机器学习模型变得越来越复杂和准确,但它们的不透明性仍然是一个重大挑战。理解为什么一个模型会做出特定的预测,对于建立信任和确保它按照预期行事至关重要。在本文中,我们将介绍LIME,并使用它来解释各种常见的模型。
LIME
LIME (Local Interpretable Model-agnostic Explanations)是一个强大的Python库,可以帮助解释机器学习分类器(或模型)正在做什么。LIME的主要目的是为复杂ML模型做出的单个预测提供可解释的、人类可读的解释。通过提供对这些模型如何运作的详细理解,LIME鼓励人们对机器学习系统的信任。
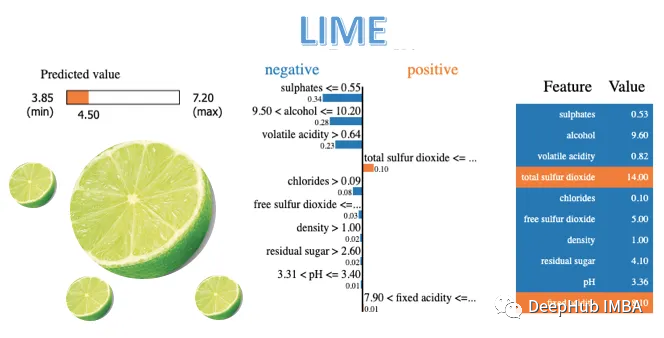
随着ML模型变得越来越复杂,理解它们的内部工作原理可能具有挑战性。LIME通过为特定实例创建本地解释来解决这个问题,使用户更容易理解和信任ML模型。
LIME的主要特点:
- 创建简单、可解释的解释来理解复杂ML模型的预测。
- 检查单个预测来识别模型中潜在的偏差和错误。
- 理解有助于准确预测的特征来提高模型性能。
- 提供透明度和可解释性来增强用户对机器学习系统的信任。
LIME通过使用一个更简单的、围绕特定实例的本地可解释模型来近似复杂的ML模型来运行。LIME工作流程的主要可以分为一下步骤:
- 选择要解释的实例。
- 通过生成一组相邻样本来干扰实例。
- 使用复杂ML模型获得扰动样本的预测。
- 拟合一个更简单的,可解释的模型(例如,线性回归或决策树)对受干扰的样本及其预测。
- 解释更简单的模型,为原始实例提供解释。
在不同模型中使用LIME
在开始使用LIME之前,需要安装它。可以使用pip安装LIME:
pip install lime1、分类模型
要将LIME与分类模型一起使用,需要创建一个解释器对象,然后为特定实例生成解释。下面是一个使用LIME库和分类模型的简单示例:
# Classification- Lime
import lime
import lime.lime_tabular
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
# Load the dataset and train a classifier
data = datasets.load_iris()
classifier = RandomForestClassifier()
classifier.fit(data.data, data.target)
# Create a LIME explainer object
explainer = lime.lime_tabular.LimeTabularExplainer(data.data, mode="classification", training_labels=data.target, feature_names=data.feature_names, class_names=data.target_names, discretize_cnotallow=True)
# Select an instance to be explained (you can choose any index)
instance = data.data[0]
# Generate an explanation for the instance
explanation = explainer.explain_instance(instance, classifier.predict_proba, num_features=5)
# Display the explanation
explanation.show_in_notebook()
2、回归模型
在回归模型中使用LIME类似于在分类模型中使用LIME。需要创建一个解释器对象,然后为特定实例生成解释。下面是一个使用LIME库和回归模型的例子:
#Regression - Lime
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from lime.lime_tabular import LimeTabularExplainer
# Generate a custom regression dataset
np.random.seed(42)
X = np.random.rand(100, 5) # 100 samples, 5 features
y = 2 * X[:, 0] + 3 * X[:, 1] + 1 * X[:, 2] + np.random.randn(100) # Linear regression with noise
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a simple linear regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Initialize a LimeTabularExplainer
explainer = LimeTabularExplainer(training_data=X_train, mode="regression")
# Select a sample instance for explanation
sample_instance = X_test[0]
# Explain the prediction for the sample instance
explanation = explainer.explain_instance(sample_instance, model.predict)
# Print the explanation
explanation.show_in_notebook()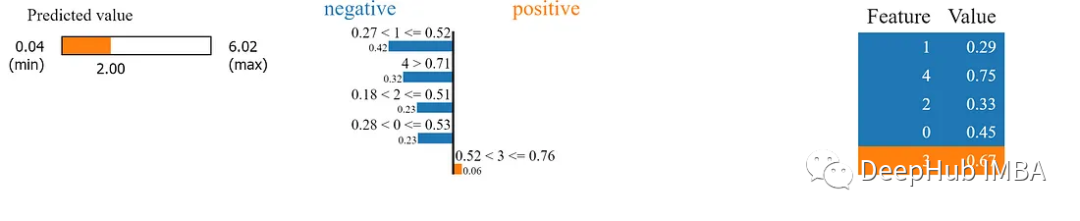
