













Transformer模型是否能够超越预训练数据范围,泛化出新的认知和能力,一直是学界争议已久的问题。
最近谷歌DeepMind的3位研究研究人员认为,要求模型在超出预训练数据范围之外泛化出解决新问题的能力,几乎是不可能的。
LLM的终局就是人类智慧总和?

论文地址:https://arxiv.org/abs/2311.00871
Jim Fan转发论文后评论说,这明确说明了训练数据对于模型性能的重要性,所以数据质量对于LLM来说实在是太重要了。

研究人员在论文中专注于研究预训练过程的一个特定方面——预训练中使用的数据——并研究它如何影响最终Transformer模型的少样本学习能力。
研究人员使用一组 来作为输入和标签, 来对新输入的
来作为输入和标签, 来对新输入的 的标签
的标签 进行预测。要训练模型做出这样的预测,需要在
进行预测。要训练模型做出这样的预测,需要在 形式的许多序列上拟合模型。
形式的许多序列上拟合模型。
研究人员使用包含多种不同函数类别的混合对Transformer模型进行预训练,以便在上下文中学习,并展示了所表现出的模型选择行为(Model Selection Phenomena)。
他们还研究了预训练Transformer模型在与预训练数据中的函数类别 「不一致 (out-of-distribution)」的函数上的情境学习行为。
通过这种方式,研究人员研究了预训练数据组成与Transformer模型对相关任务进行少量学习的能力之间的相互作用和影响后发现:
1. 在所研究的机制中,有明确的证据表明,模型在上下文学习过程中可以在预训练的函数类别中进行模型选择,而且几乎不需要额外的统计成本。
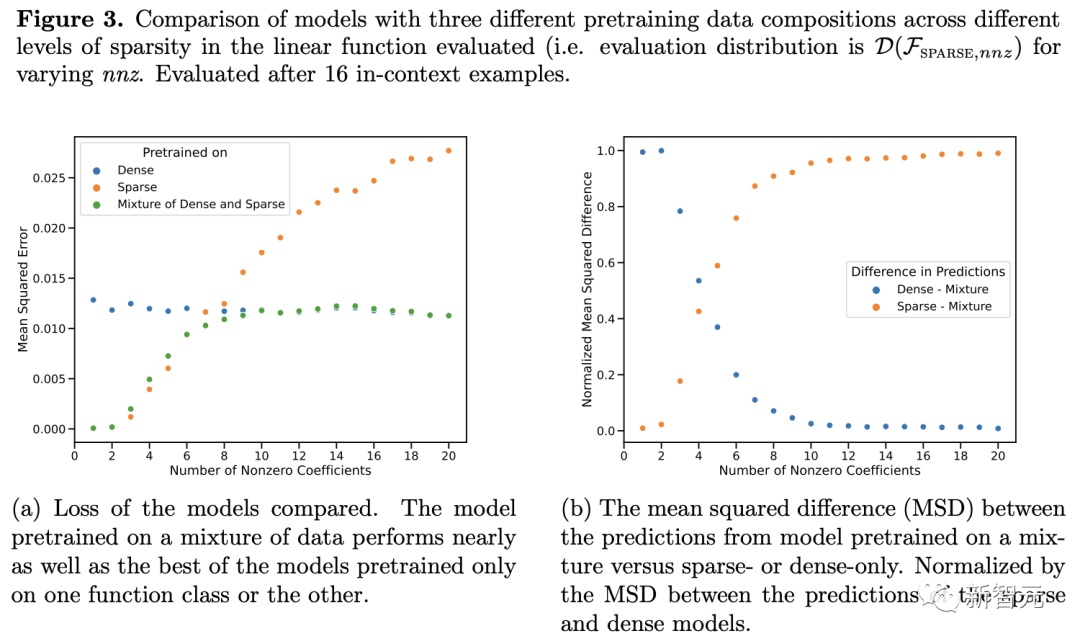
预训练数据中各个稀疏程度的线性函数都被很好地覆盖的情况下,Transformer可以进行近似最优的预测。
2. 但几乎没有证据表明,模型的上下文学习行为能够超出其预训练数据的范围。
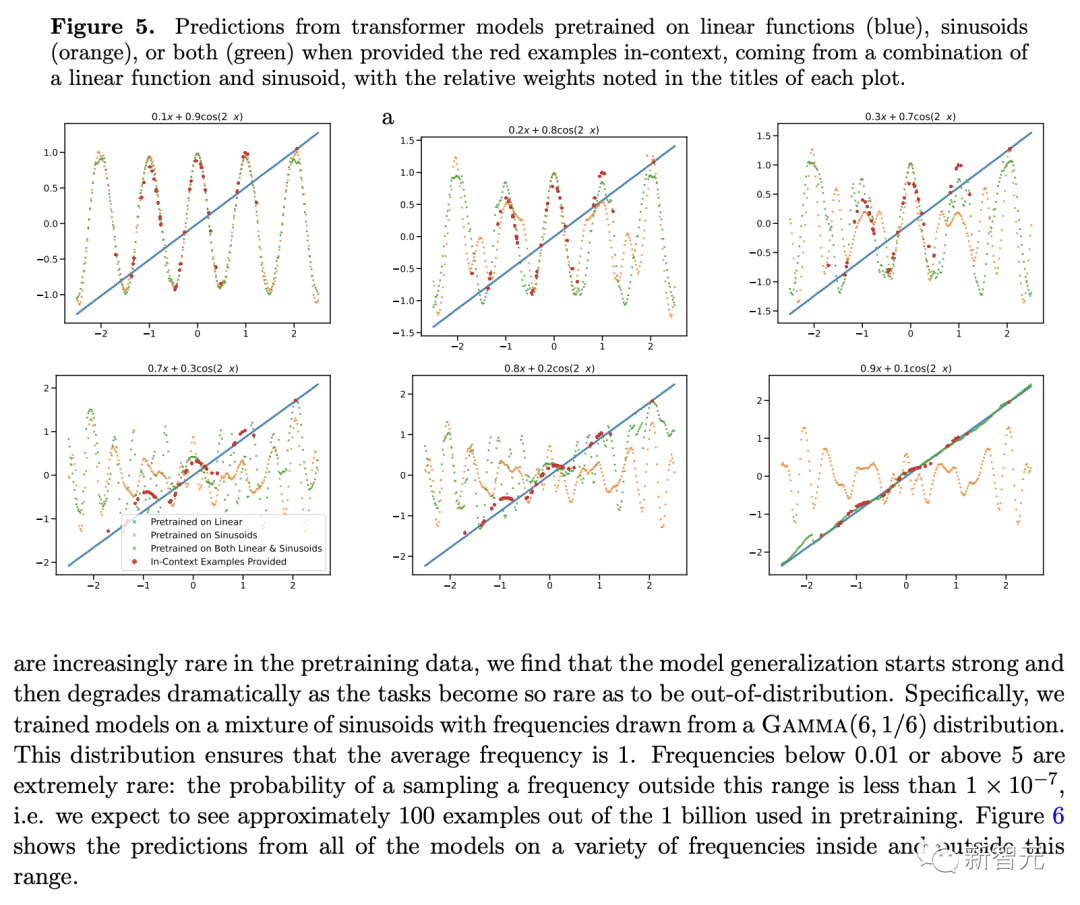
