













世界各地的人们每天都会创造大量视频,包括用户直播的内容、短视频、电影、体育比赛、广告等等。
视频是一种多功能媒介,可以通过文本、视觉和音频等多种模态传递信息和内容。如果可以开发出能学习多模态数据的方法,就能帮助人们设计出具备强大能力的认知机器 —— 它不会受限于经过人工调整的数据集,而是可以分析原生态的真实世界视频。但是,在研究视频理解时,多模态这种丰富的表征会带来诸多挑战,尤其是当视频较长时。
理解长视频是很复杂的任务,需要能分析多个片段的图像和音频序列的先进方法。不仅如此,另一大挑战是提取不同来源的信息,比如分辨不同的说话人、识别人物以及保持叙述连贯性。此外,基于视频中的证据回答问题也需要深入理解视频的内容、语境和字幕。当分析的是直播或游戏视频时,还存在实时处理动态环境的难题,这需要语义理解和长期策略规划能力。
近段时间,大型预训练视频模型和视频 - 语言模型带来了巨大进步,它们在视频内容上的推理能力已经显现。但是,这些模型通常是用短视频片段训练的(比如 Kinetics 和 VATEX 中的 10 秒视频)或预定义了动作类别(Something-Something v1 有 174 类)。由此造成的后果是,这些模型可能难以详细理解真实世界视频的复杂微妙。
为了让模型能更全面地理解我们日常生活中遇到的视频,我们需要能解决这些复杂挑战的方法。
近日,微软 Azure AI 为这些问题给出了自己的解答:MM-Vid。该团队表示这种技术可以直接用于理解真实世界视频。简单来说,他们的方法涉及将长视频分解成连贯叙述,然后再利用这些生成的故事来分析视频。

- 论文地址:https://arxiv.org/pdf/2310.19773.pdf
- 项目地址:https://multimodal-vid.github.io/
MM-Vid 是近来处于 AI 社区关注中心的大型多模态模型(LMM)的新成员;而 LMM 中最具代表性的 GPT-4V 已经展现出了突破性的能力 —— 可以同时处理输入的图像和文本,执行多模态理解。为了实现视频理解,MM-Vid 将 GPT-4V 与一些专用工具集成到了一起,实验结果也证明了这种方法的有效性。图 1 展示了 MM-Vid 能够实现的多种能力。

