大语言模型在各类 NLP 下游任务上都取得了显著进展,各种垂直领域大模型更是如雨后春笋般层出不穷。然而在 DevOps 领域,却迟迟没有相关大模型问世。为填补这方面的空白,蚂蚁集团联合北京大学发布了面向中文 DevOps 领域的首个开源大语言模型,即 DevOps-Model 。
该大模型旨在帮助开发人员在软件开发和运维的整个生命周期中提高效率,最终目标是实现在 DevOps 流程中面临任何问题时,都可以通过向 DevOps-Model 提问来获取解决方案!
当前已经开源了 7B 和 14B 两种规格的 Base 和 Chat 模型,同时还开源了对应的训练代码。
此外,为了有效评估 DevOps 领域大模型的性能,我们同时发布了首个面向 DevOps 领域的大模型评测基准 DevOps-Eval。该评测基准根据 DevOps 全流程进行划分,包含计划、编码、构建、测试、发布、部署、运维和监控这 8 个类别,包含 4850 道选择题。
此外,DevOps-Eval 还特别对运维 / 监控类别做了细分,添加日志解析、时序异常检测、时序分类和根因分析等常见的 AIOps 任务。由于 DevOps-Eval 根据场景对评测样本做了详尽的细分,因此除了 DevOps 领域大模型,也方便对特定领域大模型进行评测,如 AIOps 领域等。
目前,第一期 DevOps 领域模型的评测榜单已发布,除 DevOps-Model 外,还包含 Qwen、Baichuan、Internlm 等开源大语言模型;同时,DevOps-Model 和 DevOps-Eval 相关论文也在撰写中。欢迎相关从业者一起来进行共建、优化 DevOps 领域大模型和评测题目,我们也会定期更新模型、题库和评测榜单。
DevOps-Model
- Github 地址:https://github.com/codefuse-ai/CodeFuse-DevOps-Model/tree/main
- 模型地址:
- 7B 版本
https://modelscope.cn/models/codefuse-ai/CodeFuse-DevOps-Model-7B-Base/summary
https://modelscope.cn/models/codefuse-ai/CodeFuse-DevOps-Model-7B-Chat/summary - 14B 版本
- https://modelscope.cn/models/codefuse-ai/CodeFuse-DevOps-Model-14B-Base/summaryhttps://modelscope.cn/models/codefuse-ai/CodeFuse-DevOps-Model-14B-Chat/summary
DevOps-Eval
- GitHub 地址:https://github.com/codefuse-ai/codefuse-devops-eval
- HuggingFace 地址:https://huggingface.co/datasets/codefuse-admin/devopseval-exam
DevOps-Model 的构建过程
基座模型
在基础通用模型选择上,我们考量了模型训练数据大小、模型能力、模型参数量级后,最终选择的是 Qwen-7B 和 Qwen-14B 作为通用模型。因为在公开的一些评测榜单上,Qwen 系列模型基本属于同参数量级下效果最好的模型。
同时预训练的语料有达到 3T token 的量级,可以给基座模型带来更为全面的知识。
训练框架
训练框架上,我们采用的是基于开源训练库 LLaMA-Factory 加以改造来进行训练,训练时通过 flash-attention、ZeRO、混合精度等技术来保障高效训练。
整体的 Qwen 模型架构是在 LLaMA 的结构上做了一些优化,其中包含采用了 RoPE 作为位置编码的方式来提高模型的外推能力,采用了 RMSNorm 来提高训练稳定性,采用 SwiGLU 激活函数来提高模型的表现。
训练流程
根据查阅文献可知,大部分领域模型都是在对话模型的基础上,通过 SFT 微调来进行知识注入。而 SFT 微调所需要 QA 语料基本都来自于 ChatGPT 生成。然而,该方案可能存在 QA 语料无法完全覆盖领域知识的情况。
