本文经自动驾驶之心公众号授权转载,转载请联系出处。
0 写在前面
最近很多小伙伴来向我们咨询轨迹预测相关的入门学习基础,今天我们也为大家分享下轨迹预测的定义、输出格式、常用的相关术语,常用的轨迹预测方法论,以及评测方式。所有的内容都为日常笔记输出,建议收藏,有时间随时可以学习!所有参考文献,底部备有出处~
以上内容均出自《轨迹预测理论实战&论文带读课程》,双十一八折优惠进行中!

1 问题描述
1.1 轨迹预测的输入
1.1.1 道路场景(地图)信息
道路位置、人行横道位置、车道方向
1.1.2 周围车辆信息
当前状态、历史轨迹
1.1.3 目标车辆信息
当前状态、历史轨迹:
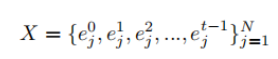
1.2 轨迹预测的输出
1.2.1 目标车辆未来轨迹及分布
目标车辆(1~N)的未来f个时刻的轨迹及轨迹分布:
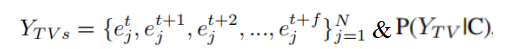
1.2.2 输出类型
单模态轨迹、多模态轨迹
1.3 相关术语
轨迹(trajectory):一个物体或实体随时间变化的运动。它表示对象经过的一系列位置或状态。
机动(manoeuvre):车辆或物体所执行的特定动作或运动,如变道、转弯、合并、加速、减速和停止。
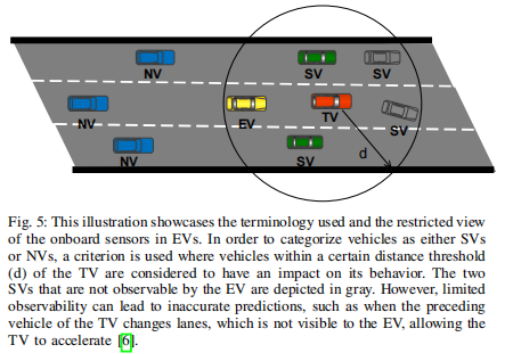
自身车辆(Ego Vehicle,EV):自动驾驶汽车本身。
目标车辆(Target Vehicle,TV):期望得到预测轨迹的车辆。
周围车辆(Surrounding Vehicle,SV):TV周围对其运动产生影响的车辆。
无关车辆(Non-Effective Vehicle,NV):不会对TV运动产生影响的车辆。
2 传统轨迹预测方法
2.1 基于物理的方法
2.1.1 物理模型
1)通常采用动力学(形式复杂)或运动学(形式简单,更常用)模型来描述物理行为。
2)也可采用体现微观交互的模型:跟车模型(例,智能驾驶员模型(IDM))、换道模型-微观交通建模常用
3)可为使用单一模型,也可使用交互多模型(IMM,用IMM-KF实现结合)-参考文献16
2.1.2 干扰/不确定性处理
方式一:卡尔曼滤波器(KF),得到滤波处理后的一条轨迹-参考文献39。
方式二:粒子滤波
方式三:蒙特卡洛(MC)模拟:得到未来轨迹分布-参考文献40、41。
2.1.3 优缺点分析
优点:可解释性强,性能稳定;运动学计算简单;
缺点:复杂的动力学模型计算量大;仅适合短时预测(<1 s);不适合复杂场景,无法处理多个体间的交互。
2.2 基于采样的方法:
生成可能的车辆状态分布,两种类型:生成多个轨迹段或粒子状态
优点:可抵御系统噪声和不确定性
缺点:场景有限
2.3 概率模型
使用概率论来建模和估计未来轨迹的可能性,为预测的轨迹提供概率分布或置信度度量。
2.3.1 高斯混合模型(Gaussian Mixture Model,GMM)
将轨迹的分布表示为多个高斯分布的组合,参考文献46~49、18、62(GMM-HMM)。
优点:可处理多模态分布。
缺点:要大量的计算。
2.3.2 高斯过程(Gaussian Process,GP)
轨迹被认为是沿时间轴从GP中获取的样本,参考文献50~54、63。
优点:评估自身的不确定性,广泛应用于与其他方法的结合。
缺点:基于假设,对新场景的适用性有限。
2.3.3 隐马尔可夫模型(Hidden Markov Model,HMM)
观测序列由交通参与者的前一状态组成,基于这些过去的观测值来估计最可能的未来观测序列,参考文献55、56、17、64、65。
