一、背景
表格和表单在前端里面是最复杂的两类需求,在BI工具平台上,这2类组件需求更多,并且需要实现一些特有的交互展示。目前在敏捷BI平台上进行报表配置,表格类组件的使用占比达到了1/3,在可视化组件库里使用范围很广。为了满足不同的数据分析场景,表格组件主要分为分组表、交叉表、明细表三种类型,其中又以交叉表功能最为丰富强大。随着敏捷BI的业务的发展,交叉表组件也经历了多次设计改版以支持高性能的数据渲染和个性化的展示配置。
术语注解
- 【敏捷BI】
专为 vivo 生态用户量身打造的 自助式 BI 平台,提供从数据接入、数据准备、到数据分析、可视化应用、数据管理的一站式数据解决方案,同Quick BI,FineBI。 - 【图表类型】
图表是数据视觉化表示的特殊方式。表示数据的方法有很多,如使用不同的符号、形状和排列,我们把这些称之为图表的类型。一些图表类型你比较熟悉,如条形图、饼图、折线图,但其他类型你可能就很少见了,如桑基图、树图、等值线图的地图。 - 【交互方式】
交互式可视化允许您修改,操作和探索计算机显示的数据。绝大多数交互式可视化系统在计算机网络上,但越来越多出现在平板电脑和智能手机上。相比之下,静态可视化只显示单一的、非交互数据,它通常是为了打印和在屏幕上显示。 - 【度量值】
表示数值的规模和范围。度量通常以间隔表示(10、20、30等等),代表度数字的单位,如价格、距离、年,或百分比。 - 【指标】
同度量,表示具体某项值,单个值本身没有任何业务意义,一般需要对应的指标口径解释,才会具有业务价值。
二、交叉表介绍
交叉表(Cross Tabulations)是一种常用的由 行、列、汇总字段 三个元素组成分类汇总表格。利用交叉表查询数据非常直观明了,在进行数据分析中也被广泛应用。这里牵涉到另外一个概念即分组报表,分组报表是所有报表当中最普通,最常见的报表类型,也是所有报表工具都支持的一种报表格式。从一般概念上来讲,分组报表就是只有纵向的分组,传统的分组报表制作方式是把报表划分为条带状,用户根据一个数据绑定向导指定分组,汇总字段,生成标准的分组报表。交叉表有多列查询能力、分类汇总、多角度排序、交互式分析等特性。

三、架构演变历程
为了提高交叉表的数据渲染性能和功能扩展能力,敏捷BI的表格组件经历了三次的设计升级。最开始用的jQuery拼接表格方式实现,随着组件化方案的推行,采用了组件化的方式实现升级,随着业务的发展,用多维度、多指标交叉分析场景越来越多了,尤其是通过交叉表进行分析时,大数据量出现了渲染崩溃等问题,所以我们最后通过微前端方式实现。 下面我们从开发难度,性能,功能扩展性,学习成本等方面的调研来讲解对底层表格的升级实践。

3.1 V1版表格
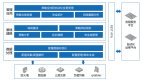
敏捷BI平台第一版表格,技术栈是基于jQuery+DIV的方式实现的。表格拼接属于jQuery时代的常见开发风格,这种方式,代码可维护性会非常差,很容易会出现标签不匹配的情况,不带缩进,调试起来也比较费劲。这个版本的表格组件支持的业务场景主要是数据的基本展现,无法满足用户对表格的数据分析的需求。
架构设计
 图片
图片
// 简单的拼接代码demo
function createTable() {
var data = new Array();
data.push('<table border=1><tbody>');
for (var i = 0; i < 2000; i++) {
data.push('<tr>');
for (var j = 0; j < 5; j++) {
data.push('<td>' + i + ',' + j + '</td>');
}
data.push('</tr>');
}
data.push('</tbody><table>');
document.getElementById('table1').innerHTML = data.join('');
}3.2 V2版表格
随着系统整体架构升级,前后端分离的推进,我们从原生的table组件迁移到Vue组件化上,开发了V2版表格组件。 平台的整体架构全面迁移到vue+ant-design-vue上面。
1. 功能拓展
鉴于ant-design-vue上正好有table组件,对此我们对比了antd的table组件和element的table组件。2 种表格对比来看,ant-design-vue参照ant.design的React版开发出来,配置相对element更丰富,考虑到本身复杂场景支持性,更适合深度定制,最终选择了ant.design的vue版本。

