












译者 | 陈峻
审校 | 重楼
您也许没有注意到,数据建模错误往往是导致系统性能出现问题的根本原因之一。人们往往简单地认为,只需根据应用的访问模式,对NoSQL数据建模即可。然而,事实上,在真正处理对于性能极其敏感的工作负载时,应用就很容易出现性能瓶颈。
例如:如果您的数据建模从根本上就效率低下的话,那么一旦被扩展到某个临界点,应用的性能就会受到严重影响。即使您在强大的基础架构上采用了最快的数据库,也无法充分利用其潜力。本文将和您探讨三种影响NoSQL数据库性能的最常见建模方式,以及避免或解决这些问题的技巧。
不处理大分区(Large Partition)
在您的开发团队着手扩展分布式数据库时,大分区通常会随之出现。此处的大分区是指:那些可能会在整个集群的副本中,产生性能问题的过大分区。具体而言,它往往取决于:
- 延迟预期:通常,分区越大,检索所需的时间也就越长。为此,我们需要考虑页面的大小、以及完整扫描一个分区所需的客户端与服务器往返交互的次数。
- 平均载荷大小:较大的载荷通常会导致较高的延迟。毕竟,它们需要更多的服务器端处理时间,来进行序列化和反序列化,同时也会产生更高的网络数据传输开销。
- 工作负载需求:有时候,一些工作负载需要比平时用到更大的载荷。例如,Web3区块链公司可能会将多个交易存储为单键之下的BLOB,其每个键的大小就很容易超过1兆字节。
- 从分区中读取数据的方式:例如,时间序列用例通常会包含时间戳聚类组件。在这种情况下,与扫描整个分区相比,仅从特定时间窗口读取的数据就少得多。
鉴于上述方面,下表展示了大分区在不同载荷大小(如1、2和4KB)下的影响。
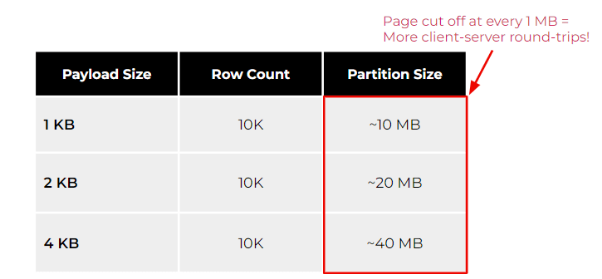
可以看出,在相同行数的情况下,负载越高,分区就越大。不过,如果您的应用需要经常扫描整体分区的话,那么请注意对数据库予以限制,以防止内存被无限制地消耗。例如,ScyllaDB在每隔1MB就会切分开不同页面。这正是为了防止系统内存的耗尽。其他数据库(甚至是关系型数据库)也有类似的保护机制,以防止无限制的查询,导致数据库资源的枯竭。
若要使用ScyllaDB检索大小为4KB和1万行数的负载,您需要检索至少40页,才能通过单次查询扫描完整个分区。起初,这似乎不是什么大问题。但是,随着时间的推移,客户端的整体延迟会逐渐受到影响。
另一个值得考虑的因素是:在ScyllaDB和Cassandra等数据库中,写入数据库的数据往往会被存储在提交日志(commit log)和名为“memtable”的内存数据结构中。
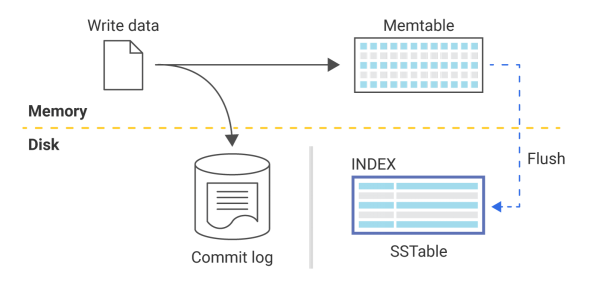
如上图所示,提交日志是一个提前写入的日志,除非服务器崩溃或服务中断,否则它不会被真正地读取到。由于memtable存在于内存中,因此最终它会被填满。因此,为了释放内存空间,数据库会将内存表刷到磁盘上。这一过程会产生排序字符串表(Sorted Strings Tables,SSTables),这就是数据被持久化的过程。
那么这些又与大分区有何关系呢?实际上,SSTables有着一些需要在数据库启动时,保存在内存中的特定组件。它们可以确保读取效率,并在查找数据时尽量减少存储磁盘I/O的浪费。因此,当您拥有超大分区时(例如,2.5Terabyte的分区),这些SSTable组件就需要减少沉重的内存压力,从而缩小数据库的缓存空间,进一步限制延迟。