优点:能够捕获时间依赖性,处理缺失或噪声数据,并考虑预测未来轨迹所涉及的不确定性。
缺点:过渡到未来状态的概率仅取决于当前状态。
2.3.4 动态贝叶斯网络(Dynamic Bayesian Network,DBN)
通过结合时间序列并利用贝叶斯网络框架,为轨迹预测提供了一种基于机动的方法,参考文献57~61、19。
优点:考虑了交通参与者之间的相互作用,从而提高了传统基于机器学习的方法的性能。
缺点:区分有限的机动,泛化能力差。
注:在其他综述划分为基于学习的预测方法。
3 基于深度学习的预测方法
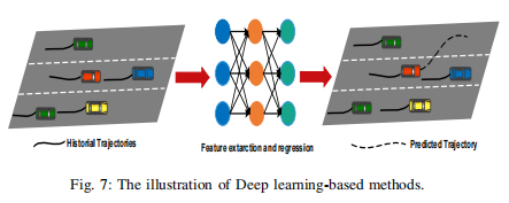
3.1 时序网络:
3.1.1 递归神经网络(Recurrent Neural Network, RNN)
参考文献20、97、66
缺陷:当处理大量的时间步长时,RNN的梯度可能会减弱或爆炸
进化一:长短期记忆网络( Long Short-Term Memory Network,LSTM),近年流行,参考21-22、66-73、92、98-101、103-104、168-171(结合其他网络的文献未全部列出)
进化二:门控循环单元( Gated Recurrent Unit,GRU),参考74、82、154
形式:单个RNN、多个RNN(处理不同环节或不同特征)
优点:处理时间依赖性效果较好
缺点:在模拟空间关系(如车辆交互)和处理类图像数据(如驾驶场景的背景)方面存在局限性;受到梯度消失或爆炸和顺序计算的限制
3.1.2 时间卷积网络(Temporal Convolutional Neural Network,TCN)-使用较少
参考77-81、105-108
优点:擅长捕捉短期和长期动态,执行高效的并行计算,并具有可解释的感受野 缺点:在表示空间关系和长期记忆方面存在局限
3.1.3 注意力机制(Attention Mechanism,AM)
参考:82-96、119-122
常用于预测网络中的一个环节:特征提取
优点:提高了模型关注相关信息、处理可变长度序列、提供可解释性以及增强对噪声的鲁棒性的能力
缺点:带来了与计算代价、模型复杂度、注意力偏差和数据依赖性相关的潜在缺陷
3.1.4 Transformer
基于注意力机制,参考24、109-118、123-127
优点:捕捉复杂的依赖关系和相互作用,提供了可扩展性、迁移学习能力以及处理多个智能体的能力
缺点:需要大量的计算资源,并可能在可解释性和数据效率方面存在挑战
3.2 基于视觉的模型
两种视角:鸟瞰(Bird-Eye-View, BEV)视角、ego-vehicle/camera视角
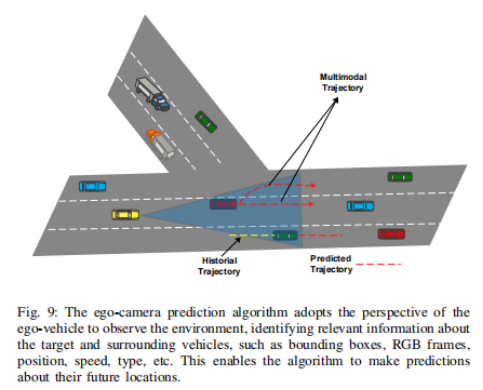
3.2.1 卷积神经网络(Convolutional Neural Network,CNN)
大多采用BEV作为输入,通过将轨迹序列视为结构化网格输入来适应轨迹预测,参考129-135、144-149
优点:在捕捉空间模式和识别轨迹数据中的空间关系方面提供了优势;在参数共享方面是高效的,可以处理更大的数据集;
缺点:可能会在建模时间依赖性和处理可变长度序列方面遇到困难
3.2.2 图神经网络(Graph Neural Network,GNN)
参考157-158
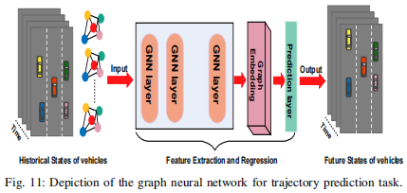
3.2.2.1 图卷积神经网络(Graph Convolutional Network,GCN)
将卷积操作从传统的图像数据处理扩展到图数据处理,其关键思想是创建一个映射函数,可以从网络中的节点特征及其邻近节点中提取交互感知特征。
参考136-143、159-160
