













本文经自动驾驶之心公众号授权转载,转载请联系出处。
什么是world models?
什么是world models, 可以参考Yann LeCun的PPT解释。
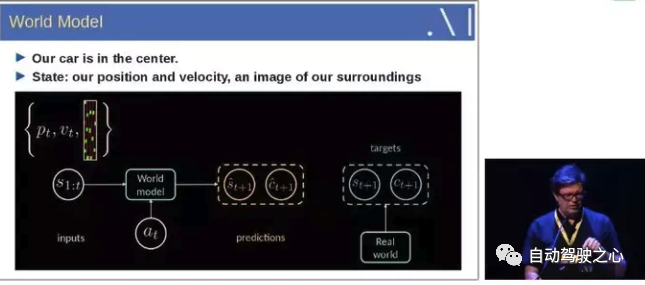
即输入历史1到t时刻的状态信息, 结合当前的动作, 能够预测接下来的状态。
通俗地理解, 笔者认为可以把world model理解为世界动态的演化。
world models的研究工作介绍
World models
论文链接: https://arxiv.org/abs/1803.10122
这个paper 和 Recurrent World Models Facilitate Policy Evolution 是同一个工作。
这个工作非常重要, 是后面很多工作的思想源泉。
工作导读
本文构建了一个生成式的world model,它可以用无监督的方式学习周围时空的表示, 并可以基于这个时空表示, 用一个简单的Policy模块来解决具体的任务。
启发
人类是根据有限的感官来感受并理解这个世界, 我们所做的决策和行为其实都是基于我们自已内部的模型。
为了处理日常生活中大量的信息,我们的大脑会学习这些时空信息。我们能够观察一个场景并且记住其中的一些抽象信息。也有证据表明, 我们在任何特定时刻的感知都受到我们的大脑基于内部模型对未来的预测的控制。
比如下面这个图,看的时候会发现它们好像在动. 但是其实都是静止的。

方法
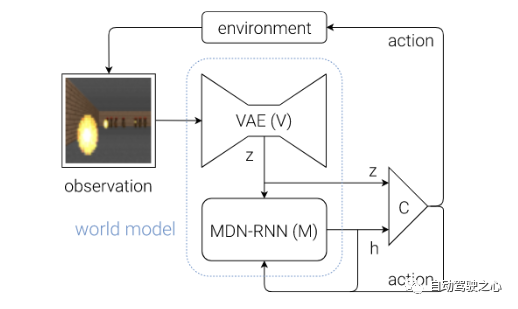
通过上面简单的例子会发现大脑其实预测了未来的感官数据, 即想象了未来可能发生的场景. 基于这个启示, 作者设计了一套框架, 框架图如下:

该框架图有三个主要的模块组成, 即 Vision Model(V), Memory RNN(M)和 Controller(C)。
首先是Vision Model(V), 这个模块的主要作用是学习观测的表示,这里用的方法是VAE, 即变分自编码器.它的主要作用是将输入的观测, 比如图片,转成feature。
VAE的网络结构图如下:

简单的解释就是, 输入观测图片, 先经过encoder提特征, 然后再经过decoder恢复图像, 整个过程不需要标注, 是自监督的。用VAE的原因个人理解是因为整个设计是生成式的。
其次是Memory RNN(M) ,它的网络结构如下:

这个模块的主要作用是学习状态的演化,可以认为这部分就是world models。
最后是 Controller (C) , 很显然,这部分的作用就是预测接下来的action,这里设计的非常简单, 目的就是为了把重心移到前面的模块中, 前面的模块可以基于数据来学习.公式如下:
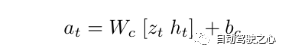
即用历史的状态积累 和 当前的 观测 , 预测接下来的动作。
整个推理流程如下:
即首先是观测经过V提feature, 然后经过M得到, 最后观测和历史信息一块儿送给C得到动作, 基于动作会和环境交互产生新的观测...., 这样可以不断地进行下去。
PlaNet: Learning Latent Dynamics for Planning from Pixels
论文连接: https://arxiv.org/abs/1811.04551
Blog: https://planetrl.github.io/
工作导读
本文提出了深度规划网络(PlaNet),这是一个基于模型的agent,它从图像pixels中学习环境的动态变化,之后在紧凑的潜在空间中做规划并预测动作。为了学习环境的动态变化,提出了一个具有随机和确定性组件的转换模型。此外,能做到多步预测。
笔者认为这个工作的最大贡献是提出了RSSM(Recurrent state space model), 所以接下来主要介绍RSSM。
RSSM
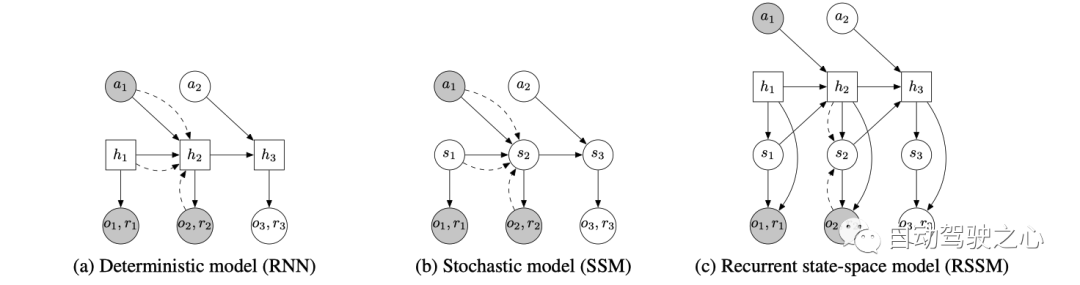
这个图是本文提出的RSSM与另外两种方法的比较,如图所示, 方框代表的是确定式变量, 圆代表的是随机式变量. 图a就是一个确定式的模型, 即通过RNN中的 隐式状态 不断地传递信息, 通过 可以预测action 和reward, 即只要 给定, 预测的 action和reward一定是确定的; 而图b是随机式的, 可以看到状态 是随机式的, 比如服从某个分布, 那这样采样得到的不同, 生成的 action和reward也会随之而变化, 所以是随机式的; 图c可以看到, 预测action和reward的输入有两部分组成, 一部分是确定式的, 另一部分是随机式的。
三种方式的优缺点对比如下:
a. 确定式能够防止模型随便预测多种未来, 可以想象, 如果模型不够准确, 预测的未来就不准, 这对于后面的规划来说容易出现错误的结果。
b. 随机式的问题是, 随机的累积多步之后,可能和最初的输入没有关系了, 即很难记住信息。
c. 确定式和随机式相结合, 既有确定部分防止模型随意发挥, 又有随机部分提升容错性。
Dreamer-V1: Dream to Control : Learning behaviors by latent imagination
论文连接: https://arxiv.org/abs/1912.01603
导读
从题目中可以看出来, Dreamer-V1是基于latent imagination 来学习behaviors, 即dream to control. 有点像周星弛的电影武状元苏乞儿里的睡梦罗汉拳. 方法上是基于想象的图片进行学习.
方法
下图为DreamerV1的三个组成部分:
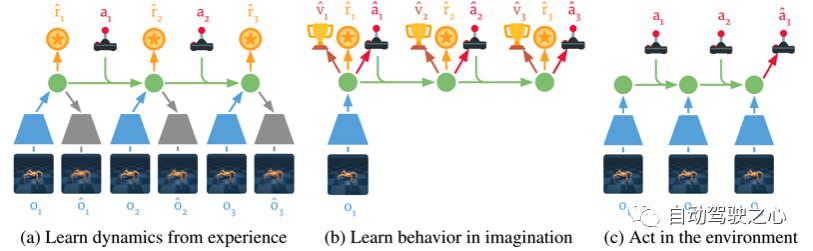
a. 根据历史的观测和动作学习环境的dynamics, 主要是学习将观测和动作提取到compact latent states space中。
b. 通过反向传播, DreamerV1可以在想象中进行训练。
c. 基于历史的状态和当前的观测来预测接下来的状态及动作。
接下来主要介绍如何通过latent 想象学习behaviors。
Learning behaviors by latent imagination
算法流程如下:

注意看, 从开始, 首先对于每个 , 根据如下公式得到接下来的 :
因此就有了 , 之后再预测对应的rewards, 在按照下面的方程:

得到 value function的估计。
DreamerV2: Mastering Atari with Discrete World Models
论文链接: https://arxiv.org/abs/2010.02193
导读
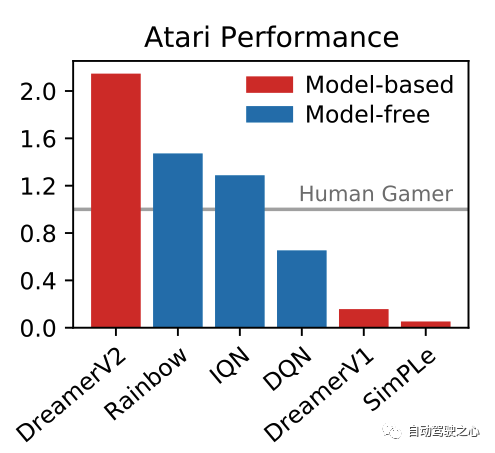
DreamerV1强调的是在latent imagination中学习, DreamerV2强调的是在预测中进行学习;笔者认为二者在学习方式上并无区别. 区别的是 DreamerV2相比DreamerV1用了前面提到的RSSM. 论文题目中提到的 Atari是一个游戏的名字, 而解决这个游戏的方法是离散的世界模型. 这里的离散是因为观测的输入刚好可以以离散的形式来表达. DreamerV2是第一个基于模型的方法在Atari这个游戏上超过非模型的方法。
方法
网络结构如下:
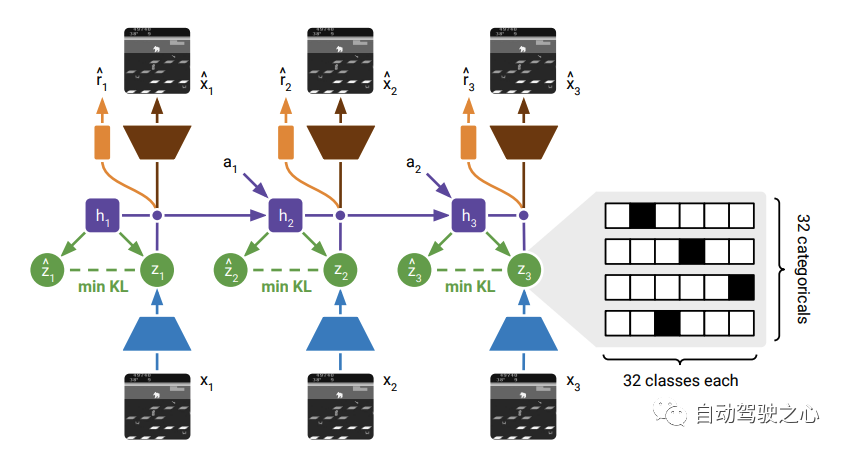
整体结构上和DreamerV1区别不太大, 都有重建图像的任务. 只不过这里有一项关于先验与后验的KL-loss, 即这两个分布的KL-loss。
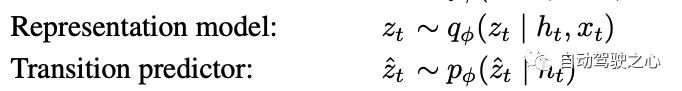
在 Transition 模型这里与DreamerV1也不同, 在V1里面是这样。
, 即基于历史的状态和动作来预测接下来的状态, 而在V2里面变成了 , 即基于RNN的确定式的隐式状态来预测接下来的观测分布. 这里的不同还是主要源于引入了RSSM。
在Actor Critic learning阶段的结构如下:
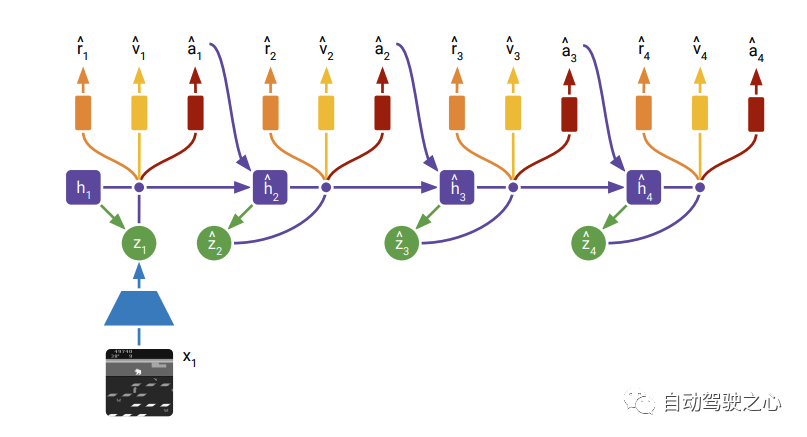
这个过程非常清晰, 即在没有后续观测的时候, 直接从先验的里面进行采样, 所以在训练的时候,先验要逼近后验。
SEM2:Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
paper链接: https://arxiv.org/abs/2210.04017
导读
从题目中可以看出来, 主要是通过 Semantic Masked World model来提升端自端自动驾驶的采样效率和鲁棒性. 这里Semantic mask指的是接了一个语义分割的head输出semantic mask, 另外在输入端也多了lidar。
出发点
作者认为之前的工作中提出的世界模型嵌入的潜在状态包含大量与任务无关的信息, 导致采样效率低并且鲁棒性差. 并且之前的方法中,训练数据这块儿分布是不均衡的, 因此之前的方法学习到的驾驶policy很难应对corner case。
方法概述
针对上面提出的信息冗余, 这里提出了Semantic masked世界模型, 即SEM2. 也就是在decoder部分加入了语义mask 的预测, 让模型学习到更加紧凑,与驾驶任务更相关的feature; 网络结构如下:

各部分参数如下:

结构上大体与DreamerV2很相似, 输入端多了lidar, decoder部分多了一支 Filter用来预测bev的Semantic Mask. 右下角是Semantic Mask的内容信息, 主要包括, 地图map信息, Routing信息, 障碍物信息和自车的信息。
Multi-Source Sampler
上面作者有提到之前训练集里面数据不均衡, 比如大直路太多. 这里就用了一种sample的方式, 简单地说就是在训练的每个batch中, 均衡的加入各种场景的样本, 这样就可以达到训练样本平均衡分布的效果。
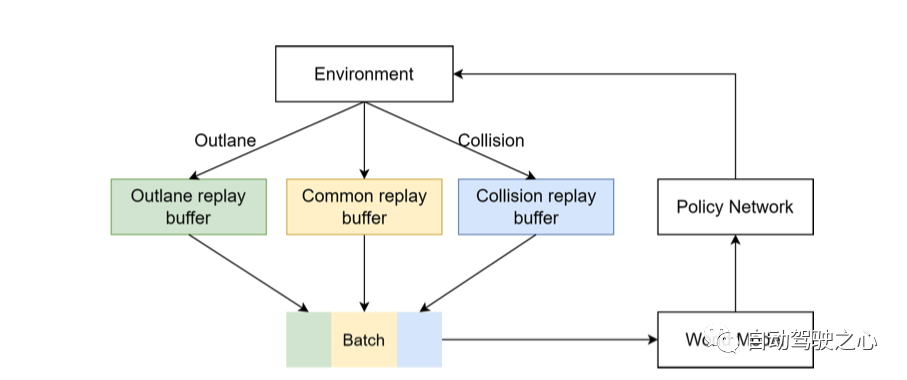
如上图所示, 正常的数据, 冲出道路的数据,及碰撞的数据在每个batch中混在一起训练. 这样模型就能见到各种case的数据, 这有利于泛化解决corner case。
Wayve-MILE: Model-Based Imitation Learning for Urban Driving
代码: https://github.com/wayveai/mile.
论文: https://arxiv.org/abs/2210.07729
博客: https://wayve.ai/thinking/learning-a-world-model-and-a-driving-policy/
导读
MILE是Wayve这家公司的研究工作, 有代码,有详细的blog解释, 可谓是好的研究工作。
SEM2的网络结构中还需要预测reward, 在MILE中就没有预测reward了, 题目中说是模仿学习, 是因为这里在相同的环境下, 有教练的action作为target, 模型直接学习教练的action,所以叫模仿学习. MILE这个工作很有启发性, 其中先验分布, 后验分布以及采样的思想, 虽然在前面的几个工作中也有用到, 但是感觉这些概念在MILE框架下,得到了更好的解释。