V2版的表格主要支持这几类场景配置(条件格式,合计行/列,单元格/行样式/内容定制等):
业务场景&具体实现
(1)数据展示
整体就是根据不同情况设置不同的column的字段,另外为了达到点击交互下,能够获取业务的数据,需要在column上挂一些冗余数据,这样会让column的数据信息很庞大。
columns是一个tree结构,这里采用的是dfs遍历,depth标识层级,item, itemType就是冗余的数据信息,在处理业务的时候会用到。


(2)数据排序

(3)数据过滤

(4)单元格自定义渲染

(5)多级表头定制
这个实现难点主要在于把已有的列如何放到新增的表头里,保持树形children结构具体实现代码也比较复杂,总共80行。
 图片
图片

(6)条件格式渲染(条形图,热力图)
根据设定的条件,定制表格内单元格内容的样式

(7)合计行/列配置
添加合计列和行,内置min,max,avg,sum表达式,支持自定义简易字段表达式运算这个功能难点在于合计列与行交叉的场景,也就是如何计算合计列的合计行。

2. 架构设计

3. 渲染优化
这个阶段的交叉表,在功能上已经能够满足绝大多数分析场景,但是一些数据量大的表格反馈渲染白屏时间过长,经常会出现浏览器崩溃,表格的性能面临新的挑战。另外表格在渲染时,CPU会占满,导致其他图表也会卡住等待,形成假死的现象。我们通过分析大数据表格渲染流程,发现有30%的时间会花销在数据适配,因此我们思考能不能把数据计算部分隔离出来,计算的时候,不阻塞渲染主进程,这样的话,浏览器渲染就可以处理其他的渲染任务。在做性能优化调研时,我们引入了service worker,worker在处理cpu密集型任务有独特的优势,所以我们把数据预处理的过程交给了Worker。之前没有使用worker时,我们前端逻辑会处理很多数据初始化和计算的操作,对于一个数据量很大的表格,会导致渲染卡顿2~3s,有些个别情况会导致浏览器崩溃的现象。
Worker原理和定义:
W3C 组织早在 2014 年 5 月就提出过 Service Worker 这样的一个 HTML5 API ,主要用来做持久的离线缓存。service worker是浏览器的一个高级特性,本质是一个web worker,是独立于网页运行的脚本。
web worker这个api被造出来时,就是为了解放主线程。因为,浏览器中的JavaScript都是运行在单一个线程上,随着web业务变得越来越复杂,js中耗时间、耗资源的运算过程则会导致各种程度的性能问题。
而web worker由于独立于主线程,则可以将一些复杂的逻辑交由它来去做,完成后再通过postMessage的方法告诉主线程。service worker则是web worker的升级版本,相较于后者,前者拥有了持久离线缓存的能力。
3.3 V3版表格
在开发V2表格时,我们意识到数据处理部分不应该交给前端,列拼接上掺杂了太多的业务场景处理,另外渲染性能和崩溃问题急需解决,对此我们进行了V3版本迭代,提前对表格版本进行了技术升级,为之后的新一批列汇总行汇总,分组小计等高级交叉分析需求做好技术储备。
1. 技术选型
我们对比了react,vue及canvas生态有代表性的表格组件。综合三者优劣势最终确定了基于react的table组件。

