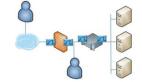
在开发Kata/remote-hypervisor(也称为peer-pods)方案时,我遇到了一个问题,即Kubernetes pod IP在工作节点上无法访问。在本博客中,我将描述Kubernetes网络故障排查过程,希望对读者有帮助。
译自A Hands-on Kubernetes Network Troubleshooting Journey。
Kata远程管理程序(peer-pods)方案通过在AWS或Microsoft Azure等基础设施环境中使用本机基础设施管理API(如在AWS上创建Kata VM时使用AWS API,在Azure上创建时使用Microsoft Azure API),实现在任何基础设施环境中创建Kata VM。CNCF保密容器项目的cloud-api-adaptor子项目实现了Kata远程管理程序。
如下图所示,在peer-pods方案中,pod(Kata)虚拟机在Kubernetes(K8s)工作节点外部运行,通过VXLAN隧道从工作节点访问pod IP。使用隧道可以确保pod联网继续正常工作,无需对CNI网络做任何改变。
 图片
图片
当使用Kata容器时,Kubernetes pod在虚拟机内运行,因此我们将运行pod的虚拟机称为Kata VM或pod虚拟机。
问题
pod IP10.132.2.46,它位于pod虚拟机上(IP:192.168.10.201),从工作节点虚拟机(IP:192.168.10.163)无法访问。
以下是我环境中的虚拟机详细信息 —— 工作节点虚拟机和pod(Kata)虚拟机。使用的Kubernetes CNI是OVN-Kubernetes。
+===========================+================+================+
| VM名称 | IP地址 | 备注 |
+===========================+================+================+
| ocp-412-ovn-worker-1 | 192.168.10.163 | 工作节点虚拟机 |
+---------------------------+----------------+----------------+
| podvm-nginx-priv-8b726648 | 192.168.10.201 | Pod虚拟机 |
+---------------------------+----------------+----------------+最简单的解决方案就是请网络专家来解决这个问题。然而,在我的情况下,由于其他紧迫问题,专家无法直接参与解决。此外,peer-pods网络拓扑结构还比较新,涉及多个网络栈 —— Kubernetes CNI、Kata网络和VXLAN隧道,使得根本原因难以查明且非常耗时。
因此,我将这种情况视为提高我的Kubernetes网络技能的机会。在一些Linux网络核心专家的指导下,我开始自行调试。
在后续章节中,我将通过我的方法带您逐步了解调试过程和找到问题根本原因。我希望这个过程能对Kubernetes网络问题故障排除有所帮助。
故障排查 - 第一阶段
在高层面上,我采取的方法包含以下两个步骤:
- 了解网络拓扑结构
- 从拓扑结构中识别有问题的部分
让我们从工作节点虚拟机ping IP:10.132.2.46,并跟踪网络栈中的流量:
[root@ocp-412-worker-1 core]# ping 10.132.2.46Linux会参考路由表来确定发送数据包的目的地。
[root@ocp-412-worker-1 core]# ip route get 10.132.2.46
10.132.2.46 dev ovn-k8s-mp0 src 10.132.2.2 uid 0因此,到pod IP的路由是通过设备ovn-k8s-mp0
让我们获取工作节点网络详细信息,并检索有关ovn-k8s-mp0设备的信息。
[root@ocp-412-ovn-worker-1 core]# ip r
default via 192.168.10.1 dev br-ex proto dhcp src 192.168.10.163 metric 48
10.132.0.0/14 via 10.132.2.1 dev ovn-k8s-mp0
10.132.2.0/23 dev ovn-k8s-mp0 proto kernel scope link src 10.132.2.2
169.254.169.0/29 dev br-ex proto kernel scope link src 169.254.169.2
169.254.169.1 dev br-ex src 192.168.10.163 mtu 1400
169.254.169.3 via 10.132.2.1 dev ovn-k8s-mp0
172.30.0.0/16 via 169.254.169.4 dev br-ex mtu 1400
192.168.10.0/24 dev br-ex proto kernel scope link src 192.168.10.163 metric 48
[root@ocp-412-ovn-worker-1 core]# ip a
[snip]
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master ovs-system state UP group default qlen 1000
link/ether 52:54:00:f9:70:58 brd ff:ff:ff:ff:ff:ff
3: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 32:7c:7a:20:6e:5a brd ff:ff:ff:ff:ff:ff
4: genev_sys_6081: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65000 qdisc noqueue master ovs-system state UNKNOWN group default qlen 1000
link/ether 3a:9c:a8:4e:15:0c brd ff:ff:ff:ff:ff:ff
inet6 fe80::389c:a8ff:fe4e:150c/64 scope link
valid_lft forever preferred_lft forever
5: br-int: <BROADCAST,MULTICAST> mtu 1400 qdisc noop state DOWN group default qlen 1000
link/ether d2:b6:67:15:ef:06 brd ff:ff:ff:ff:ff:ff
