译者 | 布加迪
审校 | 重楼
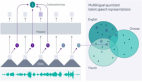
 图1. OpenAI Whisper模型的工作原理图
图1. OpenAI Whisper模型的工作原理图
在这个日益数字化的世界,将语音转换成文本的需求变得越来越重要。无论为了可访问性、内容创建、数据分析还是其他用途,将口语转换成书面语都是一个需要有效解决方案的问题。OpenAI开发的人工智能模型Whisper就能做到这一点:将口语转化成易于理解的文本。
本文将逐步介绍Whisper是什么、它是如何工作的以及如何有效使用它。目前Whisper在AIModels.fyi排名第19位,这款功能强大的工具可以在各种应用中发挥巨大作用。本文还将探讨如何使用AIModels.fyi找到适合您独特需求的类似模型。
Whisper模型简介
由OpenAI开发的AI模型Whisper旨在将音频文件中的语音转换为文本。其应用非常广泛,从生成视频字幕到转录采访或会议文字,不一而足。Whisper的运行次数超过了200万人次,在同类产品中脱颖而出,是一种可靠且受欢迎的模型。
该模型接受音频输入并将其转录成书面文字,有效地弥合了口语和书面语之间的差距。此外,它支持大量语言,因而成为适合多语言项目的出色工具。关于该模型的更多详细信息可以在详情页面上找到。
了解Whisper模型的输入和输出
在深入研究Whisper模型的使用之前,了解模型的输入和输出很重要。
输入
Whisper的主要输入是一个音频文件,它对其进行处理并转录成文本。额外的输入参数允许您定制模型的操作方式:
- model string:允许您从不同版本的Whisper模型中选择。
- transcription string:允许您选择转录的格式,有纯文本、srt或vtt等选项。
- translate boolean:使您能够将文本翻译成英语。
- language string:允许您指定音频中所说的语言。
- temperature number:该参数控制模型输出的“创造性”。
- suppress_tokens string:您不希望模型输出的token id列表。
输出
模型输出含有已转录文本的对象,带有几个字段:
- segments:转录内容分成几个片段。
- srt_file & txt_file:转录结果可以以这些格式获得。
- translation:如果启用了翻译选项,这里提供翻译后的文本。
- transcription:这是最终的已转录文本。
- detected_language:模型检测到的语言。
我们已了解了模型的输入和输出,不妨看看如何使用它来解决我们的转录问题!
使用Whisper模型将语音转录成文本
无论您是喜欢动手操作的程序员,还是偏爱交互性较强的演示方法,使用Whisper模型都简单又直接。
第1步:身份验证
首先,需要安装Replicate Node.js客户软件,并使用API令牌进行身份验证。这允许您以编程方式与Whisper模型进行交互。
第2步:运行模型
完成身份验证后,您可以用音频输入来运行模型:
您还可以设置预测完成后所调用的Web钩子(webhook),这适用于异步处理:
更进一步:使用AIMmodels.fyi找到其他音频到文本模型
也许您想将Whisper与其他模型进行比较,或者探究同一问题领域的其他模型。怎样才能找到它们?AIModels.fyi正是满足这个用途的上佳资源,它有一个完全可搜索和可过滤的数据库,列有来自各种平台的AI模型。
第1步:访问AIModels.fyi
进入到AIModels.fyi,开始寻找类似的模型。
第2步:使用搜索栏
使用页面顶部的搜索栏,搜索具有特定关键字的模型,比如“audio-to-text”或“transcription”。这将显示相关模型列表。
第3步:筛选结果
使用搜索栏后,您可以通过使用页面左侧的过滤器进一步缩小结果范围。可以根据各种标准来筛选和搜索模型,包括如下:
- 平台:托管模型所用的平台,比如OpenAI和Hugging Face等。
- 创建者:模型背后的创建者或组织。
- 成本:使用模型的价格范围。
- 描述:该模型的功能和用途。
第4步:探究模型细节
一旦您找到了一个感兴趣的模型,点击它来查看更多的细节。您能够看到阐述全面的模型特点,包括其输入和输出、性能指标和用例。
结语
无论您是经验丰富的开发人员还是AI领域的新手,OpenAI的Whisper都是一个易于使用且功能强大的工具,可以将语音转换成文本。若结合AIModels.fyi之类的资源,现在比以往任何时候更容易找到适合您独特项目需求的完美模型。立即开始探究起来吧!
原文标题:Converting Speech into Text with OpenAI's Whisper Model,作者:Mike Young