具体而言,我们该如何通过数据建模,来解决大分区问题呢?通常,我们可以从主键入手。毕竟主键决定了数据在集群中的分布方式,可以被用来提高性能和资源利用率。如您所知,一个好的分区键应该具有基数性(Cardinality)且能够大致均匀地分布。例如,User Name、User ID或Sensor ID等基数性较高的属性,都可能是很好的分区键。而像“State(州)”这样的属性则不太合适,毕竟像加利福尼亚州和德克萨斯州这样的州,可能会比怀俄明州和佛蒙特州之类人口较少的州,拥有更多的数据。
让我们来看一个例子。下表可被用于带有多个传感器的分布式空气质量监测系统:
CREATE TABLE air_quality_data (
sensor_id text,
time timestamp,
co_ppm int,
PRIMARY KEY (sensor_id, time)
);由于time是该表格的聚类键(clustering key),因此不难想象,每个传感器的分区可能会变得非常大,尤其是在每几毫秒就收集一次数据的情况下。长此以往,这个看似无害的表最终会变得大到无法使用。而在本例中,我们只需要约 50 天。
一个标准的解决方案是修改数据模型,以减少每个分区键的聚类键数量。下面,让我们来看看更新后的air_quality_data表:
CREATE TABLE air_quality_data (
sensor_id text,
date text,
time timestamp,
co_ppm int,
PRIMARY KEY ((sensor_id, date), time)
);完成更改后,一个分区仅保存一天内收集的数据值。这样就不容易溢出了。由于它允许我们控制分区中存储的数据量,因此这种技术被称为“分桶(Bucketing)”。如果您对此方面感兴趣的话,请参考链接--https://discord.com/blog/how-discord-stores-trillions-of-messages,以了解如何应用分桶技术,来避免出现大分区。
引入热点(Hot Spot)
如果您有一个大分区(即存储了绝大部分的数据集),那么您的应用访问模式,很可能会更频繁地访问该分区。因此,当有问题的数据访问模式,导致集群中的数据访问方式失衡时,就会出现热点。此类热点很可能会给大分区带来副作用。而其中一个罪魁祸首就源于:应用程序未能在客户端采取任何限制,以至于允许“租户”侧对给定的键进行“大肆”访问。
例如,某个消息应用中的机器人经常在某个频道中发送大量信息。那么,不稳定的客户端配置就会以重试风暴(Retry Storms)的形式引入热点。也就是说,客户端在尝试着查询特定数据时,会在数据库超时之前,以及在数据库仍在处理上一次查询的同时,进行反复地重试。
通过监控仪表盘,您可以轻松地找到集群中的热点。如下图所示,该仪表盘显示了读取量过大的20个碎片。
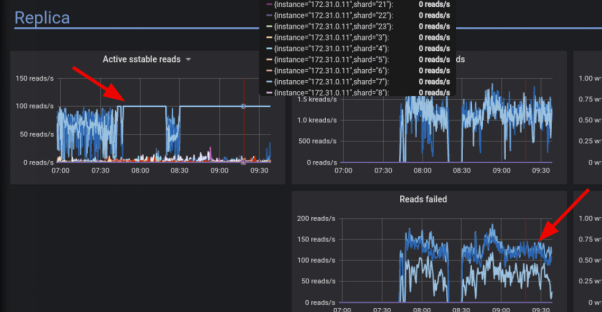
再比如,下图展示了三个利用率较高的分片,它们都与针对键空间配置的三个复制因子有关。

由上图可知,大量的读写传播,给碎片 7 带来了更高的负载。