当组合函数主要来自一个函数类时,预测合理。当两个类同时显著贡献时,预测失效。
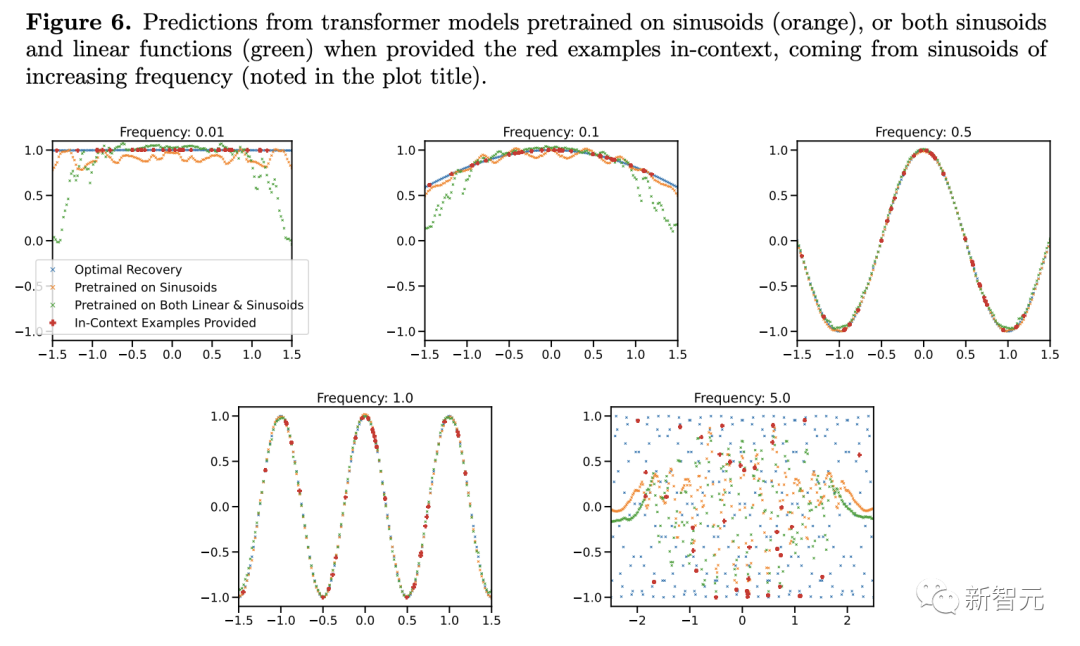
对于预训练数据中极为罕见的高低频正弦函数,模型的泛化会失败。
研究过程细节
首先,为了避免产生误解,这里先声明本实验所采用的模型:类似于GPT-2,包含12层,256维嵌入空间。
之前提到了文章使用不同函数混合的方法进行研究,
那么我们不禁要问:「当提供支持预训练混合的上下文示例时,模型如何在不同的函数类之间进行选择?」
之前的研究表明,在线性函数上预训练的Transformer在对新的线性函数进行上下文学习时表现几乎最优。
于是研究人员采用两个线性模型来进行研究:一个在密集线性函数上训练(其中线性模型的所有系数都是非零的),另一个在稀疏线性函数上训练(假设20个系数中只有2个是非零的)。
每个模型分别对新的密集线性函数和稀疏线性函数执行相应的线性回归和套索回归(Lasso)。此外,还将这两个模型与在稀疏线性函数和密集线性函数的混合上预训练的模型进行了比较。
