又是一年双11季,土豪们买买买,程序员看看热闹,聊聊技术。海量的订单、支付请求以及库存更新等任务,离不开分布式架构(SOFAStack)、分布式数据库(OceanBase)、分布式缓存(Tair)、数据处理(Flink)等一系列框架的支持。而消息队列作为连接这些组件的重要纽带,可以实现各组件之间的异步通信和解耦。本文接下来就聊聊消息队列那些事儿~
消息队列给我们带来什么?
消息中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削峰等问题,实现高性能,高可用,可伸缩和最终一致性的系统架构。
- 应用解耦
在分布式系统中,服务之间可能会有依赖关系,如果直接进行服务调用,会增加服务之间的耦合度。使用消息队列可以将服务之间的通信转化为消息的发送和接收,降低服务之间的耦合度。
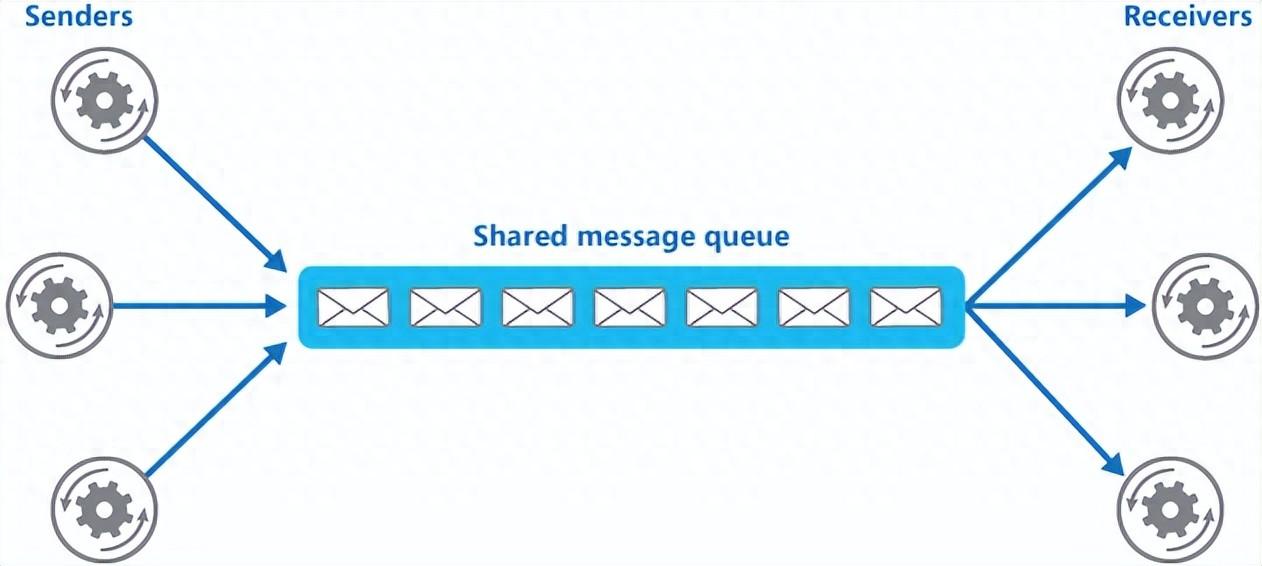
降低系统耦合性(源于网络)
- 流量削峰/数据缓冲
在高并发场景下,瞬间的请求量可能会超出系统的承受能力,导致系统瘫痪。使用消息队列可以实现流量削峰,将请求放入消息队列中,由消费者服务异步消费请求,有效降低瞬间的请求量,保护系统稳定性。
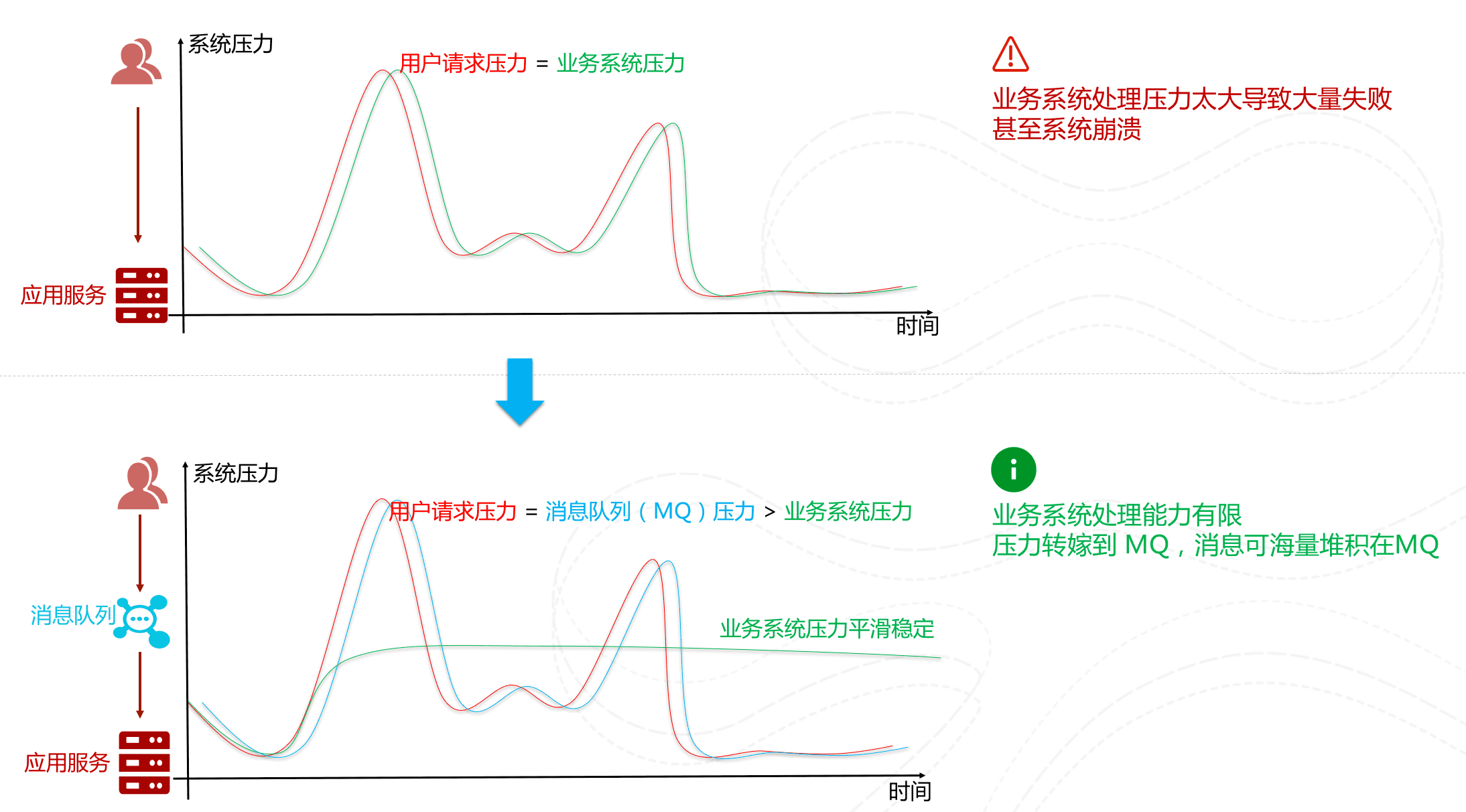
削峰/限流(源于网络)
- 异步处理:
在分布式系统中,不同服务之间的调用可能会因为网络延迟或者服务负载高等原因导致调用时间较长。使用消息队列可以实现异步处理,将请求放入消息队列中,由消费者服务异步消费请求,提高系统的并发性和吞吐量。
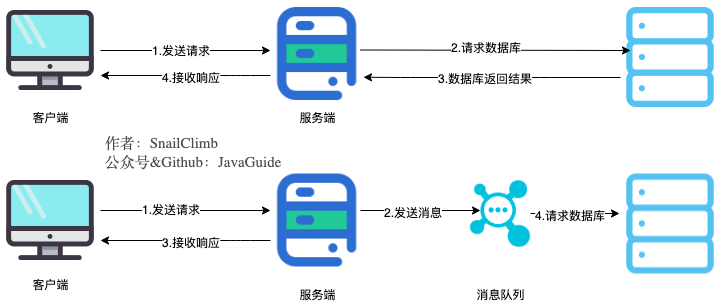
异步提高性能(源于网络)
常用的消息队列框架?