优点:有效地捕获上下文信息,并处理不规则的图结构
缺点:在可扩展性、图构建和时间依赖性建模方面需慎重
3.2.2.2 图注意力网络(Graph Attention Network,GAT)
采用注意机制代替静态归一化卷积过程
参考150-156、166
优点:能够关注图中的相关节点(如车辆、行人),分配不同的权重来捕捉每个节点特征的重要性,以预测特定对象的轨迹
缺点:性能在很大程度上取决于图结构的质量和表示
3.2.2.3 其他图神经网络
CNN/GNN/GCN的扩展
TNT-文献163
DenseTNT-文献164
3.2.3 CNN和RNN的结合
RNN类处理时间信息、CNN类处理空间信息
参考21-22、168-171、178
3.2.4生成模型(Generative Model)
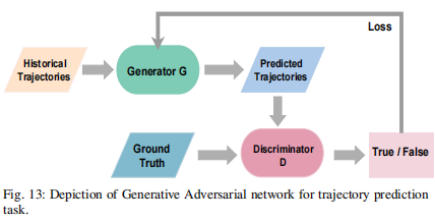
3.2.4.1 生成对抗网络( Generative Adversarial Network,GAN)
生成器将历史轨迹数据作为输入并生成未来轨迹,而判别器则对生成的轨迹进行真实感评估。生成器经过训练,通过欺骗鉴别器,使其相信生成的轨迹是真实的,从而提高生成轨迹的真实性。
参考172-177、185-186
3.2.4.2 变分自动编码器(Variational Auto Encoder,VAE)
自动编码器(AE)使用编码器压缩数据,并使用解码器对其进行解码,以产生重构输出。变分自编码器(VAE)具有跨越整个空间的生成能力,并且它解决了自编码器中非正则化潜在空间的问题。VAE的目标是将重构损失和相似损失均最小化 参考179-184
4 基于强化学习的方法
4.1 逆强化学习(Inverse Reinforcement Learning,IRL)
主要思想是学习解释智能体的观察服务行为的奖励函数,通过推断奖励函数来学习最优驾驶策略
参考187-188、190-196、201、206
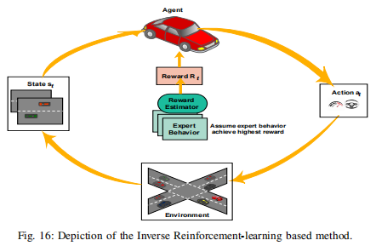
优点:IRL有潜力提供更深入的见解和更灵活的轨迹预测
缺点:最优策略可能是模糊的;难以在奖励很少或没有直接奖励函数的情况下进行训练;在实际应用中应仔细考虑对专家经验的需求以及与其质量和计算复杂性相关的挑战
4.2 深度逆强化学习(Deep Inverse Reinforcement Learning,Deep IRL)
利用深度神经网络从专家演示中学习奖励函数,参考189、197-198、200、207-208
优点:深度IRL提供了更强大和自适应的轨迹预测模型的潜力
缺点:需要仔细解决与数据需求、计算复杂性、可解释性和过拟合相关的挑战
4.3 模仿学习(Imitation Learning,IL)
目的是在不需要成本函数的情况下,根据专家的观察快速确定决策
参考209、215
常见形式:生成对抗模仿学习(Generative Adversarial Imitation Learning,GAIL),参考211、199、202、214
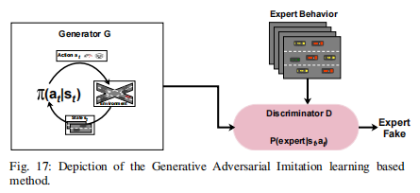
优点:可模拟人类驾驶行为和生成逼真预测
缺点:依赖于专家经验
5 训练与评估
5.1 数据集
5.1.1 NGSIM-参考文献223
NGSIM(Next Generation Simulation)数据集是美国FHWA搜集的美国高速公路行车数据,它包括了US101、I-80等道路上的所有车辆在一个时间段的车辆行驶状况。数据是采用摄像头获取,然后加工成一条一条的轨迹点记录。网址:Next Generation Simulation (NGSIM) Vehicle Trajectories and Supporting Data | Department of Transportation - Data Portal
