













推荐系统在深度学习和图神经网络的影响下已经取得了重大进步,尤其擅长于捕捉复杂的用户-物品关系。
然而,现有基于图神经网络(GNNs)的推荐算法普遍仅依赖于ID数据构造的结构化拓扑信息,导致其大量存在于推荐数据集中与用户和物品相关的原始文本数据,因此,其学习到的表示不够信息丰富。
此外,协同过滤中运用到的隐式反馈(Implicit Feedback)数据存在有潜在的噪声和偏差,其对深度模型在用户偏好学习的有效性也提出了挑战。
目前,如何将大语言模型(LLMs)与传统的基于ID数据的推荐算法相互结合,已经受到了学界以及工业界的广泛关注。但是,仍然存在有许多困难,例如算法的可扩展性,语言模型的输入限制(仅文本模态以及输入长度限制),使其大语言模型无法在实际运用的推荐系统中有效提供帮助。
为了应对这些限制,来自香港大学等机构的研究人员提出了一种利用大语言模型来促进现有推荐算法表征学习的框架RLMRec,并且在实验中将其与现有的最先进的推荐算法相结合,在真实数据集中进一步提升了算法的推荐性能。

论文地址:https://arxiv.org/abs/2310.15950
代码地址:https://github.com/HKUDS/RLMRec
具体而言,该范式通过利用大语言模型从文本角度挖掘用户行为偏好以及商品语义特征,并且利用最大化互信息的方式将文本信号和来自于图神经网络的协同信号增强对齐,从而有效促进算法学习到的表征质量。
基于RLMRec,我们分别基于了对比式学习和生成式学习构建了RLMRec-Con和RLMRec-Gen两套范式。这两套范式在不同的测试场景下展现出了不同的优点,因此可以灵活的运用于不同的实际场景。
理论角度缓解协同信号中的噪声
在基于图神经网络的协同过滤推荐算法中,其基于协同信号,会为每一个用户/商品学习到一个表征。
我们称之为基于协同信号的表征,从用户的角度,其反应了用户对于商品的偏好;从商品的角度,其反应了它吸引的用户群体。然而,由于协同信号中可能存在的噪声(例如误点击、流行度偏差等等),表征中不可避免的受到了噪声(noise)的影响。
我们不妨设在推荐的视角下,对推荐存粹有益的潜在信号为,那么表征则同时由与潜在噪声生成。考虑到协同数据中并不存在文本语义信息,因此在本文中,我们将其作为突破口,考虑利用文本语义信号(semantic information)来缓解这一现象。
我们不妨设对于每一个用户/商品,我们都拥有一个基于文本语义而产生的表征,其基于的原始文本本身能够准确地反应了用户喜好的商品类别,和商品所吸引的用户群体,因此中也包含了来自于潜在信号的信息,但是同时也包括了一些与推荐无关的信号(例如表征中可能体现的语法等语言属性)。因此我们可以构建如下的概率图模型。

为了能够提高协同过滤算法所学习到的表征e的质量,我们构建的如下的学习目标

直观上将,我们希望能够最大化协同信号表征e与文本信号表征s以及潜在信号z直接的关联,从而使得表征e中包含更多有益的信息以增强推荐的性能。
通过理论推导,最大化上述目标等价于最大化表征e和表征s之间的互信息I(e, s),并且最终可以转换成优化如下目标

其中f是密度函数,体现了二者的相似程度。上述的表征学习过程可以形象化地体现为如下过程:

在优化的过程中,我们不断增加协同信号表征e与文本信号表征s中重叠的部分,从而不断的减少噪声在协同信号表征中的占比,从而获得高质量的特征学习结果,以促进推荐性能提高。
为了真正实现上述的理论推导后的优化目标,我们仍然有两点挑战:
1. 如何通过文本有效的用户/商品真实的交互偏好以获得高质量的文本语义表征;
2. 如何实现密度函数f从而高效地优化我们的学习目标。
我们将在接下来的两节中分别阐述如何解决上述这两点挑战。
准确提炼用户/商品文本画像
为了获得文本信号表征,我们首先需要拥有文本模态上对于用户和商品的准确画像描述,其需要是无偏差的,从而能够反应出用户和商品真实的偏好。我们希望用户画像能够有效的反应出其喜好什么类别的商品,并且商品画像能够反应出其会吸引什么样的用户群体。
在真实的推荐数据集中(例如Yelp、Amazon-book)存在有许多的对于原始文本数据,例如商品描述、用户评论等等,但是这些原始文本数据同样存在这大量的噪音,例如在Steam数据集中,玩家对于电子游戏的评论会存在有大量的非语义符号。
噪音的存在使得我们在以往难以利用上这些文本数据。幸运的是,随着大语言模型的发展,其高效的文本总结能力和自然语言处理能力是我们能够达成这一目标。
在本节中,我们基于大语言模型(LLMs)和思维链(Chain-of-Thought)的思想,提出了一种从商品到用户的文本画像构建路径。其能够保证在现有的数据下,准确无误无偏的反应出用户和商品的交互偏好,以便于我们获得高质量的文本语义表征。
简单来说,我们先基于用户的反馈或是商品的自身描述,基于大语言模型的知识先对商品的画像进行总结,并且要求其提供思考的过程,基于此,我们可以首先获得基于商品的无偏文本画像。
其次我们将用户对商品的反馈以及商品文本画像相结合,输入给大语言模型,使其总结用户画像,因为用户的反馈中包含了用户的真实喜好,因此语言模型能够准确的把握住用户的真实喜好,从而产生准确的文本画像。
最后,我们利用先进的文本嵌入模型将文本画像转化为文本表征表征,上述过程的示意图如下(在论文的附录中,我们对生成过程进行了具体的案例描述)

