












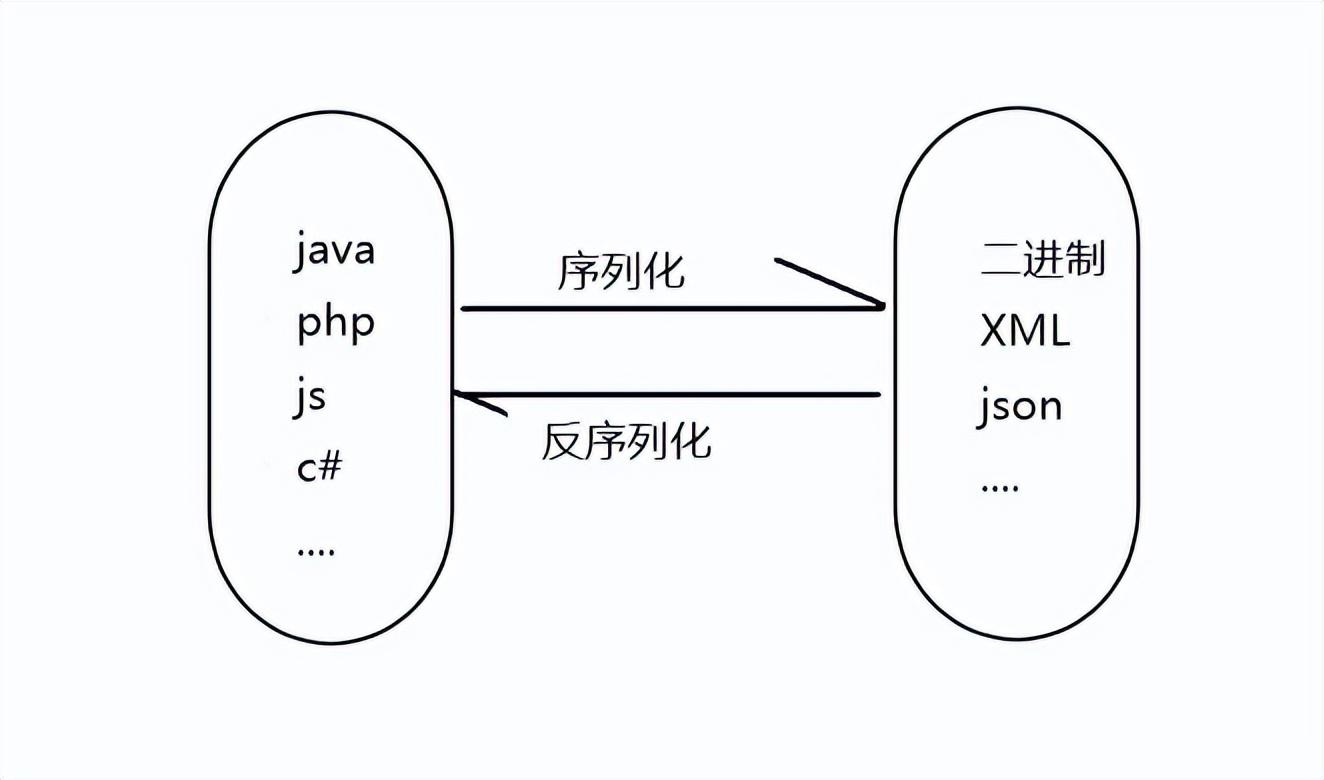
在计算机科学中,序列化(Serialization)是指将数据结构或对象状态转换为可存储或传输的格式的过程。这个过程允许将数据保存到文件、内存缓冲区,或通过网络传输至其他计算机环境,不受原始程序语言的限制。相对地,反序列化(Deserialization)则是将这种格式变回原来的数据结构或对象的过程。

序列化的形式和目的
序列化在现代软件工程中无处不在,但其形式和目的根据应用场景而异。
形式
- 二进制序列化:将数据转换为紧凑的二进制表示形式,常用于性能敏感的系统或低带宽的网络通信中。
- 文本序列化:将数据转换成如XML、JSON、YAML等文本格式,可读性好,易于调试,适合 Web API 和配置文件。
- 目的
- 持久化:长期保存对象的状态,使其可以在程序重启后恢复。
- 通信:跨进程或网络传输数据时,需要将对象状态序列化为标准格式,以便在接收端正确反序列化。
序列化的挑战和考虑因素
数据完整性
数据必须被完整且精确地序列化,以保证反序列化后对象状态的一致性。比如,在序列化包含循环引用的对象图时,需要特别注意引用的处理,以防止无限循环或丢失链接。
安全性
安全性问题主要出现在反序列化环节。如果反序列化未经验证的数据,可能会遭受注入攻击,导致代码执行或数据泄露。因此,输入验证和沙盒环境等安全措施是必要的。
性能
序列化和反序列化过程需要占用CPU资源,并影响I/O性能。特别是在大数据量或高频率调用的情况下,选择高效的序列化方法和库显得尤为重要。
版本兼容性
随着业务发展,数据结构可能会变化。良好的序列化策略应该能够处理数据模型的版本差异,提供向后兼容性支持。
反序列化时的对象图重建
反序列化不仅仅是简单地读取数据,还需要重新构建对象间的关系。这需要序列化机制有能力表达和重建复杂的对象引用网络。
常见的序列化技术
JSON
JSON 是一种轻量级的数据交换格式,能够被人和机器轻松读写。它已经成为 Web API 中的事实标准,用于客户端和服务器之间的数据交换。
XML
XML 是早期Web开发中广泛使用的数据交换格式,它具有自我描述性,并且通过Schema定义了严格的结构,非常适合复杂的数据交换需求。
Protocol Buffers
Protocol Buffers 是由Google开发的一种序列化协议,提供了跨多种编程语言的接口描述语言。它通过预定义的数据结构,提供了一种更紧凑、更高效的数据序列化方式。
Apache Avro
Apache Avro 是一个支持RPC的序列化框架。它使用JSON来定义数据类型和协议,并且存储序列化数据的元数据,这样即使没有代码也能进行反序列化。
实践建议
要有效地利用序列化和反序列化,以下是一些最佳实践:
- 明确需求:分析应用场景,选择满足需求的序列化方式。
- 安全防护:对反序列化的数据进行验证,防止潜在的安全风险。
- 性能优化:基于应用场景选择合适的序列化库和格式,考虑压缩与缓存策略。
- 测试:确保对序列化和反序列化的流程进行充分的单元和集成测试。
- 文档和维护:保持良好的文档记录,定期更新序列化协议及相关代码。
总结
序列化是连接各种计算环境的纽带,是数据持久化和互操作性的关键。无论是在分布式系统、微服务架构还是普通的数据存储中,理解并妥善运用序列化及其相关技术,都将对构建高效、安全、可维护的软件系统产生深远影响。





