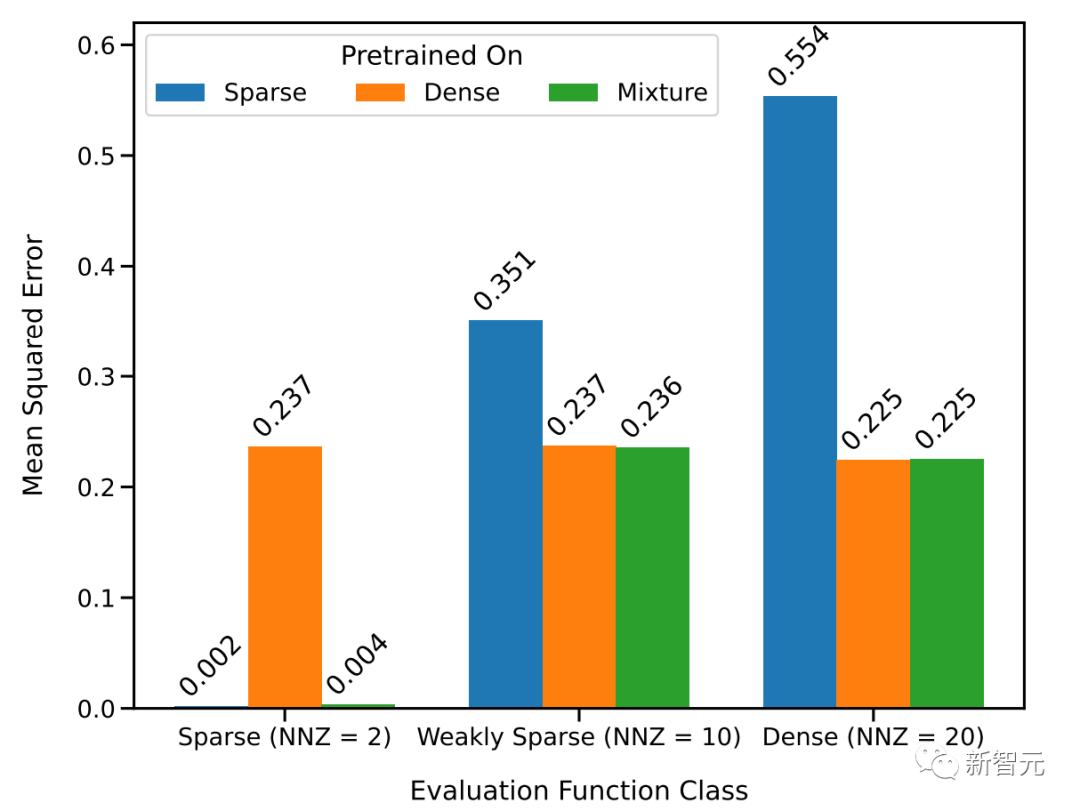
上图显示,在以D(F) = 0.5*D(F1)+0.5*D(F2)的比例混合两个函数的情况下,新的函数在上下文学习中的表现与仅在一个函数类上预训练的模型相似。
而在新的混合函数上预训练的模型与前人研究中所展示的模型(理论上最优)相似,因此可以推断该模型也几乎是最优的。
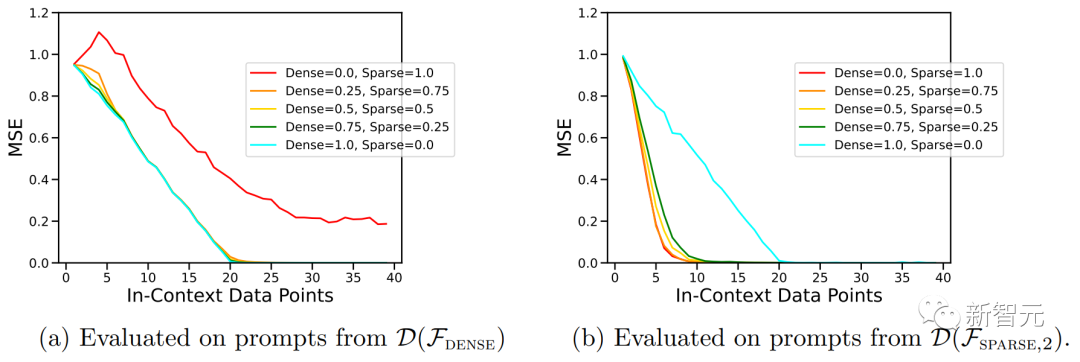
上图中的ICL学习曲线向我们表明,这种上下文模型选择能力相对于提供的上下文示例数量相对一致。
我们还可以看到,与纯粹基于该函数类预训练模型相比,对于给定函数类,这种使用权重来进行预训练数据混合的ICL学习曲线几乎与最佳基线样本复杂度相匹配。
上图还表明,Transformer模型ICL泛化存在分布不均。尽管密集线性类和稀疏线性类都是线性函数,但我们可以看到上图(a)中的红色曲线性能较差,而相应的,图(b)中的蓝色曲线性能较差。
