













Redis为什么快呢?
Redis的速度⾮常的快,单机的Redis就可以⽀撑每秒十几万的并发,相对于MySQL来说,性能是MySQL的⼏⼗倍。速度快的原因主要有⼏点:
- 完全基于内存操作
- 使⽤单线程,避免了线程切换和竞态产生的消耗
- 基于⾮阻塞的IO多路复⽤机制
- C语⾔实现,优化过的数据结构,基于⼏种基础的数据结构,redis做了⼤量的优化,性能极⾼

能说一下I/O多路复用吗?
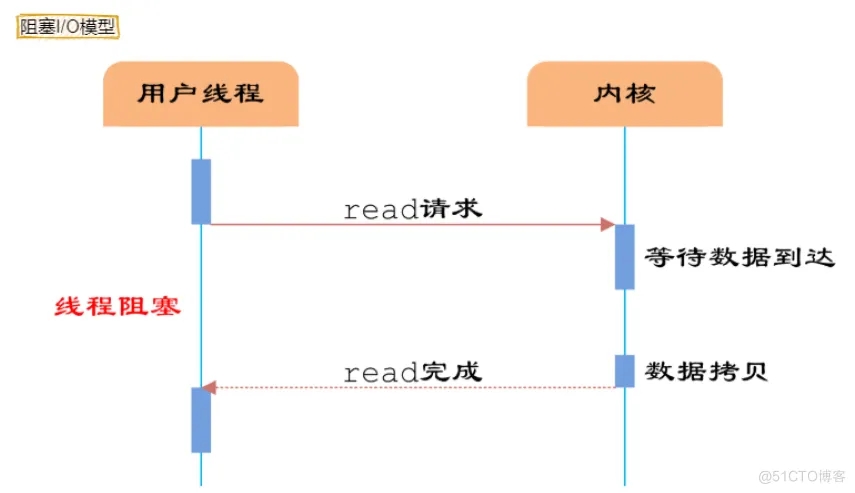
第一种选择:按顺序逐个检查,先检查A,然后是B,之后是C、D。。。这中间如果有一个学生卡住,全班都会被耽误。这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者- 线程处理连接。
第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。
第一种就是阻塞IO模型,第三种就是I/O复用模型。
Linux系统有三种方式实现IO多路复用:select、poll和epoll。
例如epoll方式是将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。
这样,整个过程只在进行select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。




