6: ovn-k8s-mp0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether ee:cb:ed:8e:f9:e0 brd ff:ff:ff:ff:ff:ff
inet 10.132.2.2/23 brd 10.132.3.255 scope global ovn-k8s-mp0
valid_lft forever preferred_lft forever
inet6 fe80::eccb:edff:fe8e:f9e0/64 scope link
valid_lft forever preferred_lft forever
8: br-ex: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 52:54:00:f9:70:58 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.163/24 brd 192.168.10.255 scope global dynamic noprefixroute br-ex
valid_lft 2266sec preferred_lft 2266sec
inet 169.254.169.2/29 brd 169.254.169.7 scope global br-ex
valid_lft forever preferred_lft forever
inet6 fe80::17f3:957b:5e8d:a4a6/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[snip]从上述输出可以看出,ovn-k8s-mp0接口的IP是10.132.2.2/23
让我们获取ovn-k8s-mp0接口的设备详细信息。
如下输出所示,这个接口是一个OVS实体。
[root@ocp-412-ovn-worker-1 core]# ip -d li sh dev ovn-k8s-mp0
6: ovn-k8s-mp0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether ee:cb:ed:8e:f9:e0 brd ff:ff:ff:ff:ff:ff promiscuity 1 minmtu 68 maxmtu 65535
openvswitch addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535ovn-k8s-mp0是一个OVS桥吗?
从下面的命令输出可以清楚看到,ovn-k8s-mp0不是一个OVS桥。工作节点上存在的只有两个桥:br-ex和br-int
[root@ocp-412-ovn-worker-1 core]# ovs-vsctl list-br
br-ex
br-int所以ovn-k8s-mp0是一个OVS端口。我们需要找出拥有这个端口的OVS桥。
从下面的命令输出可以清楚看到,ovn-k8s-mp0不是桥br-ex的OVS端口。
[root@ocp-412-ovn-worker-1 core]# ovs-ofctl dump-ports br-ex ovn-k8s-mp0
ovs-ofctl: br-ex: unknown port `ovn-k8s-mp0`从下面的命令输出可以清楚看到,ovn-k8s-mp0是一个OVS桥br-int的端口。
[root@ocp-412-ovn-worker-1 core]# ovs-ofctl dump-ports br-int ovn-k8s-mp0
OFPST_PORT reply (xid=0x4): 1 ports
port "ovn-k8s-mp0": rx pkts=1798208, bytes=665641420, drop=2, errs=0, frame=0, over=0, crc=0tx pkts=2614471, bytes=1357528110, drop=0, errs=0, coll=0总结一下,ovn-k8s-mp0是一个br-int** OVS桥上的端口。它也持有桥的IP,即**10.132.2.2/23
现在,让我们获取pod的网络配置详细信息。
必须知道pod网络命名空间才能确定pod网络详细信息。下面的命令通过IP找到pod网络命名空间。
[root@ocp-412-ovn-worker-1 core]# POD_IP=10.132.2.46; for ns in $(ip netns ls | cut -f 1 -d " "); do ip netns exec $ns ip a | grep -q $POD_IP; status=$?; [ $status -eq 0 ] && echo "pod namespace: $ns" ; done
pod namespace: c16c7a01-1bc5-474a-9eb6-15474b5fbf04一旦知道了pod网络命名空间,就可以找到pod的网络配置详细信息,如下所示。
[root@ocp-412-ovn-worker-1 core]# NS=c16c7a01–1bc5–474a-9eb6–15474b5fbf04
[root@ocp-412-ovn-worker-1 core]# ip netns exec $NS ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if4256: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UP group default qlen 1000
link/ether 0a:58:0a:84:02:2e brd ff:ff:ff:ff:ff:ff link-netns 59e250f6–0491–4ff4-bb22-baa3bca249f6
inet 10.132.2.46/23 brd 10.132.3.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::858:aff:fe84:22e/64 scope link
valid_lft forever preferred_lft forever
4257: vxlan1@if4257: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether ca:40:81:86:fa:73 brd ff:ff:ff:ff:ff:ff link-netns 59e250f6–0491–4ff4-bb22-baa3bca249f6
inet6 fe80::c840:81ff:fe86:fa73/64 scope link
valid_lft forever preferred_lft forever
[root@ocp-412-ovn-worker-1 core]# ip netns exec $NS ip r
default via 10.132.2.1 dev eth0