S2:https://github.com/antvis/S2
ali-react-table:
https://github.com/alibaba/ali-react-table
vxe-table:
https://github.com/x-extends/vxe-table/tree/v2
vxe-table设计初衷是解决单元格编辑的问题,主要用于大量增删改查的场景,性能不是它唯一的目标;S2是建立在电子表格需求上的,对筛选、排序、搜索、复制、框选、聚合分析都有诉求。
同时需要在大数据量下保持高性能,解决之前商业软件版本实现的性能问题和拓展性问题,所以它覆盖的场景更全更复杂,但是它的缺点就是定制型不强,不太适合我们自身的业务。
所以最终我们选择了ali-react-table,它本身体积小,在基础能力都满足的情况下,扩展新功能也很容易,而且在大数据量渲染下有高性能的优势。
2. 架构设计
后端接口返回数据和配置部分,基于渲染模型:左树 + 上树 => 表格,根据配置生成左树leftTree和上树topTree,构造数据源,参照了ant-design的Table组件数据源构造的流程,与自身的pipeline插件机制结合,实现了表格的交互操作(排序,筛选,分页)。
由于本项目里接入了微前端架构,采用了loadApp的方式实现了异构应用混合开发:
 图片
图片
运作流程图如下:

3. 升级实践
(1)架构升级:

(2)底层渲染:
虚拟滚动:长列表渲染受制于浏览器本身限制,在大量DOM下,会达到浏览器本身的渲染瓶颈,在这种情况下,虚拟滚动可以解决这种渲染问题,它是一种按需渲染的理念的体现。所以虚拟列表是一种根据滚动容器元素的可视区域来渲染长列表数据中某一个部分数据的技术。
大致原理如下图:

我们发现长列表在展示时,用户只会关注可视区域,其他非可视区域部分,我们可以把已经渲染的DOM销毁,不需要立即渲染的DOM延后。所以优化策略就是只渲染可见区域的内容。
在滚动事件触发后,根据滚动 Offset 调整相应渲染的内容即可。在用户看来,还是一个完整的长列表。这种懒加载的方式,和早期页面图片资源懒加载和非必须资源异步加载属于同一种思路。
在新版版本里,ali-react-table自带了虚拟滚动的特性,在大列表下,框架会自动开启,可以明显提升表格渲染性能和滚动的性能。
四、同类产品对比
4.1 技术架构对比
1. Quick BI
① 架构设计