5.1.2 highD-参考文献221
由德国亚琛工业大学汽车工程研究所发布的HighD数据集,是德国高速公路的大型自然车辆轨迹数据,搜集自德国科隆附近的六个不同地点, 位置因车道数量和速度限制而异,记录的数据中包括轿车和卡车。数据集包括来自六个地点的11.5小时测量值和110000车辆,所测量的车辆总行驶里程为45000 km,还包括了5600条完整的变道记录。通过使用最先进的计算机视觉算法,定位误差通常小于十厘米。适用于驾驶员模型参数化、自动驾驶、交通模式分析等任务。
网址:https://levelxdata.com/highd-dataset/
5.1.3 KITTI-参考文献222
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。3D目标检测数据集由7481个训练图像和7518个测试图像以及相应的点云数据组成,包括总共80256个标记对象。
网址:https://www.cvlibs.net/datasets/kitti/raw_data.php
5.1.4 Lyft-参考文献217
Lyft L5 自动驾驶数据集是由 Lyft 公司提供的 L5 级别自动驾驶数据集,目前仅提供训练集的下载。该数据集包含高质量语义地图,提供对目标的存在和移动的检测。该数据集提供超过 4000 条道路、197 条人行横道、60 个 stop sign 和 54 个停车区域等地图信息。此数据集格式为 nuScenes,数据通过两类不同版本的汽车进行采摘,两类实验车均搭载 7 个摄像头和 3 个 LiDARS,但摄像头型号和 LiDARS 种类不同。该数据集应用前景广泛,对于未来的自动化驾驶有推动作用。
网址:https://www.payititi.com/opendatasets/show-1257.html
5.1.5 Waymo-参考文献218
Waymo 开放数据集由 Waymo 自动驾驶汽车在各种条件下收集的高分辨率传感器数据组成,它与 KITTI、NuScenes 等数据集的对比数据如下,在传感器配置、数据集大小上都有很大的提升。Waymo 数据集的传感器包含 5 个激光雷达、5 个摄像头,激光雷达和摄像头的同步效果也更好。更重要的是,Waymo 数据集包含 3000 段驾驶记录,时长共 16.7 小时,平均每段长度约为 20 秒。整个数据集一共包含 60 万帧,共有大约 2500 万 3D 边界框、2200 万 2D 边界框。此外,在数据集多样性上,Waymo Open Dataset 也有很大的提升,该数据集涵盖不同的天气条件,白天、夜晚不同的时间段,市中心、郊区不同地点,行人、自行车等不同道路对象,等等。
网址:https://tensorflow.google.cn/datasets/catalog/waymo_open_dataset
5.1.6 nuScenes-参考文献216
nuScenes数据的采集来自不同城市的1000个场景中,采集车上配备了完善的传感器,包括6个相机(CAM)、1个激光雷达(LIDAR)、5个毫米波雷达(RADAR)、IMU和GPS。
网址:https://www.nuscenes.org/nuscenes
5.1.7 Argoverse-参考文献219
包括 324,557 个场景的轨迹数据,每个场景长5秒,用于训练和验证。每个场景都包含以10 Hz采样的每个跟踪对象的2D鸟瞰图质心。数据来源于自动驾驶测试车辆车队中筛选的1000多小时的驾驶数据,以找到最具挑战性的路段,包括显示十字路口车辆、左转或右转车辆以及变道车辆的路段。