对比式/生成式建模密度函数
密度函数的输出是一个实数,反应了输入的两个表征的之间的相似程度。对于该函数的建模越有效越精确,就可以更好的实现互信息最大化,从而实现协同信号表征和文本语义信号表征之间的对齐。
在本文中我们考虑两种不同的建模方法,从而实现了两种不同的对齐方式。
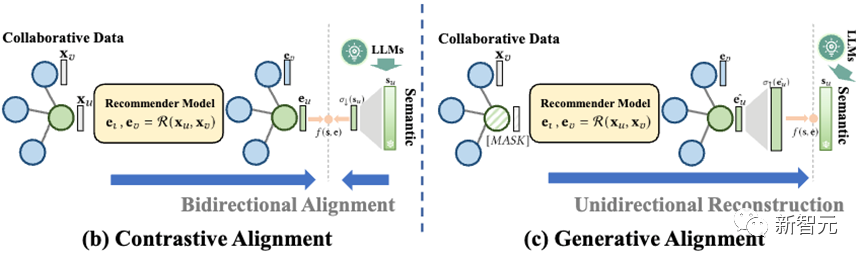
第一种是对比式对齐(Contrastive Alignment,RLMRec-Con),其具体建模形式如下

简单来说,我们将文本语义表征通过网络进行缩放,使其与协同信号表征具有相同的维度,而后用余弦相似度来计算它们之间的相似程度。
结合之前的优化函数,实际上这与对比学习的过程十分相似,因此我们称之为对比式对齐。形象化的来说,在该过程中,两个表征双向奔赴,不断互相对齐彼此。
第二种是生成式对齐(Generative Alignment,RLMRec-Gen),其具体形式如下
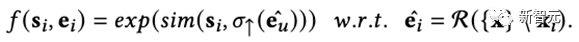
简单来说,我们是基于生成式掩膜子编码器(Generative Masked Auto-encoder)的思想,将部分节点的原始特征进行掩盖,然后将推荐算法编码出来的这些节点的特征进行缩放,使其具有和文本语义表征相同的维度,而后进行对齐。
形象化的来说,在该过程中,协同表征向文本语义表征单向逼近,生成式地重构对方,从而实现对齐。
我们在后续的实验过程中,探寻了两种方法(RLMRec-Con和RLMRec-Gen)在不同的场景下的优势。
实验验证
我们在三个公开数据集(Yelp,Amazon-book,Steam)上,使用现有的先进协同过滤算法(GCCF、LightGCN、SGL、SimGCL、DCCF和AutoCF)作为基准模型,配合RLMRec进行了性能的验证。通过多次随机试验求均值,我们发现RLMRec可以有效且显著地进一步提升现有推荐算法的性能。
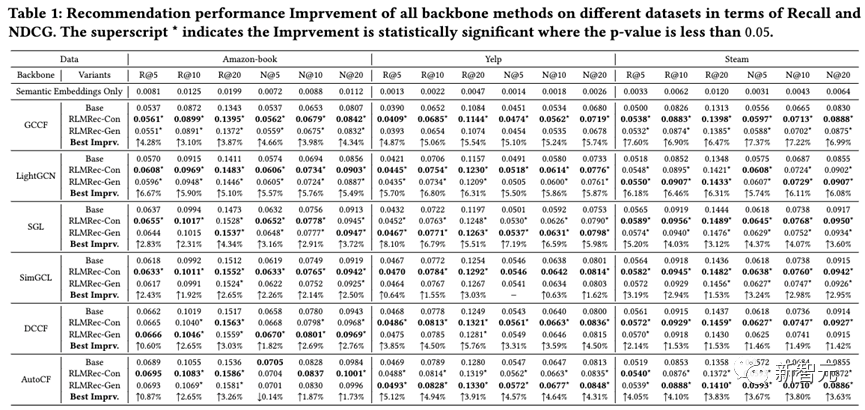
从结果中可以看出。对比式学习(RLMRec-Con)所带来的性能提升,相较于生成式学习(RLMRec-Gen)更加显著,但是对于自身就是生成式建模的推荐算法(AutoCF)而言,生成式学习带来的性能提升更多,由此可见使用两种方式需要应算法而制宜。
进一步的,为了探寻是否真的是文本信号的引入提高了推荐的性能(而非是框架的设计),我们将用户/商品的协同信号和文本信号之间的对应关系进行了打乱(Shuffle),从而造成错误的信号对应关系,并进行了性能试验如下
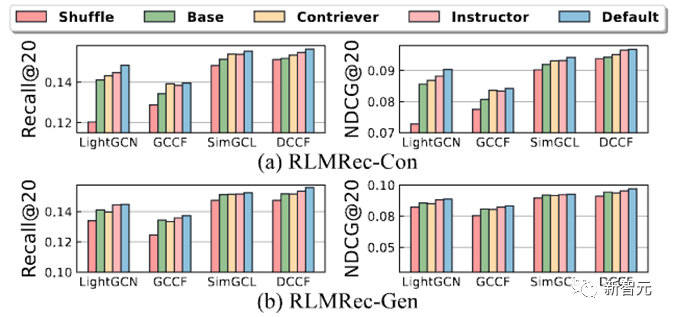
从结果中可以看出,在打乱了信号对应关系中,错误的文本语义的引入会导致表征学习无法正常进行,即协同信号表征无法有效的向语义表征逼近(停留在原地),因此性能相对显著下降。