10.132.2.0/23 dev eth0 proto kernel scope link src 10.132.2.46所以eth0@if4256是pod的主网络接口。
让我们获取eth0设备的详细信息。
从下面的输出可以看出,pod网络命名空间中的eth0设备是一个veth设备。
[root@ocp-412-ovn-worker-1 core]# ip netns exec $NS ip -d li sh dev eth0
link/ether 0a:58:0a:84:02:2e brd ff:ff:ff:ff:ff:ff link-netns 59e250f6–0491–4ff4-bb22-baa3bca249f6
veth addrgenmode eui64 numtxqueues 8 numrxqueues 8 gso_max_size 65536 gso_max_segs 65535 tso_max_size 524280 tso_max_segs 65535 gro_max_size 65536众所周知veth设备以对的形式工作;一端在init(或root)命名空间中,另一端在(pod)网络命名空间中。
让我们在init命名空间中找到pod对应的veth设备对。
[root@ocp-412-ovn-worker-1 core]# ip a | grep -A1 ^4256
4256: 8b7266486ea2861@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue master ovs-system state UP group default
link/ether de:fb:3e:87:0f:d6 brd ff:ff:ff:ff:ff:ff link-netns c16c7a01–1bc5–474a-9eb6–15474b5fbf04所以,8b7266486ea2861@if2是init命名空间中的podveth设备端点。这个veth对连接了init和pod网络命名空间。
让我们找出veth设备端点的详细信息。
[root@ocp-412-ovn-worker-1 core]# ip -d li sh dev 8b7266486ea2861
4256: 8b7266486ea2861@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue master ovs-system state UP mode DEFAULT group default
link/ether de:fb:3e:87:0f:d6 brd ff:ff:ff:ff:ff:ff link-netns c16c7a01–1bc5–474a-9eb6–15474b5fbf04 promiscuity 1 minmtu 68 maxmtu 65535
veth
openvswitch_slave addrgenmode eui64 numtxqueues 4 numrxqueues 4 gso_max_size 65536 gso_max_segs 65535所以8b7266486ea2861@if2是一个OVS实体。转储OVS交换机详细信息将提供哪个OVS桥拥有此端口的详细信息。
如下输出所示,桥br-int拥有这个端口。
注意,使用ovs-vsctl命令是之前ovs-ofctl dump-ports <bridge> <port>命令的另一种选择。这是为了展示不同的命令可以帮助探索网络拓扑结构。
[root@ocp-412-ovn-worker-1 core]# ovs-vsctl show
[snap]
Bridge br-int
fail_mode: secure
datapath_type: system
[snip]
Port "8b7266486ea2861"
Interface "8b7266486ea2861"
[snap]所以br-int拥有在init命名空间中具有podveth端点的端口。回想一下,它还持有ovn-k8s-mp0端口。
让我们也获取pod的vxlan详细信息。
如下输出所示,vxlan隧道的远端点是IP192.168.10.201。这是pod虚拟机的IP。
[root@ocp-412-ovn-worker-1 core]# ip netns exec $NS ip -d li sh dev vxlan1
4257: vxlan1@if4257: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether ca:40:81:86:fa:73 brd ff:ff:ff:ff:ff:ff link-netns 59e250f6–0491–4ff4-bb22-baa3bca249f6 promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 555005 remote 192.168.10.201 srcport 0 0 dstport 4789 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535一个浮现的问题是数据包如何从eth0接口发送到vxlan1接口。
这是通过在网络命名空间中设置Linux流量控制(TC)在eth0和vxlan1之间镜像流量来实现的。这是从Kata容器的设计中已知的。然而,我认为在故障排除网络问题时检查TC配置是一种好的实践。
下面的输出显示了我环境中pod网络命名空间中设备配置的TC过滤器。
[root@ocp-412-ovn-worker-1 core]# ip netns exec $NS tc filter show dev eth0 root
filter parent ffff: protocol all pref 49152 u32 chain 0
filter parent ffff: protocol all pref 49152 u32 chain 0 fh 800: ht divisor 1
filter parent ffff: protocol all pref 49152 u32 chain 0 fh 800::800 order 2048 key ht 800 bkt 0 terminal flowid not_in_hw
match 00000000/00000000 at 0
action order 1: mirred (Egress Redirect to device vxlan1) stolen
index 1 ref 1 bind 1
[root@ocp-412-ovn-worker-1 core]# ip netns exec $NS tc filter show dev vxlan1 root
filter parent ffff: protocol all pref 49152 u32 chain 0
filter parent ffff: protocol all pref 49152 u32 chain 0 fh 800: ht divisor 1
