大约一年前,我被分配任务从文件中提取和结构化数据,主要是包含在表格中的数据。我之前对计算机视觉没有了解,并且很难找到一个合适的“即插即用”的解决方案。当时可选的方案要么是基于最新神经网络(NN)的解决方案,这些解决方案庞大而繁琐,要么是基于OpenCV的较简单的解决方案,但不够一致。
受现有OpenCV脚本的启发,我开发了一种简单而一致的方法来提取表格,并将其制作成一个开源的Python库:img2table。
链接:https://github.com/xavctn/img2table

我的库有什么作用?
与深度学习解决方案相比,这个轻量级的包不需要训练和最小化参数化。它提供了以下功能:
- 识别图像和PDF文件中的表格,包括在表格单元级别的边界框。
- 通过支持OCR服务/工具(Tesseract、PaddleOCR、AWS Textract、Google Vision和Azure OCR目前支持)来提取表格内容。
- 处理复杂的表格结构,如合并单元格。
- 实现纠正图像的倾斜和旋转的方法。
- 提取的表格以一个简单的对象形式返回,包括一个Pandas DataFrame表示。
- 将提取的表格导出为Excel文件的选项,保留其原始结构。
如何使用它?
您可以通过pip安装该库,然后就可以使用了:
在文档中识别表格只需调用一个函数:

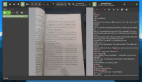
上述示例中使用的图像
如果我们想提取表格的内容,则需要使用OCR工具,可以按如下方式实现:

从PDF中提取的表格示例
最后,在简单的情况下,可以通过设置`borderless_tables`参数来执行“无边框”表格的提取。这允许检测那些单元格不需要完全被边框包围的表格。

“无边框”表格提取示例
这就是全部!实际上,库并没有太多复杂的东西,因为目标是尽可能简化,以避免其他可用解决方案可能带来的复杂性。
有关更详细的文档和示例,请查看项目的GitHub页面:https://github.com/xavctn/img2table
底层实现
所有图像处理都使用OpenCV和opencv-python库完成。然而,这仍然相当基础。
算法的骨架是Hough变换,它能够识别图像中的线条,使我们能够检测图像的水平和垂直线条。
之后,对线条进行一些处理以从线条中识别单元格,然后从单元格中识别表格。

实现算法的简化表示
大多数计算使用Polars进行,以实现良好的性能和速度。