同时我们也利用了不同的语义嵌入模型(Instructor、Contriever)来生成语义表征,我们发现越好的语义嵌入模型生成的语义表征能够更好的增益RLMRec。
其次,我们进行了噪音试验,通过随机加上不同程度的噪声,来探讨RLMRec对噪声的抵抗能力,结果如下
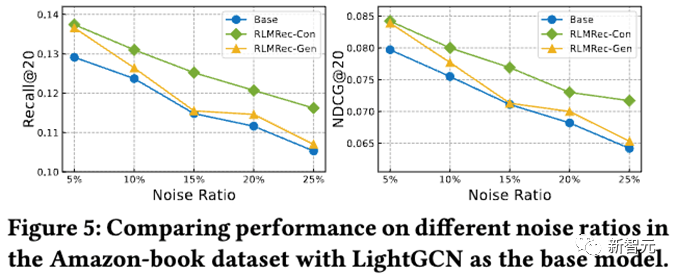
从结果中可以看出,不论在什么程度的噪声下,在RLMRec框架下训练获得的表征能够相对于基线模型有更好的性能,同时对比式对齐能够抵御噪声的能力更强,我们认为这是因为生产式对齐由于存在有掩膜(Mask)的操作,在特征层面上已经引入了一部分噪声,因此应对结构化噪声的能力有所下降,不过相对于基线模型,都是有增益的。
进一步的,我们探讨了RLMRec的两种范式能否应用于预训练(Pre-training)。基于此,我们将Yelp数据集中从2012-2017年的数据作为预训练数据,2018-2019年的数据作为微调(fine-tune)数据,并最终测试性能,结果如下
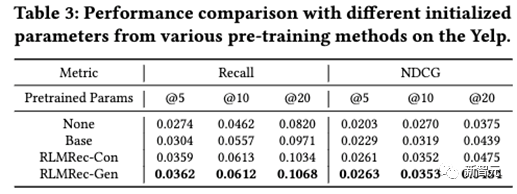
从结果中我们发现,在预训练的场景下,生成式对齐RLMRec-Gen一致的具有更优的性能,我们认为这是因为通过生成式建模中的掩膜(Mask)操作,能够有效防止过拟合,从而构成一种约束,因此所获的的参数能够有效迁移至新的数据上,这也与近年来通过生成式预训练语言模型的范式不谋而合。
最后,我们进行了样例研究(Case Study)

我们针对一个用户计算了与其距离较远(在Graph上大于3跳)的所有用户的特征相似度,并且基于此从高到低排序。
我们发现即使是两个用户拥有相同的偏好,但是传统的推荐算法获得的表征,无法有效的体现出他们之间的相似性,这是因为他们的距离大于图网络的层数,因此无法互相监督。
通过在RLMRec中引入了文本信号信息,具有相同偏好的用户表征被有效的拉近,从而他们的表征相似度也得到了提高,这从一定程度上说明通过引入文本信号来优化用户/商品表征学习,能够从全局的视角对具有相似偏好的用户/商品进行有益的对齐,从而提高表征学习的质量最终提高推荐性能。
结语
在本文中我们提出了一种模型无关的基于大语言模型的推荐系统表征学习范式,通过合理的设计,利用大语言模型从海量原始文本数据中挖掘的纯净的文本语义信号,从而对协同信号表征进行优化,最终促进的最先进推荐算法性能的提升。
我们在GitHub上对数据集和代码进行了开源,希望我们清洗后的具有文本标注的推荐数据集以及所提出的范式RLMRec能够促进大语言模型和推荐系统的进一步融合。
最后,其实RLMRec的思想不单单能运用在推荐算法中,我们也在别的场景下进行了实践,在百度的搜索算法框架下,我们将RLMRec中的对比式对齐的思想进行了测试,在搜索推荐的精度上也获得了有益的提升,实现了算法的有效落地。




