那么,我们该如何解决热点问题呢?首先,我们可以在其中一个受影响的节点上,对最常被命中的键进行取样。同时,您也可以使用概率跟踪(Probabilistic Tracing)等跟踪工具,来分析有哪些查询会命中哪些分片,以便后续采取行动。一旦发现了热点,我们就应当考虑如下方面:
- 审查应用程序的访问模式。您可能会发现前面提到的桶技术等需要改变的数据模型。如果需要重新排序,您可以使用诸如Snowflake之类的单调递增组件,或是采用并发限制器,来限制不良因素。
- 指定每个分区的速率限制,以便数据库拒绝那些访问同一分区的查询。
- 确保客户端超时高于服务器端超时,以防止客户端在服务器有机会处理之前,不断地发出重试查询(也就是“重试风暴”)。
滥用集合
虽然不常被使用,但是团队往往无法恰当地使用集合。集合是指那些用于存储和规范化相对较小的数据量。由于被存储在单个单元格中,因此它们序列化与反序列化的成本极高。
在使用集合时,我们可以定义相关问题字段为:冻结和非冻结。冻结的集合只能作为一个整体被写入,不能向其中添加或删除元素。而非冻结的集合则可以被追加,而这正是人们最常滥用的集合类型。而且,更糟糕的是,人们甚至可以嵌套集合。比如:让一个映射包含另一个映射,而后者又包含了一个列表等结构。
由于滥用集合会比大分区更快地带来性能问题,因此集合不应过大。例如,我们创建了一个简单的键/值(key:value)表,其中的键是sensor_id,值是在一段时间内记录到的样本集合。那么一旦我们开始捕获数据,性能就会逐渐下降。
CREATE TABLE IF NOT EXISTS {table} (
sensor_id uuid PRIMARY KEY,
events map<timestamp, FROZEN<map<text, int>>>,
)下图的监控快照显示了,该应用同时向集合追加多个项目时发生的情况。
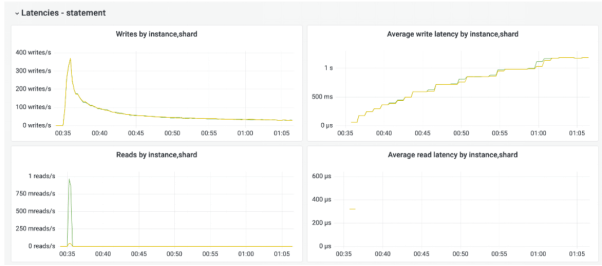
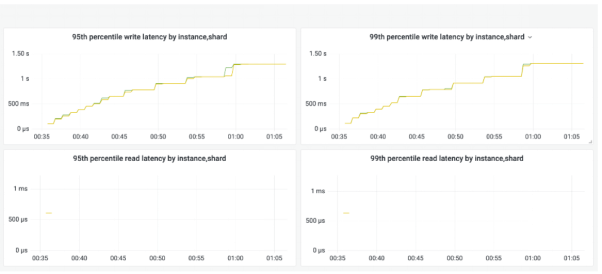
如您所看,在整体吞吐量降低的同时,99%的延迟却在增加。其根本原因就可能来自如下方面:
- 集合单元以分类矢量的形式存储在内存中。
- 添加元素需要合并两个新旧集合。
- 添加元素的成本与整个集合的大小成正比。
- 树(Tree,非矢量Vector)虽然可以提高性能,但是会降低小型集合的效率。
回到上述例子,由于不再需要向其追加数据,我们的解决方法是将时间戳移至聚类键,并将映射转换为冻结的集合。如下代码所示,如下面这样非常简单的更改,就能大幅提高用例的性能。
CREATE TABLE IF NOT EXISTS {table} (
sensor_id uuid,
record_time timestamp,
events FROZEN<map<text, int>>,
PRIMARY KEY(sensor_id, record_time)
)译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:NoSQL Data Modeling Mistakes that Ruin Performance,作者:Felipe Cardeneti Mendes



