目前在市面上比较主流的消息队列中间件主要有,Kafka、ActiveMQ、RabbitMQ、RocketMQ 等这几种。
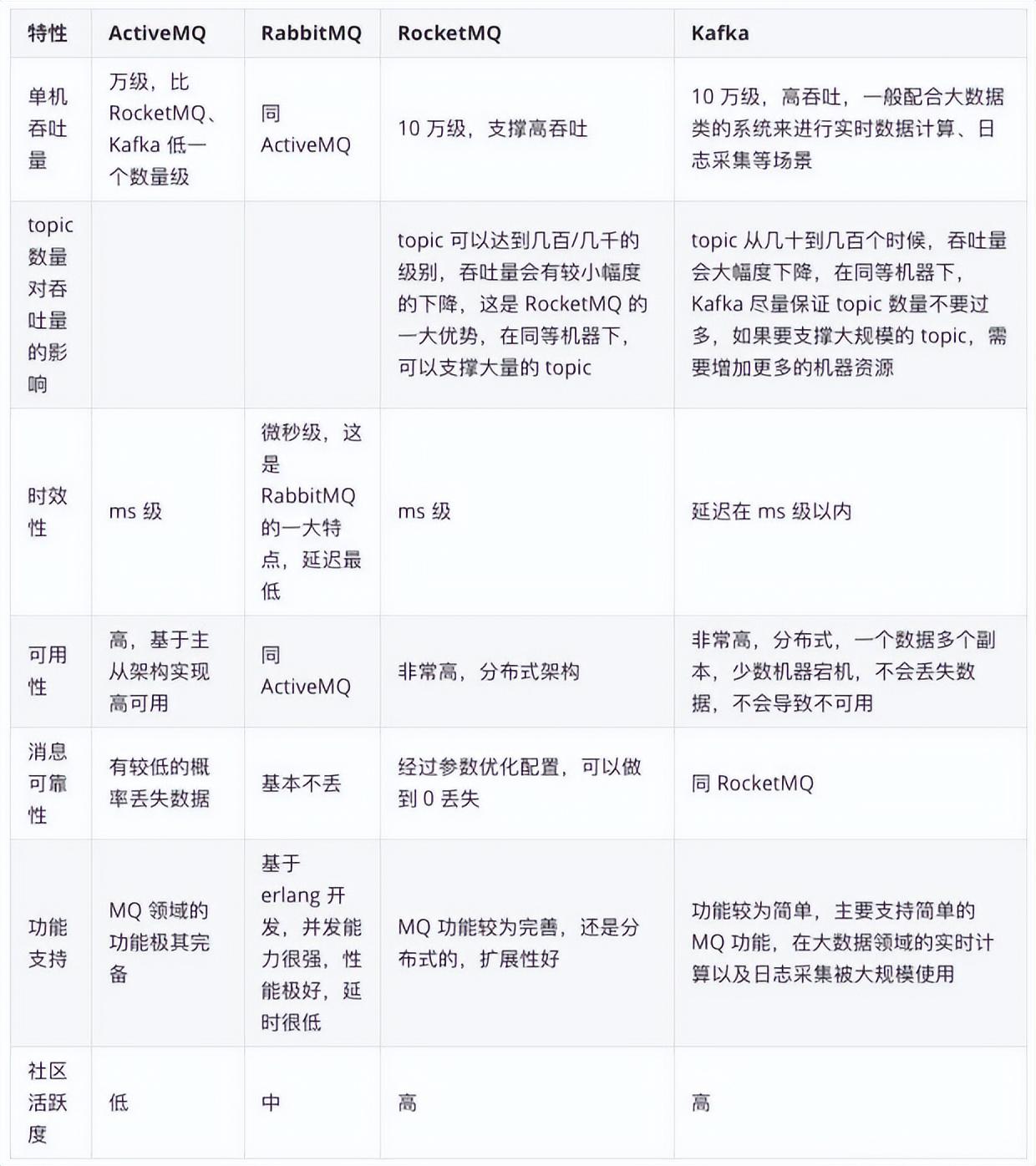
RocketMQ和Kafka 都是高吞吐量、高可用的分布式消息队列系统,相较于早期较活跃的ActiveMQ 和RabbitMQ 还是有着明显优势的,特别是在双11这样的场景,吞吐量的重要性是不言而喻的。
接下来从多个维度重点对RocketMQ与Kafka对比:
数据可靠性
- RocketMQ:支持异步实时刷盘、同步刷盘、同步复制、异步复制。“同步刷盘”,可以提高单机的可靠性,避免数据丢失。
- kafka:使用异步刷盘方式,异步复制/同步复制。采用的是异步刷盘的方式,可能会存在一定的数据丢失风险。不过,Kafka也提供了一些可靠性保障的机制,例如副本机制和ISR机制等,可以在一定程度上保证数据的可靠性。
在同步复制方面,RocketMQ可以利用IO组的commit机制,批量传输数据,因此性能上可能比Kafka要更好一些。而Kafka的同步复制是以partition为单位进行的,一个Kafka实例上可能有多个partition,这可能会影响性能。
单机支持的队列数
- kafka单机若超过超过一定数量的partition/队列,CPU load会发生明显飙高,partition越多,CPU load越高,发消息的响应时间变长。
- RocketMQ单机支持最高5万个队列,CPU load不会发生明显变化。
队列多有什么好处呢?
