













如果想让机器人帮助你,你通常需要下达一个较为精准的指令,但指令在实际中的实现效果不一定理想。如果考虑真实环境,当要求机器人找某个特定的物品时,这个物品不一定真的存在当前的环境内,机器人无论如何也找不到;但是环境当中是不是可能存在一个其他物品,它和用户要求的物品有类似的功能,也能满足用户的需求呢?这就是用 “需求” 作为任务指令的好处了。
近日,北京大学董豪团队提出了一个新的导航任务 —— 需求驱动导航(Demand-driven Navigation,DDN),目前已被 NeurIPS 2023 接收。在这个任务当中,机器人被要求根据一条用户给定的需求指令,寻找能够满足用户需求的物品。同时,董豪团队还提出了学习基于需求指令的物品属性特征,有效地提高了机器人寻找物品的成功率。

- 论文地址:https://arxiv.org/pdf/2309.08138.pdf
- 项目主页:https://sites.google.com/view/demand-driven-navigation/home
任务说明
具体地说,在任务的一开始,机器人会收到一条需求指令,比如 “我饿了”,“我渴了”,然后机器人就需要在场景内寻找一个能满足该需求的物品。因此,需求驱动导航本质上还是一个寻找物品的任务,在这之前已经有类似的任务 —— 视觉物品导航(Visual Object Navigation)。这两个任务的区别在于,前者是告知机器人 “我的需求是什么”,后者是告知机器人 “我要什么物品”。

将需求作为指令,意味着机器人需要对指令的内容进行推理和探索当前场景中的物品种类,然后才能找到满足用户需求的物品。从这一点上来说,需求驱动导航要比视觉物品导航难很多。虽说难度增加了,但是一旦机器人学会了根据需求指令寻找物品,好处还是很多的。比如:
- 用户只需要根据自己的需求提出指令,而不用考虑场景内有什么。
- 用需求作为指令可以提高用户需求被满足的概率。比如当 “渴了” 的时候,让机器人找 “茶” 和让机器人找 “能解渴的物品”,显然是后者包含的范围更大。
- 用自然语言描述的需求拥有更大的描述空间,可以提出更为精细、更为确切的需求。
为了训练这样的机器人,需要建立一个需求指令到物品的映射关系,以便于环境给予训练信号。为了降低成本,董豪团队提出了一种基于大语言模型的、“半自动” 的生成方式:先用 GPT-3.5 生成场景中存在的物品能满足的需求,然后再人工过滤不符合要求的。
算法设计
考虑到能满足同一个需求的物品之间有相似的属性,如果能学到这种物品属性上的特征,机器人似乎就能利用这些属性特征来寻找物品。比如,对于 “我渴了” 这一需求,需要的物品应该具有 “解渴” 这一属性,而 “果汁”、“茶” 都具有这一属性。这里需要注意的是,对于一个物品,在不同的需求下可能表现出不同的属性,比如 “水” 既能表现出 “清洁衣物” 的属性(在 “洗衣服” 的需求下),也能表现出 “解渴” 这一属性(在 “我渴了” 的需求下)。
属性学习阶段
那么,如何让模型理解这种 “解渴”、“清洁衣物” 这些需求呢?注意到在某一需求下物品所表现出的属性,是一种较为稳定的常识。而最近几年,随着大语言模型(LLM)逐渐兴起,LLM 所表现出的对人类社会常识方面的理解让人惊叹。因此,北大董豪团队决定向 LLM 学习这种常识。他们先是让 LLM 生成了很多需求指令(在图中称为 Language-grounding Demand,LGD),然后再询问 LLM,这些需求指令能被哪些物品满足(在图中称为 Language-grounding Object,LGO)。