网络结构
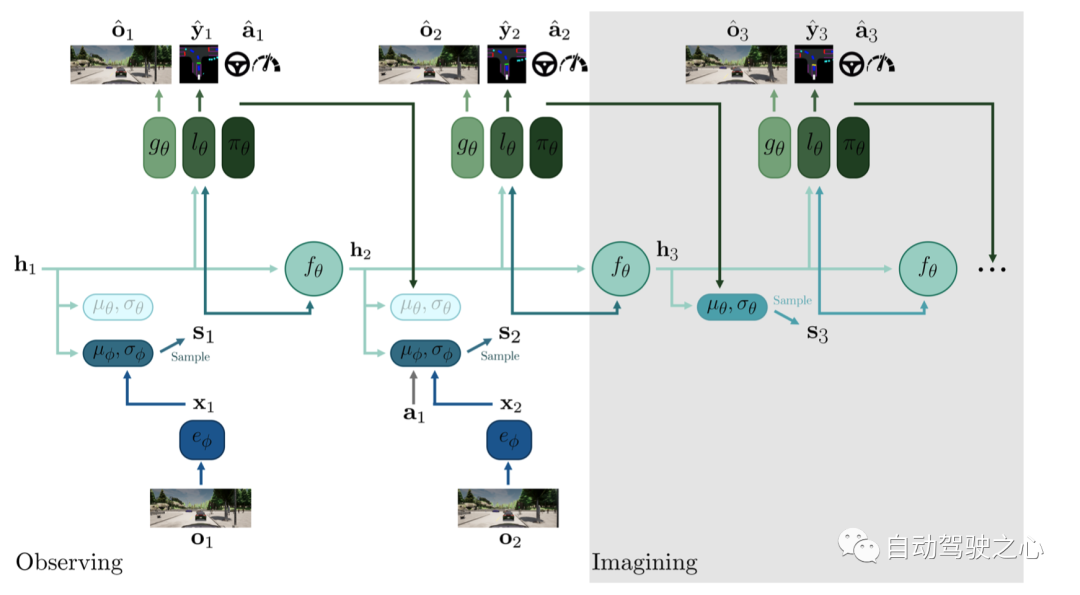
相关参数如下:

- 只看最左侧部分,可以认为是VAE的结果, 下半部分是encoder, 上面部分重建图像是decoder.
- 中间RNN部分, 用的也是RSSM, 这部分可以认为是world model部分,能够做到生成未来.
- 生成未来的关键是要学习到未来的世界的分布, 图上 就是这个作用, 训练的时候让先验逼近后验, 推理想象模式下没有观测,就从先验分布中采样.
- 训练的时候, 针对先验后验那里,采用了dropout机制, 即训练的时候会以一定的概率从先验分布中采样.
- 网络结构上虽然画了重建图像部分, 但是实验的时候并没有用到重建图像的loss.
下面是一个长时间预测的效果图:

world models的将来发展
笔者认为上面介绍的一些world model的相关工作, 和强化学习、模仿学习等有很大关系, 可以看到世界模型是预测未来的基础, 笔者认为关于世界模型有几大思考的方向:
- world model的架构设计, 上面的方法基本上基于RNN, RSSM的框架, 但这种设计是不是最好, 是否有利于训练,推理,都有待进一步的探索
- world model到底该学习什么, 或者对于具体的任务, 比如自动驾驶中world model应该学习到什么? 2d信息, 3d信息, 轨迹信息,地图信息,占据信息 。。。。。。, 针对这些信息如何设计方案?
- world model如何与LLM结合, 或者如何利用现有LLM的一些方法、结构和能力。
- 如何做到自监督, 上面的方法中, 比如MILE和SEM2需要semantic mask的标注信息. 但标注但标注数据总是有限且昂贵。

原文链接:https://mp.weixin.qq.com/s/VYdMVBpxRd1ETfGf6djK8w
























