译者 | 朱先忠
审校 | 重楼
在剑桥大学担任神经成像和人工智能研究科学家期间,我面临着使用最新的深度学习技术,尤其是nnU-Net,在复杂的大脑数据集上进行图像分割的挑战。在这项工作中,我注意到存在一个显著的差距:对不确定性估计的忽视!然而,不确定性对于可靠的决策却是至关重要的。
在深入研究有关细节之前,您可以随意查看我的Github存储库,其中包含本文中讨论的所有代码片段。
不确定性在图像分割中的重要性
在计算机视觉和机器学习领域,图像分割是一个核心问题。无论是在医学成像、自动驾驶汽车还是机器人领域,准确的分割对于有效的决策至关重要。然而,一个经常被忽视的方面是与这些分割相关的不确定性的衡量。
为什么我们要关心图像分割中的不确定性?
在许多实际应用中,不正确的分割可能会导致可怕的后果。例如,如果一辆自动驾驶汽车误认了一个物体,或者医学成像系统错误地标记了一个肿瘤,后果可能是灾难性的。不确定性估计为我们提供了一个衡量模型对其预测的“确定度”的指标,从而做出更明智的决策。
我们还可以使用熵作为不确定性的度量来改进我们神经网络的学习。这一领域被称为“主动学习”。有关这一想法的更多的细节将在下一篇文章中探讨,不过主要想法还是确定模型最不确定的区域,以便将重点放在这些区域上。例如,我们可以让卷积神经网络(CNN)对大脑进行医学图像分割,但对患有肿瘤的受试者表现非常差。然后我们可以集中精力获得更多这种类别的标签。
理解熵概念
熵(Entropy)是从热力学和信息论中借来的一个概念,它量化了系统中的不确定性或随机性。在机器学习的背景下,熵可以用来测量模型预测的不确定性。
在数学上,对于具有概率质量函数P(X)的离散随机变量X,熵H(X)定义为:
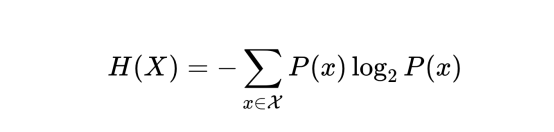
或者在连续的情况下:
 熵越高,不确定性就越大;反之亦然。
熵越高,不确定性就越大;反之亦然。
下面,我们给出一个经典的例子来辅助充分掌握熵这个概念:
情形1:两面不均匀的硬币
想象一下,一枚非均匀的硬币,正面向上的概率为p=0.9,反面向上的概率为1-p=0.1。
于是,它的熵是:
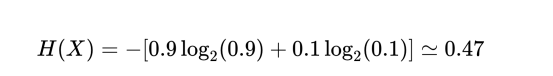
情况2:两面均匀的硬币
现在让我们想象一个两面均匀的硬币,它的正面和反面都着地的概率都是p=0.5。于是,其熵为:
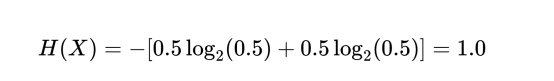
熵更大时,这与我们之前所说的一致,即有:更多的不确定性=更多的熵。
实际上,值得注意的是,p=0.5对应于最大熵:
") 熵的可视化描述(作者本人自制图像)
熵的可视化描述(作者本人自制图像)
从直觉上来看,均匀分布对应熵最大的情况。如果每个结果都是同样可能的,那么这将对应于最大的不确定性。
熵在图像分割中的实现
为了将其与图像分割联系起来,请考虑在深度学习中,最终的Softmax层通常提供每个像素的类别概率。可以基于这些Softmax输出来容易地计算每个像素的熵。
但这是如何工作的呢?