在这里要说明,Language-grounding 这一前缀强调了这些 demand/object 是可以从 LLM 中获取而不依赖于某个特定的场景;下图中的 World-grounding 强调了这些 demand/object 是与某个特定的环境(比如 ProcThor、Replica 等场景数据集)紧密结合的。
然后为了获取 LGO 在 LGD 下所表现出的属性,作者们使用了 BERT 编码 LGD、CLIP-Text-Encoder 编码 LGO,然后拼接得到 Demand-object Features。注意到在一开始介绍物品的属性时,有一个 “相似性”,作者们就利用这种相似性,定义了 “正负样本”,然后采用对比学习的方式训练 “物品属性”。具体来说,对于两个拼接之后的 Demand-object Features,如果这两个特征对应的物品能满足同一个需求,那么这两个特征就互为正样本(比如图中的物品 a 和物品 b 都能满足需求 D1,那么 DO1-a 和 DO1-b 就互为正样本);其他任何拼接均互为负样本。作者们将 Demand-object Features 输入到一个 TransformerEncoder 架构的 Attribute Module 之后,就采用 InfoNCE Loss 训练了。
导航策略学习阶段
通过对比学习,Attribute Module 中已经学到了 LLM 提供的常识,在导航策略学习阶段,Attribute Module 的参数被直接导入,然后采用模仿学习的方式学习由 A* 算法收集的轨迹。在某一个时间步,作者采用 DETR 模型,将当前视野中的物品分割出来,得到 World-grounding Object,然后由 CLIP-Visual-Endocer 编码。其他的流程与属性学习阶段类似。最后将对需求指令的 BERT 特征、全局图片特征、属性特征拼接,送入一个 Transformer 模型,最终输出一个动作。
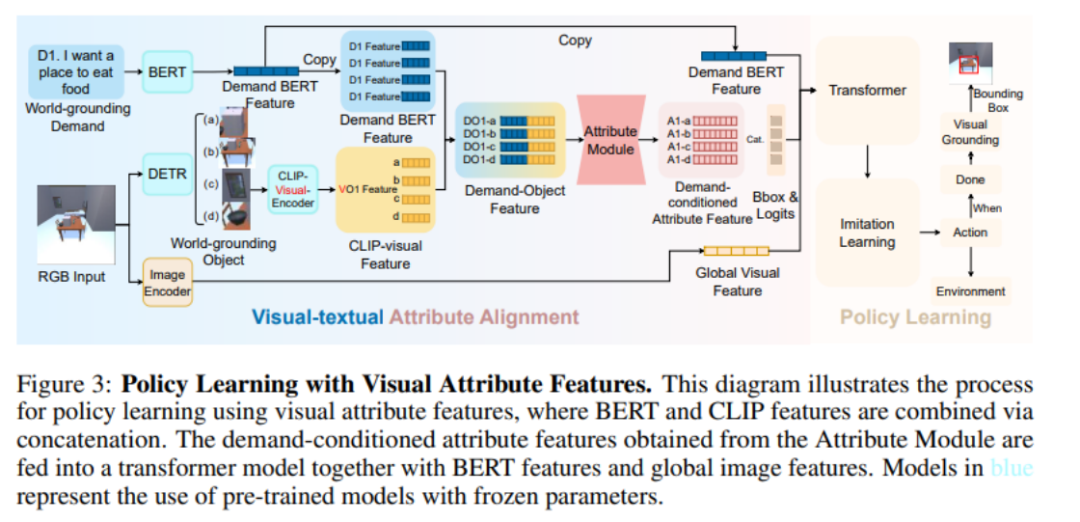
值得注意的是,作者们在属性学习阶段使用了 CLIP-Text-Encoder,而在导航策略学习阶段,作者们使用了 CLIP-Visual-Encoder。这里巧妙地借助于 CLIP 模型在视觉和文本上强大的对齐能力,将从 LLM 中学习到的文本常识转移到了每一个时间步的视觉上。
实验结果
实验是在 AI2Thor simulator 和 ProcThor 数据集上进行,实验结果表明,该方法显著高于之前各种视觉物品导航算法的变种、大语言模型加持下的算法。

VTN 是一种闭词汇集的物品导航算法(closed-vocabulary navigation),只能在预先设定的物品上进行导航任务。作者们对它的算法做了一些变种,然而不管是将需求指令的 BERT 特征作为输入、还是将 GPT 对指令的解析结果作为输入,算法的结果都不是很理想。当换成 ZSON 这种开词汇集的导航算法(open-vocabulary navigation),由于 CLIP 在需求指令和图片之间的对齐效果并不好,导致了 ZSON 的几个变种也无法很好的完成需求驱动导航任务。而一些基于启发式搜索 + LLM 的算法由于 Procthor 数据集场景面积较大,探索效率较低,其成功率并没有很高。纯粹的 LLM 算法,例如 GPT-3-Prompt 和 MiniGPT-4 都表现出较差的对场景不可见位置的推理能力,导致无法高效地发现满足要求的物品。
消融实验表明了 Attribute Module 显著提高了导航成功率。作者们展示了 t-SNE 图很好地表现出 Attribute Module 通过 demand-conditioned contrastive learning 成功地学习到了物品的属性特征。而将 Attribute Module 架构换成 MLP 之后,性能出现了下降,说明 TransformerEncoder 架构更适合用于捕捉属性特征。BERT 很好提取了需求指令的特征,使得对 unseen instruction 泛化性得到了提升。


下面是一些可视化:




本次研究的通讯作者董豪博士现任北京大学前沿计算研究中心助理教授,博士生导师、博雅青年学者和智源学者,他于 2019 年创立并领导北大超平面实验室(Hyperplane Lab),目前已在 NeurIPS、ICLR、CVPR、ICCV、ECCV 等国际顶尖会议 / 期刊上发表论文 40 余篇,Google Scholar 引用 4700 余次,曾获得 ACM MM 最佳开源软件奖和 OpenI 杰出项目奖。他还曾多次担任国际顶尖会议如 NeurIPS、 CVPR、AAAI、ICRA 的领域主席和副编委,承担多项国家级和省级项目,主持科技部新一代人工智能 2030 重大项目。

论文第一作王鸿铖,现为北京大学计算机学院二年级博士生。他的研究兴趣聚焦在机器人、计算机视觉以及心理学,希望能从人类的行为、认知、动机方面入手,对齐人与机器人之间的联系。


