网址:https://www.argoverse.org/
5.1.8 ApolloScape-参考文献159
百度公司提供的ApolloScape数据集,包括具有高分辨率图像和每像素标注的RGB视频,具有语义分割的测量级密集3D点,立体视频和全景图像。其中Scene Parsing数据集是ApolloScape的一部分,它为高级自动驾驶研究提供了一套工具和数据集。场景解析旨在为图像中的每个像素或点云中的每个点分配类别(语义)标签。它是2D / 3D场景最全面的分析之一。
网址:https://apolloscape.auto/#
5.2 常用评估指标
5.2.1 平均绝对误差(Mean Absolute Error,MAE)
5.2.2 均方根误差(Root Mean Square Error,RMSE)
5.2.3 平均位移误差(Average Displacement Error,ADE)
5.2.4 最终位移误差(Final Displacement Error,FDE)
5.2.5 最小平均位移误差(minADE)
5.2.6 最小最终位移误差(minFDE)
5.2.7 负对数似然(Negative Log Likelihood,NLL)
5.2.8 平均位移误差加权和(WSADE)
5.2.9 最终位移误差加权和(WSFDE)
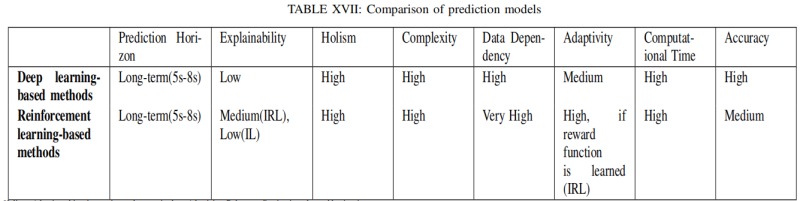
5.3 方法对比
深度学习方法 vs. 强化学习方法
1)均可用于长时预测;
2)可解释性普遍较差;
3)高度依赖于数据;
4)复杂度高,计算成本高;
5)目前基于深度学习的方法预测精度可达到最高。
6 研究挑战与未来方向
6.1 挑战
1)不确定性:交通参与者未来的轨迹本质上是不确定的,不可能以100%的准确率预测它。传感器测量中的噪声、不可预测的环境变化以及其他交通参与者的未知意图等各种因素都可能导致这种不确定性。
2)复杂动力学:交通参与者的运动可能会受到各种物理定律的影响,包括重力、摩擦力和气动力。这些动力学可以是高度复杂和非线性的,使其难以精确建模。
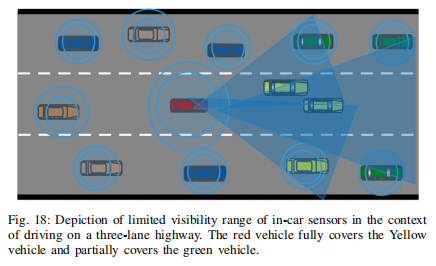
3)有限的传感器覆盖范围:自动驾驶车辆依赖一套传感器,包括摄像头、激光雷达和雷达,来感知其环境。然而,这些传感器的覆盖范围是有限的,并且可能会受到遮挡、天气条件和其他因素的影响,这些因素可能会使其难以准确跟踪其他交通代理的运动。
4)数据有限:在某些情况下,可用于轨迹预测的数据可能有限或不完整。当传感器出现故障,或者历史数据缺失或损坏时,可能会发生这种情况。
5)长期预测:在很长一段时间内(不少于3秒)预测轨迹可能是具有挑战性的,因为初始预测中的小错误可能会复合并导致与真实轨迹的重大偏差。
6)复杂的道路环境:自动驾驶车辆在复杂和动态的道路环境中运行,其中可以包括十字路口、环岛和拥挤的城市地区。在这些环境中预测轨迹需要能够处理多个交通参与者(包括其他车辆、行人和骑自行车的人)之间复杂交互的模型。
7)多模态输出:在自动驾驶中,智能体的行为表现出多模态,其中一个单一的过去轨迹可以具有多个潜在的未来轨迹。
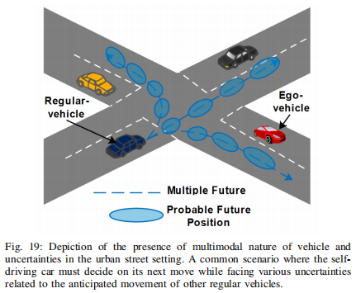
8)稀疏和嘈杂的数据:来自传感器的数据可能是稀疏和嘈杂的,特别是在建筑物和其他结构可能阻碍传感器与被跟踪对象之间的视线。这可能会使得很难准确地模拟其他交通代理随时间的运动。
9)多智能体交互:在许多现实世界的场景中,多个智能体彼此交互,它们的轨迹是相互依赖的。预测一个智能体的轨迹可能依赖于其他智能体的行为