单机可以创建更多个topic, 因为每个topic都是有一组队列组成。
消费者的集群规模和队列数成正比,队列越多,消费类集群可以越大。
消息投递的实时性
- kafka只支持pull模式,实时性取决于pull时间间隔(0.8以后版本支持长轮询)
- rocketmq有pull(长轮询)、push两种模式 (虽然这个push模式是假push),push模式延迟肯定是比pull模式延迟低。
push模式是基于pull模式的,本地有个定时线程去pull broker的消息,缓存到本地,然后push到消费线程。
消费失败重试
- Kafka本身不支持消费失败重试,但是可以通过设置消费者的参数来实现重试机制。如,设置消费者的max.poll.retries
- RocketMQ消费失败支持定时重试,每次重试间隔时间顺延。
这里的重试指可靠的重试,即失败重试的消息不是因为consumer宕机而导致的消息丢失。
严格保证消息有序
- kafka可保证同一个partition上的消息有序,但一旦broker宕机,就会产生消息乱序。
- Rocket支持严格的消息顺序,一台broker宕机,发送消息会失败,但不会乱序。举例:MySQL的二进制日志分发需要保证严格的顺序。
定时消息
- kafka不支持定时消息
- 开源版本的RocketMQ仅支持定时级别,定时级别用户可定制
分布式事务消息
- kafka不支持分布式事务消息
- RocketMQ支持分布式事务消息。
消息查询
- Kafka本身不提供内置的消息查询功能
- RocketMQ支持根据消息标识(发送消息时指定一个消息key, 任意字符串,如指定为订单编号)查询消息,也支持根据消息内容查询消息。
消息回溯
- kafka可按照消息的offset来回溯消息
- RocketMQ支持按照时间来回溯消息,精度到毫秒,例如从一天的几点几分几秒几毫秒来重新消费消息。
RocketMQ按时间做回溯消息的典型应用场景为,consumer做订单分析,但是由于程序逻辑或依赖的系统发生故障等原因,导致今天处理的消息全部无效,需要从昨天的零点重新处理。
消息并行度
- kafka的消息并行度,依赖于topic里配置的partition数,如果partition数为10,那么最多10台机器来消费,每台机器只能开启一个线程;或者一台机器消费,最多开启10个线程。消费的并行度与partition个数一致。
- RocketMQ并行消费分两种情况:1)顺序消费方式的并行度与kafka一致;2)乱序消费方式的并行度取决于consumer的线程数,如topic配置10个队列,10台机器消费,每台机器100个线程,那么并行度为1000。
消息队列如何选型?
- ActiveMQ 的社区算是比较成熟,但是较目前来说,ActiveMQ 的性能比较差,而且版本迭代很慢,不推荐使用。
- RabbitMQ 在吞吐量方面虽然稍逊于 Kafka、RocketMQ ,由于它基于 Erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为基于 Erlang 开发,所以国内很少有公司有实力做 Erlang 源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这几种消息队列中,RabbitMQ 或许是你的首选。
- RocketMQ 阿里开源,久经双十一考验,可以定制自己公司的 MQ。且支持事务消息,对消息一致性要求比较高的场景优先考虑。
- Kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 Kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。Kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。如果是大数据领域的实时计算、日志采集等场景,用 Kafka 可谓是行业标准。
消息队列常见问题
如何避免重复消费?如何保证幂等性?