因此,DevOps-Model 采用的是预训练加训 + SFT 微调的方案,如下图所示。我们认为针对领域大模型,预训练的加训是必要的,因为其可以将领域内的一些知识在预训练阶段注入到大模型。
如果这些知识在通用大模型预训练时没有出现过,那会让大模型学习到新的知识;如果出现过,就可以让大模型进一步加深印象。第二步则是大模型对齐,目的是让大模型可以根据问题来回答最合适的内容。
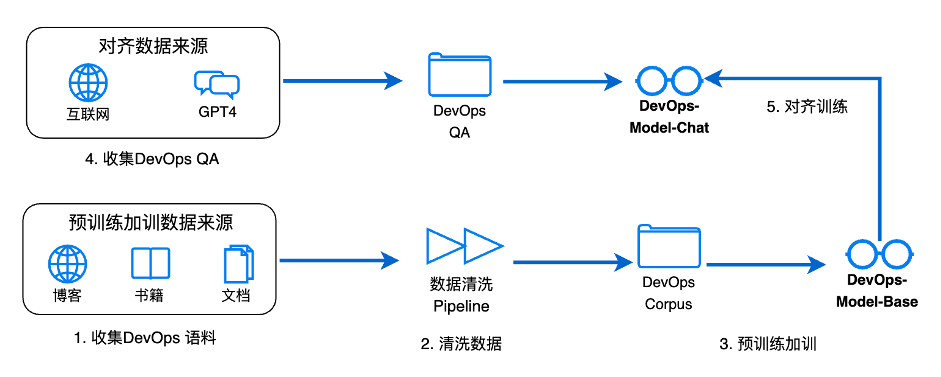
图1. DevOps-Model 训练流程
训练数据
- 数据收集
模型的定位是中文 DevOps 领域大模型,因此需要收集与中文 DevOps 相关的预训练数据和 QA 数据。
预训练数据主要来自互联网技术博客、技术文档、技术书籍等,最终收集到了 50G+ 的预训练语料数据;
针对 QA 数据,我们的目标是想让模型不仅能够对齐到通用的问答能力,针对 DevOps 领域也可以学会如何更好的回答问题,因此不但收集了通用领域的单轮和多轮对话数据,还针对 DevOps 领域,通过爬取和 ChatGPT 生成的方式产出了属于 DevOps 领域的问答数据。最终我们精心筛选了约 200K 的 QA 数据进行 SFT 微调训练,具体数据量如下表所示。

- 数据筛选
由于预训练数据大部分是从互联网上收集的数据,质量参差不齐,而大模型训练中数据是最重要的一环,我们建立了如下图所示的清洗 Pipeline,全面过滤收集到的数据。

图2. DevOps-Model 预训练数据清洗 Pipeline
1) 首先,由专家经验和人工筛选,总结出来了一批文档级别的 Heuristic 过滤规则,这一步主要用来过滤掉那些质量非常差的文档;
2) 其次,即便是一篇质量稍差的文章,也有可能含有有价值的领域知识,也需要尽可能的进行收集。此处,我们对文章进行段落拆分,将文章拆分成一个个段落;
3) 然后,我们将拆分后的段落会再次通过步骤 1 进行过滤,便得到了一批经过规则过滤后的段落;
4) 再摘取其中 1000 个段落,由经验丰富的专业开发人员打标,获得高质量的打标数据;
5) 最后,根据打标后的结果来训练了一个打分模型来针对段落进行质量的打分,段落的向量模型选用了预训练好的中文版本的 Sentence-Bert,打分算法选用了逻辑回归,为了避免打分模型的误差,会再通过帕累托分布来根据段落的质量打分进行采样来决定是否过滤这个段落。
经过这个 Pipeline 后,最终沉淀下 15G 左右的数据来进行大模型的预训练加训。
模型使用
DevOps-Model 的使用可以参考如下流程使用,更详细的信息请参考 Github。
- 模型下载:
从 https://github.com/codefuse-ai/CodeFuse-DevOps-Model/tree/main 找到自己想要下载的 Chat 模型版本,当前提供了 7B 和 14B 的模型;
- 模型交互:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("path_to_DevOps-Model-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("path_to_DevOps-Model-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 指定 generation_config
model.generation_config = GenerationConfig.from_pretrained("path_to_DevOps-Model-Chat", trust_remote_code=True)
# 第一轮对话
resp, hist = model.chat(query='你是谁', tokenizer=tokenizer, history=None)
print(resp)
# 我是 DevOps-Model,一个由蚂蚁集团平台技术事业群风险智能团队和北京大学联合研发的人工智能机器人,可以与用户进行自然语言交互,并协助解答 DevOps 全生命周期中的各种问题。如果您有任何需要协助的问题或者想要进行闲聊,都可以和我交流哦。
# 第二轮对话
resp2, hist2 = model.chat(query='Java 中 HashMap 和 Hashtable 有什么区别', tokenizer=tokenizer, history=hist)