filter parent ffff: protocol all pref 49152 u32 chain 0 fh 800::800 order 2048 key ht 800 bkt 0 terminal flowid not_in_hw
match 00000000/00000000 at 0
action order 1: mirred (Egress Redirect to device eth0) stolen
index 2 ref 1 bind 1eth0的出口被重定向到了vxlan1,而vxlan1的出口被重定向到了eth0
有了所有这些细节,就可以为参考和进一步分析绘制工作节点网络拓扑图。拓扑结构如下图所示。
 图片
图片
现在,让我们把重点转到pod虚拟机上。
请注意,pod虚拟机的设计是使用一个名为podns的固定pod网络命名空间。
以下输出显示了pod虚拟机的网络配置:
ubuntu@podvm-nginx-priv-8b726648:/home/ubuntu# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:e1:58:67 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.201/24 brd 192.168.10.255 scope global dynamic ens2
valid_lft 2902sec preferred_lft 2902sec
inet6 fe80::5054:ff:fee1:5867/64 scope link
valid_lft forever preferred_lft forever
root@podvm-nginx-priv-8b726648:/home/ubuntu# ip r
default via 192.168.10.1 dev ens2 proto dhcp src 192.168.10.201 metric 100
192.168.10.0/24 dev ens2 proto kernel scope link src 192.168.10.201
192.168.10.1 dev ens2 proto dhcp scope link src 192.168.10.201 metric 100
root@podvm-nginx-priv-8b726648:/home/ubuntu# iptables -S
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT以下输出显示了podns网络命名空间内的网络配置。
root@podvm-nginx-priv-8b726648:/home/ubuntu# ip netns exec podns ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: vxlan0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 7e:e5:f7:e6:f5:1a brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.132.2.46/23 brd 10.132.3.255 scope global vxlan0
valid_lft forever preferred_lft forever
inet6 fe80::7ce5:f7ff:fee6:f51a/64 scope link
valid_lft forever preferred_lft forever
root@podvm-nginx-priv-8b726648:/home/ubuntu# ip netns exec podns ip r
default via 10.132.2.1 dev vxlan0
10.132.2.0/23 dev vxlan0 proto kernel scope link src 10.132.2.46
root@podvm-nginx-36590ccc:/home/ubuntu# ip netns exec podns ip -d li sh vxlan0
3: vxlan0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 7e:e5:f7:e6:f5:1a brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 555005 remote 192.168.10.163 srcport 0 0 dstport 4789 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
root@podvm-nginx-priv-8b726648:/home/ubuntu# ip netns exec podns iptables -S
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPTvxlan隧道设置看起来正常。它显示了远程端点IP 192.168.10.163,这是工作节点虚拟机的IP。
此外,pod虚拟机中没有防火墙规则。
但是,你没有看到像在工作节点上一样的veth对。现在,浮现的一个问题是,没有veth对,init和podns网络命名空间之间如何进行通信。请注意,物理设备在init(root)命名空间中,vxlan设备在podns网络命名空间中。
感谢Stefano Brivio指出了使这种情况发生的Linux内核提交。
commit f01ec1c017dead42092997a2b8684fcab4cbf126
Author: Nicolas Dichtel <nicolas.dichtel@6wind.com>
Date: Thu Apr 24 10:02:49 2014 +0200
vxlan: add x-netns support
This patch allows to switch the netns when packet is encapsulated or
decapsulated.
The vxlan socket is openned into the i/o netns, ie into the netns where
encapsulated packets are received. The socket lookup is done into this netns to
find the corresponding vxlan tunnel. After decapsulation, the packet is
injecting into the corresponding interface which may stand to another netns.
When one of the two netns is removed, the tunnel is destroyed.