幂等性:就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用问题
我们先来了解一下产生消息重复消费的原因,对于MQ的使用,有三个角色:生产者、MQ、消费者,那么消息的重复这三者会出现:
- 生产者:生产者可能会推送重复的数据到MQ中,有可能controller接口重复提交了两次,也可能是重试机制导致的
- MQ:假设网络出现了波动,消费者消费完一条消息后,发送ack时,MQ还没来得及接受,突然挂了,导致MQ以为消费者还未消费该条消息,MQ回复后会再次推送了这条消息,导致出现重复消费。
- 消费者:消费者接收到消息后,正准备发送ack到MQ,突然消费者挂了,还没得及发送ack,这时MQ以为消费者还没消费该消息,消费者重启后,MQ再次推送该条消息。
如何解决呢?在正常情况下,生产者是客户,我们很难避免出现用户重复点击的情况,而MQ是允许存在多条一样的消息,但消费者是不允许出现消费两条一样的数据,所以幂等性一般是在消费端实现的:
- 状态判断:消费者把消费消息记录到redis中,再次消费时先到redis判断是否存在该数据,存在则表示消费过,直接丢弃
- 业务判断:消费完数据后,都是需要插入到数据库中,使用数据库的唯一约束防止重复消费。插入数据库前先查询是否存在该数据,存在则直接丢弃消息,这种方式是比较简单粗暴地解决问题
如何解决消息丢失?
消息丢失属于比较常见的问题。一般有生产端丢失、MQ服务丢失、消费端丢失等三种情况。针对各种情况应对方式也不一样。
生产端丢失的解决方案主要有。
- 开启confirm模式,生产着收到MQ发回的confirm确认之后,再进行消息删除,否则消息重推。
- 生产者端消息保存的数据库,由后台定时程序异步推送,收到confirm确认则认为成功,否则消息重推,重推多次均未成功,则认为发送失败。
MQ服务丢失则主要是开启消息持久化,让消息及时保存到磁盘。
消费端消息丢失则关闭自动ack确认,消息消费成功后手动发送ack确认。消息消费失败,则重新消费。
(3)如何保证消息有序性
在生产端发布消息时,每次法发布消息都把上一条消息的ID记录到消息体中,消费者接收到消息时,做如下操作:
- 先根据上一条Id去检查是否存在上一条消息还没被消费,如果不存在(消费后去掉id),则正常进行,如果正常操作
- 如果存在,则根据id到数据库检查是否被消费,如果被消费,则正常操作
- 如果还没被消费,则休眠一定时间(比如30ms),再重新检查,如被消费,则正常操作
- 如果还没被消费,则抛出异常
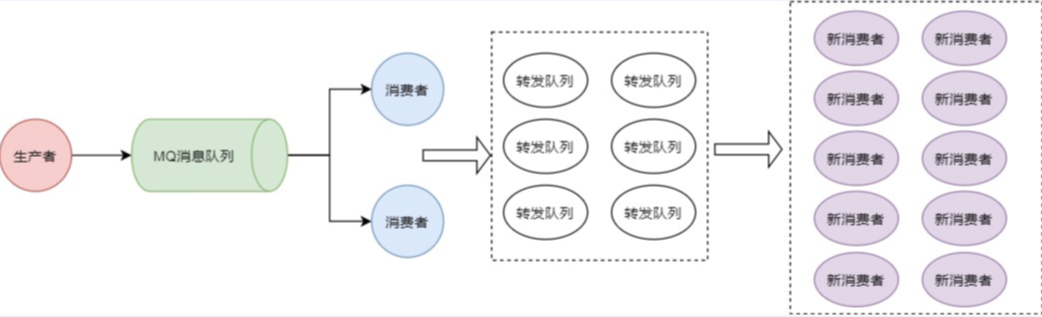
(4) 如何解决消息积压问题?
所谓的消息积压,即生成者生成消息太快,而消费者处理消息太慢,从而导致消费端消息积压在MQ中无法处理的问题。遇到这种消息积压的情况,可以根据消息重要程度,分为两种情况处理:
- 如果消息可以被丢弃,那么直接丢弃就好了
- 一般情况下,消息是不可以被丢弃的,这样就需要考虑策略了,可以将原本的消费端重新部署为一个新的消息队列(MQ)实例,并在后续增加消费端,以形成另一条生产-消息-消费的线路。
PS:实际项目中是否需要使用消息队列以及如何使用,还是要根据业务特点进行选择,一个UV没几个的系统,使用消息队列,则纯粹是老板掏钱、研发受罪了。