Labs 导读
Redis ( Remote Dictionary Server)远程字典服务,是一款通过Key-Value存储的NoSql数据库,数据缓存在内存中,支持网络、可持久化日志,提供多种语言的API,常用的场景有高速缓存、分布式数据共享、分布式锁、限流和消息队列等。通常项目研发中,结合springframework封装的RedisTemplate API使用。

Part 01、 环境搭建
● 操作系统:CentOS7
● 集成环境:CLion
● 编译环境:GCC9
● 代码版本:redis-6.2.6
1.1 环境安装
操作系统和集成环境的可自行安装。由于Centos 7默认gcc版本较低,因此需要升级GCC版本,通过如下命令可完成编译环境的升级:
# 安装centos-release-scl
% yum -y install centos-release-scl
# 安装devtoolset GGC9
% yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
# 激活对应的devtoolset
% echo “source /opt/rh/devtoolset-9/enable” >> /etc/profile
# 查看版本
% gcc -v1.2 编译和运行
从官方网站下载源码,解压,编译和运行。
% wget http://download.redis.io/releases/redis-6.2.6.tar.gz
% tar -zxvf redis-6.2.6.tar.gz -C /home/jay/redis/redis-6.2.6/ && rm -rf redis-6.2.6.tar.gz
% cd /home/jay/redis/redis-6.2.6/
% make
% make install
# 启动Redis
% cd src
% ./redis-server
# 验证
% cd src
% ./redis-cli 图片
图片
使用Clion建立C工程,并导入源代码,确保GCC9是对应的编译环境,以调试模式启动“redis-server”模块,使用“redis-cli”客户端连接服务端,设置断点,键入相应的命令进行调试。
 图片
图片
Part 02、 数据库的组织结构
首先从宏观层面了解数据库的结构及组织关系。redisDB,dict,dictht,dictEntry,
redisObject等相关数据库结构定义在server.h, dict.h,sds.h和zipList.h等头文件中。
//server.h
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
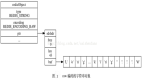
} redisDb;下图通过UML类图的方式,梳理各个数据结构之间的组织关系。
 图片
图片
通过上图,可以了解到如下内容:
(1) RedisDB可有多个,通过“redis.conf”中的“databases”参数进行配置,默认是16个;
(2) 每个RedisDB有两个"dictht"哈希表组成,分别是ht[0]和ht[1],这样做的目的是为了rehash,主要解决扩容和缩容的问题,通过ht[0]和ht[1]相互搬迁数据完成rehash工作,而且每次命令只搬迁一个索引下面的数据,减少系统操作时间,避免因数据量过大而影响性能;其实现在“dict.c”的dictRehash函数中。
(3) HASH表中存储的每个元素是“dictEntry”结构组成的链表。通过链式,解决两个key的哈希值正好落在同一个哈希桶中的哈希冲突问题。
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
/*在HASH桶中找到非空的索引后,开始链表的数据移动工作*/
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* 在新的hash表中找到对应键值的索引 */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
/* 把要增加的数据放在新的hash表对应索引链表的开始 */
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
/* 更新计数器 */
d->ht[0].used--;
d->ht[1].used++;
/* 链表中的下一个Node */
de = nextde;
}
/* 因数据已完成移动,因此清空老的hash表对应的桶 */
d->ht[0].table[d->rehashidx] = NULL;
/* 指向下一个桶 */
d->rehashidx++;
}
/* 如果已经rehashed了所有的表,释放HT[0]的表空间,将HT[1]设置为当前的表,重置HT[1] */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}(4) “dictEntry”中的"key"由sds(简单动态字符串)结构组成。redis根据数据的长度,定义了不同类型的sds结构。例如:sdshdr8,sdshdr16,sdshdr32,sdshdr64;这样的结构定义,既节省了空间,也解决了二进制安全(例如C语言的‘\0’)和缓冲区溢出(通过alloc-len可计算剩余空间)等问题。
//SDS.H
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};(5) redis有“STRING, LIST,SET,ZSET,HASH,MODULE,STREAM”七种数据类型;有“sds, quicklist,ziplist,dict,zskiplist,stream”七种底层数据结构;每种数据类型根据存储数据的大小,多少等,分别由不同的底层数据结构实现。例如list数据类型,由“quicklist,ziplist”分别实现;HASH数据类型,由“dict,ziplist”分别实现。
(6) dictEntry”中的"*val"指向redisObject"结构,此结构中“redisObject->type”存储的是数据类型;“redisObject->encoding”存储的是底层的数据结构类型;redisObject->ptr”存储具体的数据;相应的实现在“object.c”中。
//object.c
robj *createQuicklistObject(void) {
quicklist *l = quicklistCreate();
robj *o = createObject(OBJ_LIST,l);
o->encoding = OBJ_ENCODING_QUICKLIST;
return o;
}
robj *createZiplistObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_LIST,zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(OBJ_SET,d);
o->encoding = OBJ_ENCODING_HT;
return o;
}
robj *createIntsetObject(void) {
intset *is = intsetNew();
robj *o = createObject(OBJ_SET,is);
o->encoding = OBJ_ENCODING_INTSET;
return o;
}
robj *createHashObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}Part 03、 源码调试
3.1 入口
正如所有的C代码一样,入口是service.c中的main函数。
 图片
图片
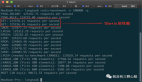
3.2 redis命令入口
所有的redis命令定义在“redisCommandTable”数组中,类型为"redisCommand",通过函数指针的方式调用。例如下图中的Get和Set命令。
 图片
图片
 图片
图片
Part 04、 总结
以上分别从环境搭建,数据库的结构组织关系和源码调试进行了介绍,如果你对redis源代码感兴趣,行动起来吧!