Configuration example:
ip netns add netns1
ip netns exec netns1 ip link set lo up
ip link add vxlan10 type vxlan id 10 group 239.0.0.10 dev eth0 dstport 0
ip link set vxlan10 netns netns1
ip netns exec netns1 ip addr add 192.168.0.249/24 broadcast 192.168.0.255 dev vxlan10
ip netns exec netns1 ip link set vxlan10 up这也有一个StackOverflow主题对此进行了解释。
这些细节为我们提供了对pod虚拟机网络拓扑的良好概述,如下图所示。
 图片
图片
让我们在vxlan0接口上运行tcpdump,看ICMP请求是否从工作节点接收。
如下输出所示,ICMP请求已接收,但没有响应。
root@podvm-nginx-priv-8b726648:/home/ubuntu# ip netns exec podns tcpdump -i vxlan0 -s0 -n -vv
tcpdump: listening on vxlan0, link-type EN10MB (Ethernet), capture size 262144 bytes
[snip]
10.132.2.2 > 10.132.2.46: ICMP echo request, id 20, seq 1, length 64
10:34:17.389643 IP (tos 0x0, ttl 64, id 27606, offset 0, flags [DF], proto ICMP (1), length 84)
10.132.2.2 > 10.132.2.46: ICMP echo request, id 20, seq 2, length 64
10:34:18.413682 IP (tos 0x0, ttl 64, id 27631, offset 0, flags [DF], proto ICMP (1), length 84)
10.132.2.2 > 10.132.2.46: ICMP echo request, id 20, seq 3, length 64
10:34:19.002837 IP (tos 0x0, ttl 1, id 28098, offset 0, flags [DF], proto UDP (17), length 69)
[snip]现在,让我们总结一下情况。
通过这个练习,你对工作节点和pod虚拟机的网络拓扑有了很好的理解,隧道的设置看起来也没有问题。你也看到ICMP数据包被pod虚拟机接收,没有软件防火墙阻止数据包。那么下一步该做什么?
继续阅读以了解下一步该做什么:-)
故障排查 - 第二阶段
我使用wireshark分析了来自工作正常(常规Kata)设置的tcpdump捕获。Wireshark图形界面可以方便地理解通过tcpdump捕获的网络跟踪。
在跟踪中没有观察到ARP请求和响应。但是,工作节点上的ARP表被填充,ARP表使用pod网络命名空间中的eth0设备的MAC(在工作节点上),而不是pod虚拟机上的podns命名空间中的vxlan0设备的MAC。
? (10.132.2.46) at 0a:58:0a:84:02:2e [ether] on ovn-k8s-mp00a:58:0a:84:02:2e是工作节点上pod网络命名空间中eth0接口的MAC,而7e:e5:f7:e6:f5:1a是pod虚拟机上podns命名空间中的vxlan0接口的MAC。
这是问题的原因 - 从工作节点无法访问pod IP。ARP条目应指向pod虚拟机上podns命名空间中的vxlan0设备的MAC(即7e:e5:f7:e6:f5:1a)。
事后看来,我本该首先查看ARP表条目。下次遇到类似问题我一定会这么做;)
解决方案
Stefano Brivio的一个小技巧解决了这个问题。在pod虚拟机的vxlan0接口上使用与工作节点上pod的eth0接口相同的MAC地址可以解决连接问题。
ip netns exec podns ip link set vxlan0 down
ip netns exec podns ip link set dev vxlan0 address 0a:58:0a:84:02:2e
ip netns exec podns ip link set vxlan0 up最终的网络拓扑结构如下所示。
 图片
图片
结论
调试Kubernetes集群中的网络问题并非易事。然而,通过明确的方法、专家的帮助和公开可用的资料,找到根本原因和修复问题是可能的。在这个过程中获得乐趣并掌握知识。
我希望这篇文章对你有帮助。
以下是在我的故障排除练习中非常有用的参考资料列表:
- https://learnk8s.io/kubernetes-network-packets
- https://programmer.help/blogs/practice-vxlan-under-linux.html
- https://www.man7.org/linux/man-pages/man7/ovn-architecture.7.html
- https://developers.redhat.com/articles/2022/04/06/introduction-linux-bridging-commands-and-features#vlan_tunnel_mapping
- https://www.tkng.io/cni/flannel/
- https://access.redhat.com/documentation/en-us/openshift_container_platform/3.4/html/cluster_administration/admin-guide-sdn-troubleshooting#debugging-local-networking