print(resp2)
# HashMap 和 Hashtable 都是 Java 中常用的哈希表实现,它们的主要区别在于:
# 1. Hashtable 是线程安全的,而 HashMap 不是线程安全的,因此在多线程环境下,Hashtable 的性能更稳定。
# 2. Hashtable 中的方法都是同步的,而 HashMap 的方法不是同步的,因此在多线程环境下,Hashtable 的性能更好。
# 3. Hashtable 中的 key 和 value 都必须实现 Serializable 接口,而 HashMap 中的 key 和 value 可以是任何对象,包括基本数据类型。
# 4. Hashtable 的初始容量是 11,而 HashMap 的初始容量是 16。
# 总之,如果需要在多线程环境下使用哈希表,并且需要保证线程安全,那么应该使用 Hashtable;如果不需要考虑线程安全,或者需要快速地进行哈希表操作,那么应该使用 HashMap。
# 第三轮对话
resp3, hist3 = model.chat(query='线程安全代表什么', tokenizer=tokenizer, history=hist2)
print(resp3)
# 线程安全是指在多线程环境下,程序能够正确地处理并发访问,并且不会出现数据竞争、死锁、饥饿等异常情况。线程安全的程序可以保证在不同的线程之间共享同一个数据结构时,数据的正确性和一致性。线程安全的实现通常需要使用同步机制,如锁、原子操作等,来保证对共享数据的访问是线程安全的。在 Java 中,可以通过 synchronized 关键字、Lock 接口等机制来实现线程安全。根据以上代码来和模型进行交互,建议在运行时可以先 pip 安装一下 github 中的 requirements.txt;同时,Github 中的代码也提供了微调的方式,有兴趣的可以在 DevOps-Model 的基础上来微调自己的模型。
DevOps-Eval
数据来源
DevOps-Eval 最终生成的样本格式都为单项选择题,采用此类格式的原因是单项选择题客观性高,不但能够提高样本收集效率,并且方便进行自动化评测。
因此,我们收集样本的策略是尽可能获得选择题原题,或者通过某些手段生成或转换为选择题。经过统计,该项目的数据来源可以分为以下 5 大类:
1) 选择题类试题:直接为选择题形式的公开试题,例如计算机通识类考试试题、DevOps 专业考试试题等;
2) 问答类试题:此类试题以问答题的形式出现,且已按照 DevOps 场景进行了有效划分,来源如超级码客、devops-exercises 等,我们再在问答题基础上通过 ChatGPT 生成答案并转换为选择题;
3) 开源数据集:基于开源数据集构造 AIOps 相关样本,例如基于 LOGPAI 的数据构造日志解析相关的选择题样本,基于 TraceRCA 的数据构造根因分析相关选择题样本;
4) ChatGPT 生成:某些细分场景缺乏现成的试题,我们使用场景关键词通过 ChatGPT 直接生成相应的选择题;
5) 数据仿真生成:通过数据仿真的手段生成数据,例如时序异常检测、时序分类等试题。
数据分类
DevOps-Eval 根据 DevOps 全流程进行划分,共分为 8 个大类和 53 个子类,包含 4850 道选择题。其中,AIOps 场景有 4 个,共计 2200 个中英文题目。每个子类分为 dev 数据集和 test 数据集。
其中,dev 数据集包含 5 个带有标签和解析的样例,用于 few-shot 评测;test 数据集仅包含标签,用于模型评测。
下图给出了 DevOps-Eval 数据的具体细分类别。若要进一步了解各个类别包含的具体内容,可以参考 Github 中更为详细的样本明细脑图。
 图3. 数据细分类别
图3. 数据细分类别
DevOps 领域大模型评测榜单
评测方式
DevOps-Eval 包含 0-shot 和 Few-shot 两种评测方式。其中针对 DevOps 题目,主要评测 0-shot 和 5-shot 的结果。