这表明该模型能够执行模型选择,以选择是否仅使用预训练组合中一个基函数类或另一个基函数类的知识进行预测。
事实上,当上下文中提供的示例来自非常稀疏或非常密集的函数时,预测几乎与分别在仅稀疏或仅密集数据上预训练的模型所做的预测相同。
模型的局限性
之前的实验展示了混合预训练数据的情况,下面我们来探索一些明确脱离所有预训练数据的函数。
作者在这里研究了模型沿两个轴的ICL泛化能力:从未见过的函数,以及函数的极端版本(频率比预训练中通常看到的频率高得多或低得多的正弦曲线)上的性能。
在这两种情况下,研究人员几乎没有发现分布外泛化的证据。
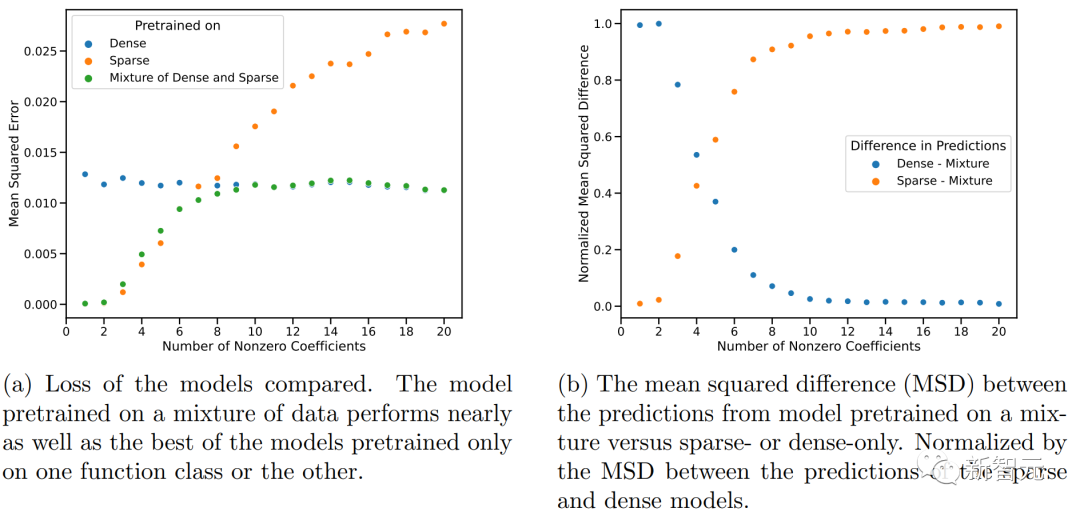
上图显示,Transformer在中等稀疏度水平(nnz=3到7)下的预测与预训练时提供的任何函数类的任何预测都不相似,而是介于两者之间。
因此,可以假设该模型具有一些归纳偏差,可以组合预训练的函数类。