MM-Vid 方法介绍
图 2 展示了 MM-Vid 系统的工作流程。MM-Vid 以视频文件为输入,输出一个描述该视频内容的脚本。这种生成的脚本让 LLM 可以实现多种视频理解能力。

MM-Vid 包含四个模块:多模态预处理、外部知识收集、视频片段层面的视频描述生成、脚本生成。
多模态预处理。对于输入的视频文件,预处理模块首先使用已有的 ASR 工具从视频中提取出转录文本。之后,将视频切分成多个短视频片段。此过程需要对视频帧进行均匀采样,使得每个片段由 10 帧组成。为了提升帧采样的整体质量,研究者使用了 PySceneDetect 等成熟的场景检测工具来帮助识别关键的场景边界。
外部知识收集。在 GPT-4V 的输入 prompt 中,研究者采用了集成外部知识的方法。该方法涉及收集可用的信息,比如视频的元数据、标题、摘要和人物面部照片。在实验中,研究者收集的元数据、标题和摘要来自 YouTube。
片段层面的视频描述生成。在多模态预处理阶段,输入视频会被切分为多个视频片段。每个片段通常包含 10 帧,研究者的做法是使用 GPT-4V 来为每个片段生成视频描述。通过将视频帧与相关的文本 prompt 一起输入到 GPT-4V 模型,便能得到捕获了这些帧中描绘的视觉元素、动作和事件的详细描述。
此外,研究者还探索了视觉 prompt 设计,即在 GPT-4V 的输入中不仅提供人物的名字,还提供人物的面部照片。实验结果表明这种视觉 prompt 设计有助于提升视频描述的质量,尤其有助于更准确地识别人物。
使用 LLM 生成脚本。在为每个视频片段生成描述之后,再使用 GPT-4 将这些片段层面的描述整合成一个连贯的脚本。该脚本是对整个视频的全面描述,可被 GPT-4 用于解决各种视频理解任务。
用于流输入的 MM-Vid
图 3 展示了用于流输入的 MM-Vid。
