损失值随训练轮次的变化情况(作者本人的图片)
图5:损失值随训练轮次的变化情况(作者本人的图片)
我们不应该感到惊讶的是,神经网络对随机玩家玩游戏的结果没有表现出太大的预测能力。
那么,神经网络到底学到了什么吗?
幸运的是,由于状态可以表示为0到100之间的1D数字网格;因此,我们可以绘制第一轮训练后神经网络的预测回报,并将其与图1中的最佳状态值进行比较:
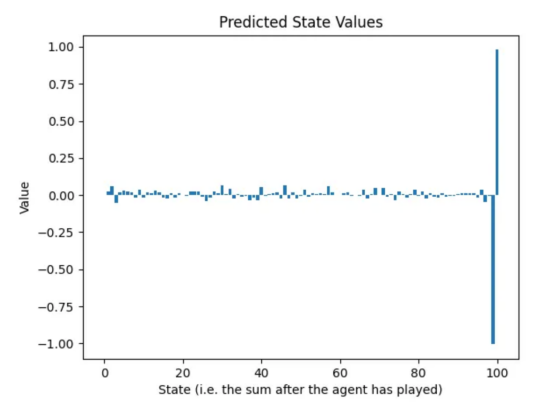 图6:在随机玩家玩的游戏数据集上训练后的预测回报(作者本人的图片)
图6:在随机玩家玩的游戏数据集上训练后的预测回报(作者本人的图片)
上述事实证明,通过随机游戏的混乱状态操作,神经网络学到了两件事:
- 如果你能达到100,就去做吧。考虑到这是比赛的目标,知道这一点很好。
- 如果你达到99,你肯定会输。事实上,在这种情况下,对手只有一次有效动作,而这一动作会给AI助理带来损失。至此,神经网络基本上学会了完成游戏。
为了学会更好地发挥作用,我们必须通过使用新训练的神经网络模拟AI助理副本之间的游戏来重建数据集。为了避免生成相同的游戏,玩家会随机玩一点。一种行之有效的方法是使用ε贪婪算法选择动作,每个玩家的第一个动作使用ε=0.5,然后在游戏的其余部分使用ε=0.1。
与越来越好的玩家一起重复训练循环
既然两名玩家现在都知道他们必须达到100,那么达到90到99之间的总和应该受到惩罚,因为对手会抓住机会赢得比赛。这种现象在第二轮训练后的预测状态值中是可见的:
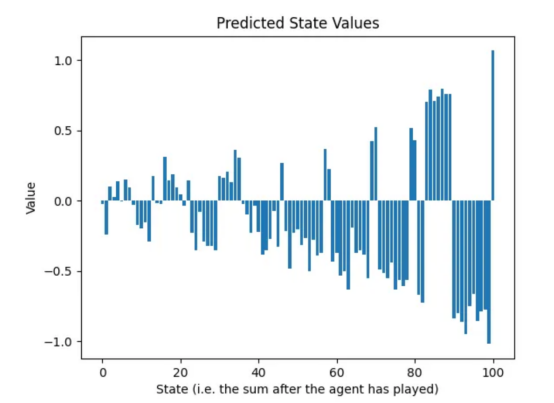 图7:两轮训练后的预测状态值:从90到99的总和显示的值接近-1(作者本人的图片)
图7:两轮训练后的预测状态值:从90到99的总和显示的值接近-1(作者本人的图片)
我们看到正在出现一种规律:第一轮训练通知神经网络关于最后一个动作;第二轮训练通知倒数第二个动作,等等。我们需要重复游戏生成和预测训练的循环,至少与游戏中的动作有一样多的次数。
以下图片显示了第25轮训练后预测状态值的演变情形:
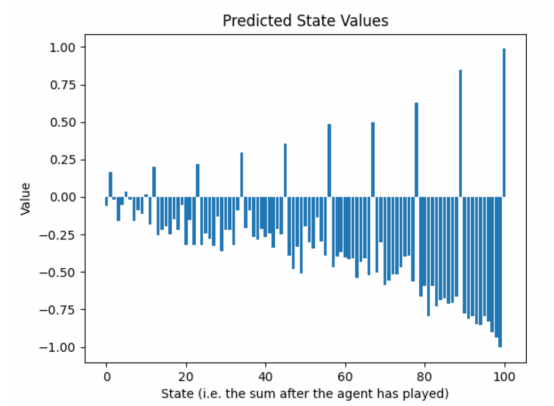 图8:训练过程中学习到的状态值的瞬时截图(作者本人的图片)
图8:训练过程中学习到的状态值的瞬时截图(作者本人的图片)
当我们从游戏的结束走向开始时,预测回报的包络线指标值呈指数衰减。这是个问题吗?
造成这种现象的因素有两个:
- 当我们远离比赛结束时,γ直接降低了目标的预期回报。
- ε贪婪算法在玩家动作中注入了随机性,使结果更难预测。有动机预测接近零的值,以防止出现极高损失的情况。然而,随机性是可取的,因为我们不希望神经网络学习单一的游戏。我们希望神经网络能够见证AI助理和对手的失误和意想不到的好动作。
在实际情况中,这应该不是一个问题,因为在任何情况下,我们都会比较给定状态下的有效动作的值,这些动作具有可比的规模,至少在SumTo100游戏中是这样。当我们选择使用贪婪法移动时,数值的规模并不重要。
结论
本文中我们成功实现了对自己的挑战——开发了一个AI助理,它可以学习掌握一个涉及两个玩家的完美信息游戏,并能够实现在给定一个动作的情况下,从一个状态到下一个状态的确定性转换。实现过程中,不允许使用任何手动编码的策略或战术——一切都必须通过自我游戏来学习。
我们可以通过运行AI助理的多轮参赛副本来解决SumTo100的简单游戏,并训练一个回归神经网络来预测生成游戏的预期回报。
最后,通过此项实验所得的收获为我们研究更复杂的游戏做好了准备,但这将是我的下一篇文章的主要内容!
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Training an Agent to Master a Simple Game Through Self-Play,作者:Sébastien Gilbert