3、解释文本
LIME也可以用来解释由文本模型做出的预测。要将LIME与文本模型一起使用,需要创建一个LIME文本解释器对象,然后为特定实例生成解释。下面是一个使用LIME库和文本模型的例子:
# Text Model - Lime
import lime
import lime.lime_text
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import fetch_20newsgroups
# Load a sample dataset (20 Newsgroups) for text classification
categories = ['alt.atheism', 'soc.religion.christian']
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
# Create a simple text classification model (Multinomial Naive Bayes)
tfidf_vectorizer = TfidfVectorizer()
X_train = tfidf_vectorizer.fit_transform(newsgroups_train.data)
y_train = newsgroups_train.target
classifier = MultinomialNB()
classifier.fit(X_train, y_train)
# Define a custom Lime explainer for text data
explainer = lime.lime_text.LimeTextExplainer(class_names=newsgroups_train.target_names)
# Choose a text instance to explain
text_instance = newsgroups_train.data[0]
# Create a predict function for the classifier
predict_fn = lambda x: classifier.predict_proba(tfidf_vectorizer.transform(x))
# Explain the model's prediction for the chosen text instance
explanation = explainer.explain_instance(text_instance, predict_fn)
# Print the explanation
explanation.show_in_notebook()
4、图像模型
LIME也可以解释图像模型做出的预测。需要创建一个LIME图像解释器对象,然后为特定实例生成解释。
import lime
import lime.lime_image
import sklearn
# Load the dataset and train an image classifier
data = sklearn.datasets.load_digits()
classifier = sklearn.ensemble.RandomForestClassifier()
classifier.fit(data.images.reshape((len(data.images), -1)), data.target)
# Create a LIME image explainer object
explainer = lime.lime_image.LimeImageExplainer()
# Select an instance to be explained
instance = data.images[0]
# Generate an explanation for the instance
explanation = explainer.explain_instance(instance, classifier.predict_proba, top_labels=5)LIME的输出解读
在使用LIME生成解释之后,可以可视化解释,了解每个特征对预测的贡献。对于表格数据,可以使用show_in_notebook或as_pyplot_figure方法来显示解释。对于文本和图像数据,可以使用show_in_notebook方法来显示说明。
通过理解单个特征的贡献,可以深入了解模型的决策过程,并识别潜在的偏差或问题。
LIME提供了一些先进的技术来提高解释的质量,这些技术包括:
调整扰动样本的数量:增加扰动样本的数量可以提高解释的稳定性和准确性。
选择可解释的模型:选择合适的可解释模型(例如,线性回归、决策树)会影响解释的质量。
特征选择:自定义解释中使用的特征数量可以帮助关注对预测最重要的贡献。
LIME的限制和替代方案
虽然LIME是解释机器学习模型的强大工具,但它也有一些局限性:
局部解释:LIME关注局部解释,这可能无法捕捉模型的整体行为。
计算成本高:使用LIME生成解释可能很耗时,特别是对于大型数据集和复杂模型。
如果LIME不能满足您的需求,还有其他方法来解释机器学习模型,如SHAP (SHapley Additive exPlanations)和anchor。
总结
LIME是解释机器学习分类器(或模型)正在做什么的宝贵工具。通过提供一种实用的方法来理解复杂的ML模型,LIME使用户能够信任并改进他们的系统。
通过为单个预测提供可解释的解释,LIME可以帮助建立对机器学习模型的信任。这种信任在许多行业中都是至关重要的,尤其是在使用ML模型做出重要决策时。通过更好地了解他们的模型是如何工作的,用户可以自信地依赖机器学习系统并做出数据驱动的决策。