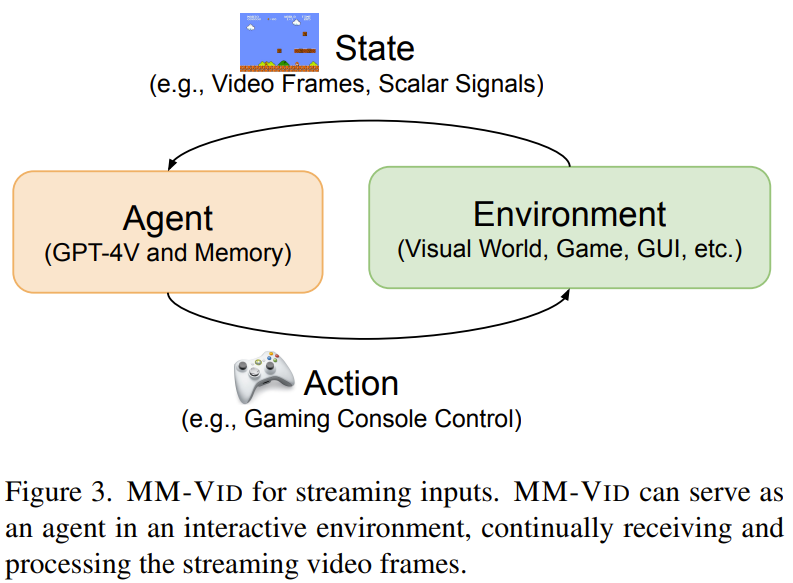
在这种情况下,MM-Vid 的运作模式是作为动态环境中的一个智能体(agent),其主要输入为流视频帧。该智能体会将持续输入的流视频帧视为状态,其代表了在该环境中不断揭示的持续性视觉信息。然后再由 GPT-4V 处理这些状态,从而得到有信息依据的决策并生成响应。
通过持续分析流视频帧,MM-Vid 可将原始视觉数据转换成有意义的见解,进而为视频游戏、具身智能体和 GUI 引导等应用提供有价值的帮助。
实验
实验设置
该团队实现的 MM-Vid 基于 MM-React 代码库。他们使用的自动语音识别(ASR)工具是通过 Azure Cognitive Services API 使用的公开可用工具,场景检测则是使用了 PySceneDetect。
MM-Vid 的功能
研究者在论文中展示了多个 MM-Vid 完整执行流程的示例。
下面是一个 MM-Vid 执行流程示例。

经过这些流程后,MM-Vid 生成的脚本总结了对视频内容的理解。从而让后续 LLM 可以基于此处理具体的任务。研究者讨论过的具体任务包括:有根据的问答、多模态推理、理解长达一小时的视频、多视频情景分析、人物识别、说话人识别、音频描述生成、自我调优、快速变化的短视频。具体详情请参阅原论文,但总体而言,MM-Vid 都展现出了很不错的效果。
下面是一个说话人识别的示例。
应用于交互式环境
研究者也评估了 MM-Vid 应用于流输入时的情况。MM-Vid 可作为交互式环境中的智能体,持续接收流视频帧输入。
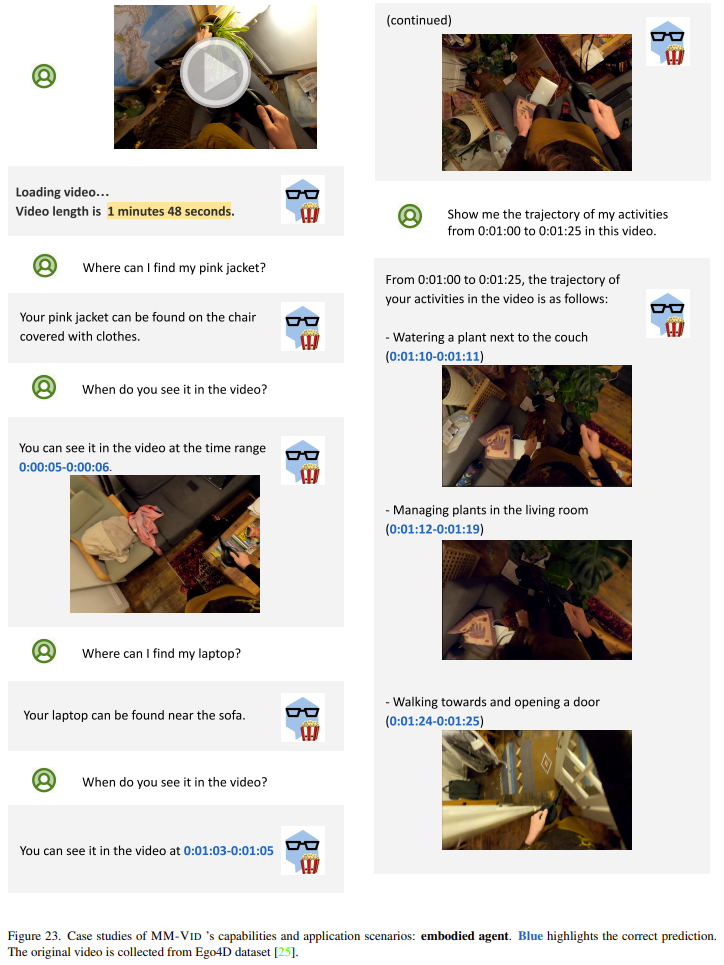
具身智能体。下图展示了将 MM-Vid 应用于一段头戴式相机拍摄的第一人称视频的情况。这段视频来自 Ego4D 数据集,简单展示了拍摄者在家居环境中的日常生活。值得注意的是,MM-Vid 理解这种视频内容的能力得到了体现,并且还能辅助用户完成一些实际任务。