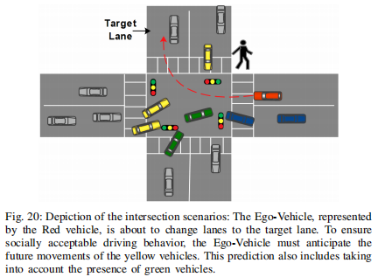
10)异质环境:异质环境是指包含多种元素的环境,如各种类型的车辆、行人、骑自行车者、不同的道路类型以及它们之间复杂的相互作用。为了有效地预测此类环境中的轨迹,预测模型需要考虑不同类型的智能体,纳入上下文信息,融合传感器数据,对多个智能体之间的交互进行建模,估计不确定性,并实现适应性。
11)安全关键应用:自动驾驶汽车是安全关键系统,轨迹预测中的错误可能会产生严重的后果,包括事故和伤害。因此,轨迹预测算法需要高度准确和可靠,并具有明确的安全边际。
12)实时约束:自动驾驶汽车在实时环境中运行,轨迹预测算法需要能够实时处理数据并生成预测。这需要高效的算法和硬件架构,能够处理传感器产生的大量数据。
6.2 未来方向
1)结合上下文和意图:当前轨迹预测方法的一个局限性是,它们往往只关注其他车辆的运动,而没有考虑到该运动背后的背景或意图。未来的研究可以探索如何结合道路布局、交通规则等上下文信息,以及其他驾驶员的意图,以提高轨迹预测精度。
2)集成多个传感器:自动驾驶车辆依赖一套传感器来感知其环境,未来的研究可以探索如何集成来自多个传感器的数据以提高轨迹预测精度。这可能涉及开发用于融合摄像机、激光雷达、雷达和其他传感器数据的新算法,以及探索声学或热传感器等新的传感器模态。
3)不确定性建模:轨迹预测具有内在的不确定性,未来的研究可以探索如何通过预测轨迹对不确定性进行建模和传播。这可能涉及开发新的概率模型,如贝叶斯神经网络,或探索不确定性量化和传播的新技术。
4)人类感知的轨迹预测:自动驾驶车辆运行的环境不仅包括其他车辆也包括行人和骑自行车的人。未来的研究可以探索如何开发能够感知人类行为的轨迹预测方法,并能够在拥挤的城市环境中准确预测行人和骑自行车的人的运动。
5)实时实现&硬件加速:自动驾驶车辆在实时环境中运行,轨迹预测算法需要能够实时处理数据并生成预测。未来的研究可以探索如何优化轨迹预测算法以获得实时性能,以及开发新的硬件架构以实现高效计算。
6)确保安全性和鲁棒性:在自动驾驶系统中,安全性至关重要。未来的研究应致力于开发优先考虑安全性和鲁棒性的轨迹预测方法。这包括调查处理罕见或异常事件的技术,提高具有挑战性的天气条件下的预测精度,并考虑轨迹预测算法中的伦理方面。
7)相对轨迹预测:相对轨迹预测是指预测周围物体或智能体相对于自我车辆或坐标系的未来运动或路径的任务。未来的研究应侧重于估计其他车辆、行人和骑自行车者相对于自身车辆的相对位移、速度和轨迹。
8)随机障碍物感知轨迹预测:这种方法是指在考虑周围环境中存在意外或随机障碍物的同时预测车辆的未来轨迹。这些障碍可以是道路之间的动物或物体,行人的突然到来,以及导致道路之间出现不确定障碍的道路事故。未来的研究应该集中在将罕见事件纳入预测模型中,并收集和分析与这些罕见事件相关的数据,以开发更全面、更鲁棒的预测模型。
9)具有挑战性的天气条件:恶劣的天气条件,如大雨、雪、雾或能见度低,会影响传感器的性能,限制用于轨迹预测的关键数据的可用性。未来的研究重点应涉及结合传感器融合、自适应滤波、概率建模和机器学习等技术,以提高恶劣天气条件下轨迹预测的可靠性和准确性。
10)车对车(V2V)通信和车对一切(V2X)通信策略: V2V通信是指车辆之间直接交换信息。V2X通信扩展到V2V之外,包括与基础设施、行人、骑自行车者和交通管理系统等其他实体的通信。通过共享位置、速度、加速度和意图等实时数据,车辆可以相互协作和配合,以提升轨迹预测性能。
11)几种方法的结合:根据具体的背景和要求,结合可以采取不同的形式,这可以导致更准确和鲁棒的轨迹预测。