但是,人们可能会怀疑该模型可以从预训练期间看到的函数组合中产生预测。
所以作者在具有明显不相交的函数类的背景下检验这一假设,研究了对线性函数、正弦函数和两者的凸组合执行 ICL 的能力。
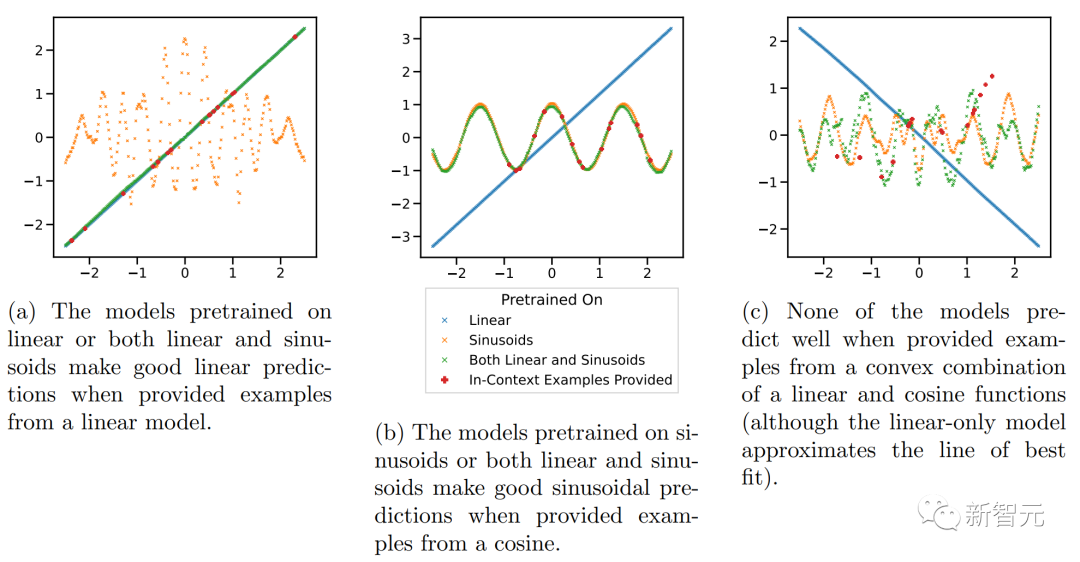
上图显示,虽然模型在线性函数和正弦曲线的混合上进行预训练(即D(F) = 0.5*D(F1)+0.5*D(F2))能够分别对这两个函数中的任何一个做出良好的预测,但它无法拟合两者的凸组合的函数。
然而,我们仍然可以假设:当上下文中的示例接近在预训练中学习的函数类时,模型能够选择用于预测的最佳函数类。
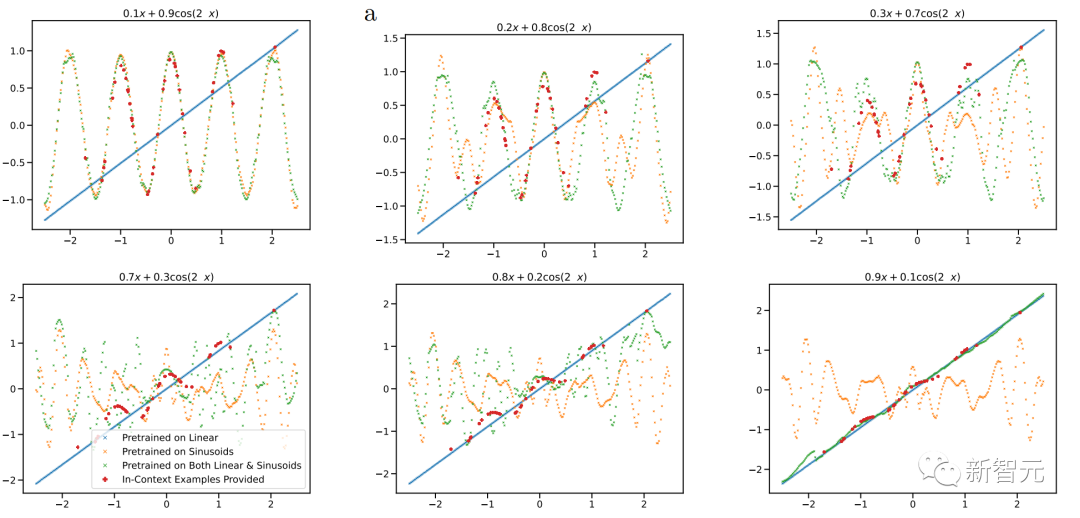
在图 5 中,研究人员扫描了凸组合中线性函数和正弦波的相对权重。在这里,研究人员观察到,当组合函数主要来自一个函数类或另一个函数类时——即通过预训练期间学习的函数类很好地近似——上下文预测是合理的。