而针对 AIOps 题目,由于题目的 token 长度较长(如日志解析任务,题干会包含多行日志),5-shot 后的题干长度会超过 2k 个 token。而大部分模型的训练的上下文就是 2k,所以针对 AIOps 的题目,主要评测 0-shot 和 1-shot 的结果。
Base 模型和 Chat 模型获取预测结果的方式如下:
1) Base 模型:将问题输入大模型后,基于模型预测下一个 Token 的得分,获得分别对应 A,B,C,D 四个选项的得分,将得分最高的选项作为模型对于这道题预测结果;
2) Chat 模型:我们先将问题转换为 Chat 模型对齐训练时使用的 prompt,比如 Qwen 采用的是 chatml 的格式,Baichuan2 是一种自定义的格式,采用模型对齐训练的格式能够使得模型更好地发挥其能力。当转换好后输入大模型,然后用和 Base 模型相同的方式获取预测结果。
评测结果
- DevOps 全流程评测榜单
(1)0-shot 评测结果
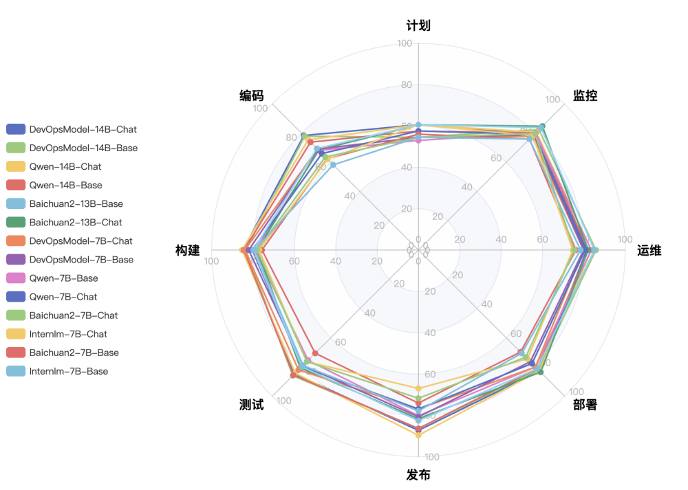
图4. DevOps 全流程评测榜单的 0-shot 评测结果
如图所示,0-shot 评测结果中 DevOps-Model-14B-Chat 平均分最高,达到了 80.34 分。从总体上来看,各模型的分数区分度不大。
(2)5-shot 评测结果

图5. DevOps 全流程评测榜单的 5-shot 评测结果
如图所示,5-shot 的结果要稍好于 0-shot,其中 DevOps-Model-14B-Chat 平均分依然最高,达到了 81.77 分。
从总体上来看,各模型的分数区分度也并不大,说明样本集难度偏低,后期需要区分下样本难度等级。
- AIOps 场景评测榜单
(1)0-shot 评测结果

图6. AIOps 场景评测榜单的 0-shot 评测结果
从 0-shot 结果来看, Qwen-14B-Base 平均分最高,达到了 49.27 分。从总体上来看,各模型在 AIOps 类别的区分度明显变大。
(2)1-shot 评测结果

图7. AIOps 场景评测榜单的 1-shot 评测结果
1-shot 的结果要稍好于 0-shot,其中 DevOps-Model-14B—Chat 平均分最高,达到了 53.91 分。
在不同细分类别的表现,根因分析得分相对较高,可能跟根因分析题目做了简化相对较为简单有关,而时序异常检测整体表现都不太好,当前大模型对时序类数据的处理依然有待提升。
从上述的评测结果可以看到,DevOps-Model-14B-Chat 在 3 项评测中获得了最好的结果,但同时也需要看到,在多个场景中,多个模型的评测结果差异不大,后续要针对 Eval 数据集做一些难度区分。
未来展望
DevOps-Model
当前发布的是模型的 1.0 版本,后续主要优化方向包括以下两点:
1)构造更加大、更多样的 DevOps 数据集:当前的 DevOps Corpus 只有 15G 的数据量,未来希望能够扩充到 50G 这个量级,进一步提升模型能力;
2)采用 DevOps 领域的专有词汇来扩充模型的词表。当前的模型词表是从比较通用的语料中产出的,然后针对 DevOps 领域,有一些专有的词汇并不在词表中,所以下一步会产出 DevOps 领域的专有词表加到 tokenizer 中来提升模型的效果。
DevOps-Eval
针对 DevOps-Eval 项目,主要优化方向包括以下几点:
1)不断丰富评测数据集:包括增加英文题目、平衡各类别的数据量,题型将不局限于选择题,增加问答等形式,对数据集增加难度分级等;
2)重点关注 AIOps 领域:AIOps 一直是运维领域的研究热点,大模型与 AIOps 能碰撞出什么火花也是当前行业内最关心的话题。目前 DevOps-Eval 已涵盖 4 类常见的 AIOps 任务,后续将继续增加,直至覆盖运维领域的所有智能化任务;
3)持续增加评测模型:一期主要评测了一些主流的、规模不是很大的开源模型,后续将覆盖更多的模型,并重点跟踪评测面向 DevOps 和 AIOps 领域的大模型。
希望能有更多伙伴加入共建 DevOps-Model 和 DevOps-Eval的行列,期待在大家的共同努力下,建立更准确、更全面的 DevOps 领域大模型评测体系,推动 DevOps 领域大模型技术的不断发展与创新。