② 技术实现
- 使用原生div和flex布局,不使用原生table表格
- 列宽,固定列,固定表头等表格不好实现的问题,都易实现,渲染性能也较好
- 有2个版本的表格,旧版表格使用table,在这种情况下,性能,复杂交互,分组都存在瓶颈,这一点和我们类似,新老版本的表格同时在线上应用
- 虚拟滚动支持横向,纵向滚动
③ 优劣势
- ali-react-table不维护了,源码不太复杂,可以二次迭代开发;基本满足交叉表所有功能;大数据量下渲染高性能
- 接口数据略冗余
④ 备注
- 数据结构明确行维、列维、指标列数据;
- 数据汇总和小计是存放在后端
2. 敏捷BI
① 架构设计
 图片
图片
② 技术实现
- 使用table布局
- 使用position:sticky实现固定列;固定表头使用独立的单表头表格模拟,这里需要强制table设置列宽,保证列对齐
- 支持横向,纵向虚拟滚动,在10w列下依然可以正常渲染
- 在ali-react-table基础上扩展了按维度合并,表头筛选等feature
③ 优劣势
- flex布局灵活,不受表格本身布局限制,易实现固定列和表头,列宽;canvas开发成本较高,bug不好调试
- 接口数据更精简
④ 备注
- 数据结构不明确,需要对二维数组转换,存在一定的预处理逻辑;
- 数据结构存在冗余现象
4.2 应用场景对比
以实际测试为准
1. Quick BI
业务场景
(1)字段配置
- 行:数据集的维度字段拖拽到行选择区
- 列:数据集里的维度或者度量字段拖拽到列选择区
- 过滤器:数据集字段拖拽到过滤器选择区,对字段进行筛选
(2)样式配置
- 标题与卡片:设置标题样式
- 备注和尾注:设置图表备注和尾注内容
- 组件容器:设置内边距和背景色,圆角
- 展示型配置:设置主题,表头样式,内容样式,冻结列,序号等配置
- 功能型配置:条件格式配置,针对字段满足特定条件下突出显示配置的样式
- 总计配置:支持列汇总和行汇总,行总计和行小计,列总计和列小计
(3)高级配置
- 联动:图表里的字段与其他图标关联
- 跳转:图表字段跳转传值
技术实现
- 实现使用原生,未使用第三方库
- 自定义主题使用主色编辑
- 拖拽方式交互
2. 网易有数
业务场景
- 没有复杂的交叉表场景,只支持普通明细表
- 配置方式主要包括主题,表头,内容的字体样式,背景,对齐等样式
- 支持下钻,字段跳转
- 数据集字段支持维度层级和组的概念
- 没有虚拟滚动
技术实现
- 内部使用table表格实现
- 主题配置支持上传主题json文件
3. 敏捷BI
(1)字段配置
- 行维:数据集维度字段放置区
- 列维:数据集维度字段放置区
- 指标:数据集指标字段
(2)图表属性和图表样式配置
- 支持条件格式,自定义代码样式嵌入,主题配置
(3)字段过滤
- 使用字段过滤数据
技术实现
- 最开始使用smooth-dnd库,来实现从数据集字段拖拽到行列、指标区
- 因为smooth-dnd有性能问题,不再维护等问题,就废弃掉了,使用原生的拖拽实现
- 主题使用在线代码编辑主题,基于codemirror在线代码,接入css variables,实时应用,不需要刷新
4.3 部分核心代码实现
应用场景① :表头筛选
代码实现

应用场景②:按维度合并
代码实现

4.4 渲染性能对比
1. Quick BI
(1)数据量级 <50列
- 接口耗时300ms 接口大小<5kb
- 渲染耗时 < 1s
注:数据量不是很大的情况下,数据加载忽略不计,合入到数据渲染时间,差别不大
(2)数据量级 ≥ 200列
- 接口耗时1.88s 接口大小<10kb
- 表格渲染 < 3s
注:数据量很大的情况下,数据加载需要单独计入时间
(3)数据量级 > 1W列
极端情况下,表格渲染崩溃
 图片
图片
2. 敏捷BI
(1)数据量级 <50列
- 接口耗时250ms 接口大小~100kb
- 渲染耗时 < 1s
(2)数据量级 ≥ 200列
- 接口耗时300ms 接口大小~300kb
- 渲染耗时 <3s
(3)数据量级 > 1W列
- 接口耗时2s 数据大小2M
- 渲染耗时~10s
4.5 总结
网易有数表格组件较为简单,只有简单的数据展示和排序筛选,适用于明细数据展示场景。
Quick BI表格和敏捷BI在交互,可视化能力,业务场景上都保持着同样的功能,底层实现 Quick BI采用原生DIV+Flex布局模拟表格实现,在渲染上比表格会有渲染的优势,这点是浏览器自身渲染机制决定,我们内部实现需要满足极端数据量下数据展示,所以特定做了横向的虚拟列表优化,这种场景看业务需求,否则表格会过于复杂,得不偿失。
表格渲染性能基本与Quick BI性能相当,极端情况下,敏捷BI依旧可以正常渲染,这点优于Quick BI。
五、规划
- 数据预处理部分不由前端处理,交给后端,和后端协调好返回的数据结构,直接返回;
- 表格扩展的功能与表格耦合严重,表格渲染不够纯净;
- 开发一个Headless UI,不依赖渲染框架,提供一个数据适配层,同时支持在Vue3生态上使用。