但是,当这两个函数对凸组合有显著贡献时,模型会做出不稳定的预测,而上下文示例并不能很好地证明其合理性。这表明模型的模型选择能力受到与预训练数据的接近程度的限制,并表明功能空间的广泛覆盖对于广义的上下文学习能力至关重要。
前面的凸组合是专门构造的,因此模型在预训练中从未见过类似的函数。
网友热议
面对文章的结论,Jim Fan给出了略带嘲讽的评价:

「本文相当于:尝试只在狗和猫的数据集上训练ViT。使用100B狗/猫图像和1T 参数!现在看看它是否能识别飞机——令人惊讶的是,它不能!」
但是有好事的网友把这个事请拿去问了下ChatGPT,它自己却回答说,自己可以超越训练数据输出新的内容。
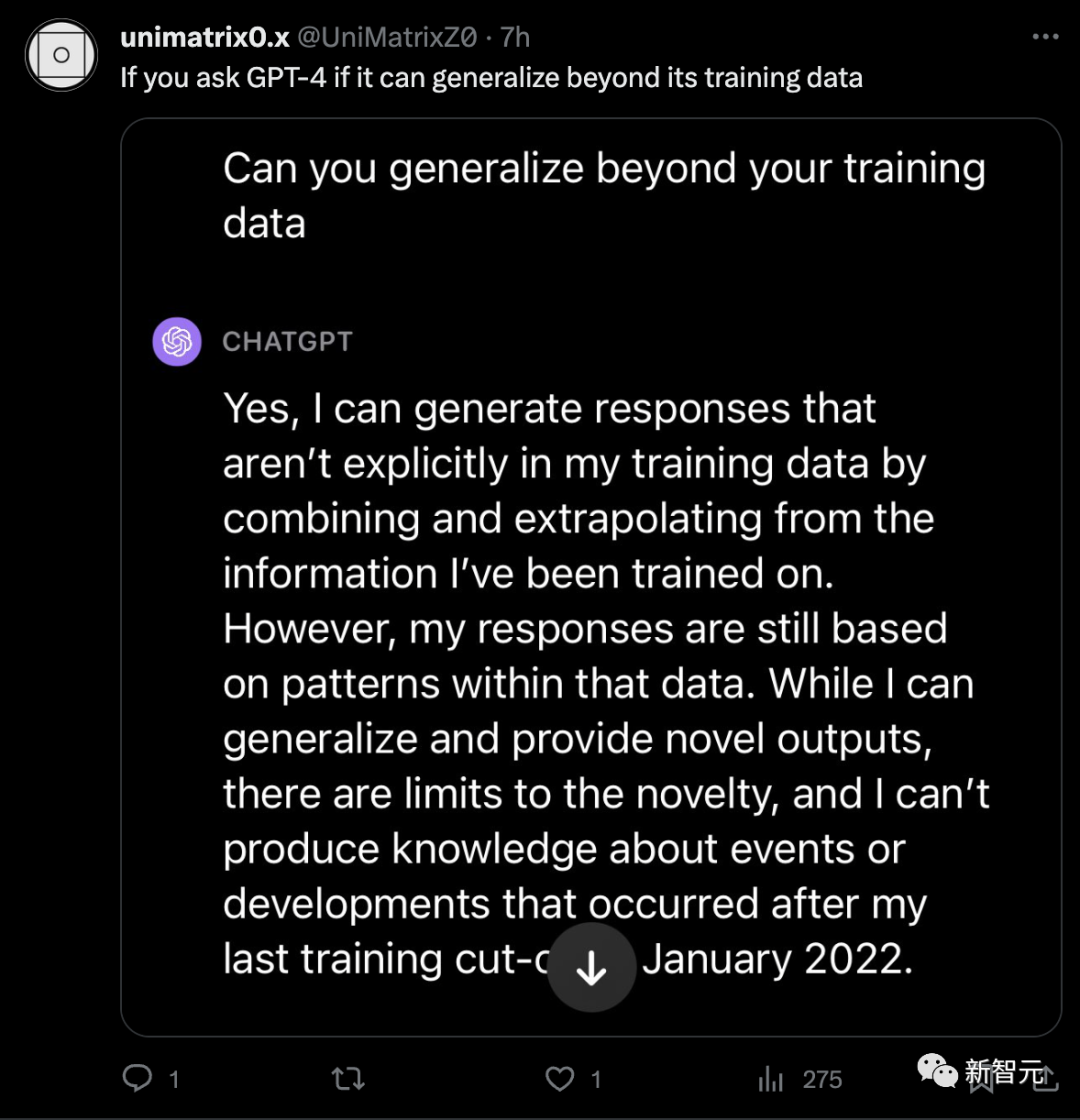
而网友对于Transformer的这个局限还是很宽容的,毕竟,人类也不行。

AIGC的火热引起人们对于模型能力的广泛研究,对于我们无法完全了解的、却广泛应用于社会和生活中的「 人工智能 」,知道它的边界在哪里也很重要。






