玩视频游戏。下面的视频示例是将 MM-Vid 用于视频游戏《超级玛丽》。实验中,智能体会持续地以三帧视频作为输入的状态,然后计算下一个可能的控制动作。结果表明,这个智能体能够理解这种特定的视频游戏动态,并能生成可以有效玩游戏的合理动作控制。
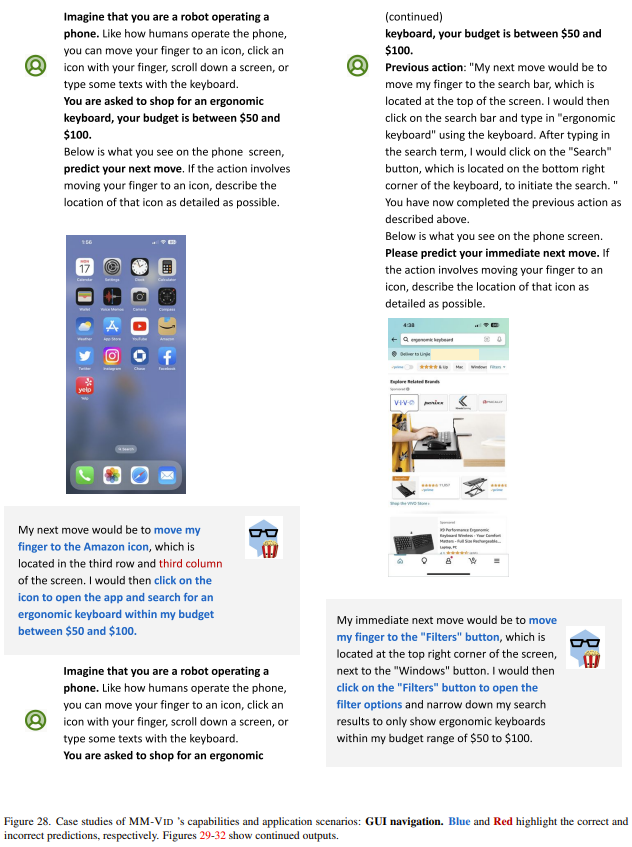
GUI 导引。下图给出了一个示例。这里,智能体持续接收的输入是 iPhone 屏幕截图和之前的用户动作。结果发现,该智能体可以有效预测用户使用手机时的下一步可能动作,比如点击正确的购物应用,然后搜索感兴趣的商品,最后下单购买。这些结果表明 MM-Vid 能与图形用户界面进行有效的交互,能通过数字接口实现无缝且智能化的用户导引。
用户研究
研究者探索 MM-Vid 帮助盲人或弱视者的潜力。音频描述(AD)能在视频的音轨中增加音频叙述,这能提供主视频音轨中没有提供的重要视觉详情。这样的描述能为视觉障碍人士传达关键的视觉内容。
为了评估 MM-Vid 在生成音频描述方面的有效性,研究者进行了一场用户研究。他们邀请了 9 位参与者参与评估。其中 4 位参与者失明或视力低下,其余 5 名视力正常。所有参与者听力都正常。
下面的视频是 MM-Vid 的音频描述应用示例:
结果如图 5 所示,对于以李克特量表计量的参与者总体满意度(0 = 不满意到 10 = 非常满意),MM-Vid 生成的音频描述平均比人工给出的音频描述低 2 分。
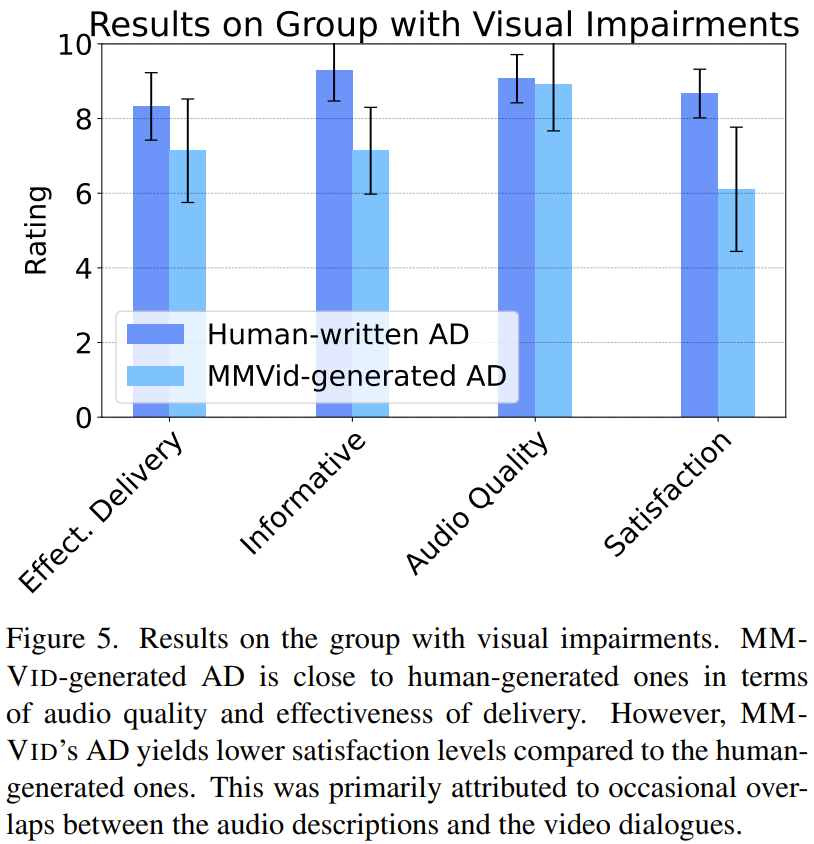
在听 MM-Vid 生成的音频描述时,参与者提出的困难包括:1)音频描述与原始视频中的对话偶尔重叠,2)由于 GPT-4V 的幻觉问题而出现错误描述。尽管总体满意度有差异,但所有参与者都认同这一点:MM-Vid 生成的音频描述是一种成本高效且可扩展的解决方案。因此,对于无法被专业人士描述成音频的大量视频来说,就可以使用 MM-Vid 这样的工具来处理它们,从而造福视觉障碍社区。































