













自动机器学习(Auto-ML)是指自动化数据科学模型开发流水线的组件。AutoML 减少了数据科学家的工作量,并加快了工作流程。AutoML 可用于自动化各种流水线组件,包括数据理解,EDA,数据处理,模型训练,超参数调整等。
在本文中,我们将讨论如何使用开放源码的 Python 库 LazyPredict 来自动化模型训练过程。

什么是 LazyPredict ?
LazyPredict 是一个开源的 Python 库,它自动化了模型培训流水线并加快了工作流。LazyPredict 为一个分类数据集训练了大约30个分类模型,为一个回归数据集训练了大约40个回归模型。
Lazypredicate 返回训练好的模型以及它的性能指标,而不需要编写很多代码。我们可以比较每个模型的性能指标,并优化最佳模型以进一步提高性能。
安装
可以通过以下方式从 PyPl 库安装 LazyPredict:
pip install lazypredict安装完成后,可导入库进行分类和回归模型的自动训练。
from lazypredict.Supervised import LazyRegressor, LazyClassifier用法
Lazypredicate 同时支持分类和回归问题,因此我们将进行这两个任务的演示:
波士顿住房(回归)和泰坦尼克号(分类)数据集用于演示 LazyPredict 库。
() 分类任务:
LazyPredict 的使用非常直观,类似于 scikit-learn。首先,为分类任务创建一个估计器 LazyClassifier 的实例。可以通过自定义指标进行评估,默认情况下,每个模型都会根据准确度、ROC AUC 分数、F1 分数进行评估。
在进行 lazypredict 预测模型训练之前,必须读取数据集并对其进行处理以使其适合训练。
import pandas as pd
from sklearn.model_selection import train_test_split
# Read the titanic dataset
df_cls = pd.read_csv("titanic.csv")
df_cls = df_cls.drop(['PassengerId','Name','Ticket', 'Cabin'], axis=1)
# Drop instances with null records
df_cls = df_cls.dropna()
# feature processing
df_cls['Sex'] = df_cls['Sex'].replace({'male':1, 'female':0})
df_cls['Embarked'] = df_cls['Embarked'].replace({'S':0, 'C':1, 'Q':2})
# Creating train test split
y = df_cls['Survived']
X = df_cls.drop(columns=['Survived'], axis=1)
# Call train test split on the data and capture the results
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)经过处理将数据拆分为训练测试数据后,我们可以使用 LazyPredict 进行模型训练。
# LazyClassifier Instance and fiting data
cls= LazyClassifier(ignore_warnings=False, custom_metric=None)
models, predictions = cls.fit(X_train, X_test, y_train, y_test)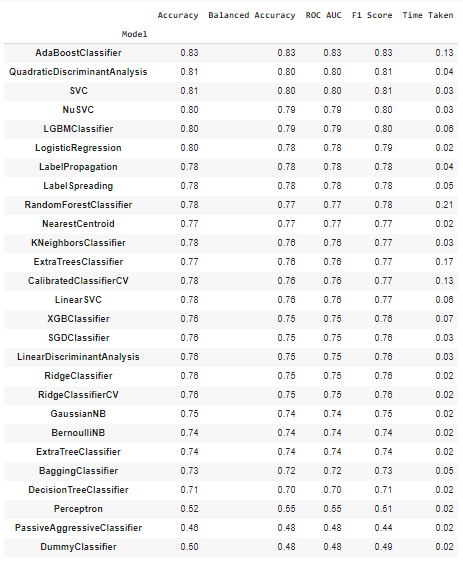
(2)回归任务:
类似于分类模型训练,lazypredicate 提供了用于回归数据集的自动模型训练。实现类似于分类任务,只是对实例 LazyRegressor 进行了更改。
import pandas as pd
from sklearn.model_selection import train_test_split
# read the data
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
df_reg = pd.read_csv("housing.csv", header=None, delimiter=r"\s+", names=column_names)
# Creating train test split
y = df_reg['MEDV']
X = df_reg.drop(columns=['MEDV'], axis=1)
# Call train_test_split on the data and capture the results
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
reg = LazyRegressor(ignore_warnings=False, custom_metric=None)
models, predictions = reg.fit(X_train, X_test, y_train, y_test)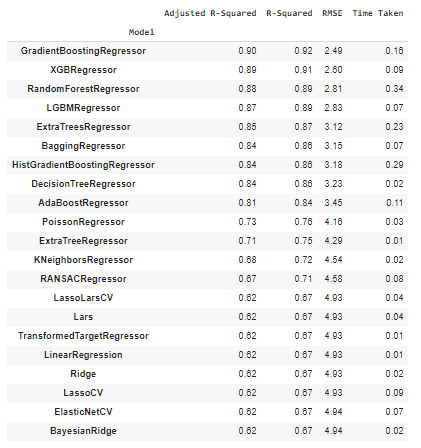
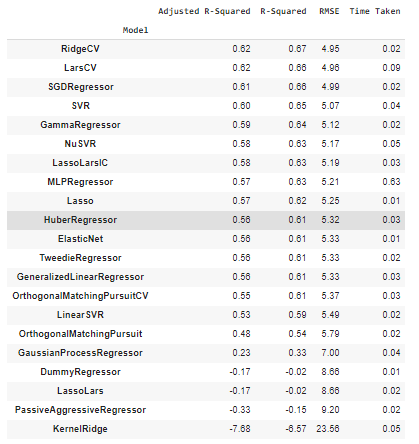
从以上性能指标来看,AdaBoost 分类器是分类任务的最佳执行模型,而 GradientBoostingRegressor 模型是回归任务的最佳执行模型。
总结
在本文中,我们讨论了 LazyPredict 库的实现,该库可以在几行 Python 代码中训练大约70个分类和回归模型。这是一个非常方便的工具,因为它提供了模型执行情况的总体图像,并且可以比较每个模型的性能。
每个模型都使用其默认参数进行训练,因为它不执行超参数调整。选择性能最佳的模型后,开发人员可以调整模型以进一步提高性能。
