当模型对属于特定类别的特定像素非常有信心时,Softmax层对该类别显示出高概率(~1),而对其他类别显示出非常小的概率(~0)。
") Softmax图层(非常有信心的情形,作者自制图片)
Softmax图层(非常有信心的情形,作者自制图片)
相反,当模型不确定时,Softmax输出更均匀地分布在多个类别中。
") Softmax层的不确定性情况(作者自制图片)
Softmax层的不确定性情况(作者自制图片)
显然,上面的概率结果表现得比较分散,如果你还记得的话,这接近于均匀分布的情况,因为模型无法决定哪个类别与像素相关。
如果你能坚持阅读到现在,那就太好了!这说明你应该对熵的工作原理有很好的直觉理解了。
案例研究:医学影像学
接下来,让我们使用一个医学成像的实际例子来说明这一点,特别是胎儿的T1大脑扫描的情况。有关这个案例研究的所有代码和图像都可以在我的Github存储库中找到。
1.用Python编程计算熵
正如我们之前所说,我们正在使用神经网络给出的Softmax输出张量。这种方法不依赖于具体的模型,它只使用每个类别的概率。
下面,让我们来澄清一些关于我们正在处理的张量的维度的重要内容。
如果使用2D图像,则Softmax层的形状应为:
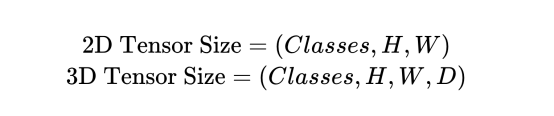
这意味着,对于每个像素(或三维像素),我们都有一个大小为Classes的向量,这样就确定了一个像素属于我们所拥有的每个类别的概率。
于是,熵应该是沿着第一维度的计算结果:
def compute_entropy_4D(tensor):
"""
计算具有形状(number_of_classes,256256256)的4D张量上的熵。
参数:
tensor (np.ndarray): 形状 (number_of_classes, 256, 256, 256)的4D张量。
返回值:
np.ndarray: 形状(256, 256, 256)的3D张量,相应于每一个像素的熵值。
"""
# 首先,沿着类别坐标轴归一化张量,使其表示概率
sum_tensor = np.sum(tensor, axis=0, keepdims=True)
tensor_normalized = tensor / sum_tensor
# 计算熵
entropy_elements = -tensor_normalized * np.log2(tensor_normalized + 1e-12) # 添加一个小数,以避免log(0)
entropy = np.sum(entropy_elements, axis=0)
entropy = np.transpose(entropy, (2,1,0))
total_entropy = np.sum(entropy)
return entropy, total_entropy2.可视化基于熵的不确定性
现在,让我们在图像分割的每个切片上使用热图来可视化不确定性。
,分割(中),熵(右):作者自制图像") T1扫描(左),分割(中),熵(右):作者自制图像
T1扫描(左),分割(中),熵(右):作者自制图像
让我们看看另一个例子:
,分割(中),熵(右):作者自制图像") T1扫描(左),分割(中),熵(右):作者自制图像
T1扫描(左),分割(中),熵(右):作者自制图像
结果看起来很棒!事实上,我们可以看到这是一致的,因为高熵区位于形状的轮廓处。这是正常的,因为模型并不真正怀疑每个区域中间的点,而是很难发现的边界或轮廓。
做出知情决策
总体来看,本文介绍的上述这种不确定性可以通过多种不同的方式使用:
- 随着医学专家越来越多地将人工智能作为一种工具,意识到模型的不确定性至关重要。这意味着,医学专家可能会在需要更精细关注的区域花费更多时间。
- 在主动学习或半监督学习的背景下,我们可以利用基于熵的不确定性来关注具有最大不确定性的例子,并提高学习效率(更多关于这一点的信息,请参阅后续文章)。
主要收获
- 熵是衡量系统随机性或不确定性的一个非常强大的概念。
- 在图像分割中利用熵是可能的。这种方法是无模型(即“不依赖具体的模型”)的,并且只使用Softmax输出张量。
- 不确定性估计被忽略了,但它是至关重要的。优秀的数据科学家知道如何制作好的模型。大数据科学家知道他们的模型在哪里失败,并利用它来改进学习。
最后,如果你喜欢这篇文章,并且想了解更多的相关信息的话,请查看这个代码仓库:https://github.com/FrancoisPorcher?source=post_page-----812cca769d7a
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Entropy based Uncertainty Prediction,作者:François Porcher