












Transformer 在时间序列预测中出现了强大能力,可以描述成对依赖关系和提取序列中的多层次表示。然而,研究人员也质疑过基于 Transformer 的预测器的有效性。这种预测器通常将相同时间戳的多个变量嵌入到不可区分的通道中,并对这些时间 token 进行关注,以捕捉时间依赖性。考虑到时间点之间的数字关系而非语义关系,研究人员发现,可追溯到统计预测器的简单线性层在性能和效率上都超过了复杂的 Transformer。同时,确保变量的独立性和利用互信息越来越受到最新研究的重视,这些研究明确地建立了多变量相关性模型,以实现精确预测,但这一目标在不颠覆常见 Transformer 架构的情况下是难以实现的。
考虑到基于 Transformer 的预测器的争议,研究者们正在思考为什么 Transformer 在时间序列预测中的表现甚至不如线性模型,而在许多其他领域却发挥着主导作用。
近日,来自清华大学的一篇新论文提出了一个不同的视角 ——Transformer 的性能不是固有的,而是由于将架构不当地应用于时间序列数据造成的。

论文地址:https://arxiv.org/pdf/2310.06625.pdf
基于 Transformer 的预测器的现有结构可能并不适合多变量时间序列预测。如图 2 左侧所示,同一时间步长的点基本上代表了完全不同的物理意义,但测量结果却不一致,这些点被嵌入到一个 token 中,多变量相关性被抹去。而且,在现实世界中,由于多变量时间点的局部感受野和时间戳不对齐,单个时间步形成的标记很难揭示有益信息。此外,虽然序列变化会受到序列顺序的极大影响,但在时间维度上却没有适当地采用变体注意力机制。因此,Transformer 在捕捉基本序列表征和描绘多元相关性方面的能力被削弱,限制了其在不同时间序列数据上的能力和泛化能力。

关于将每个时间步的多变量点嵌入一个(时间)token 的不合理性,研究者从时间序列的反向视角出发,将每个变量的整个时间序列独立嵌入一个(变量)token,这是扩大局部感受野的 patching 的极端情况。通过倒置,嵌入的 token 聚集了序列的全局表征,可以更加以变量为中心,更好地利用注意力机制进行多变量关联。同时,前馈网络可以熟练地学习任意回溯序列编码的不同变量的泛化表征,并解码以预测未来序列。
研究者认为 Transformer 对时间序列预测并非无效,而是使用不当。在文中,研究者重新审视了 Transformer 的结构,并提倡将 iTransformer 作为时间序列预测的基本支柱。他们将每个时间序列嵌入为变量 token,采用多变量相关性关注,并使用前馈网络进行序列编码。实验结果表明,本文所提出的 iTransformer 在图 1 所示的实际预测基准上达到了 SOTA 水准,并出人意料地解决了基于 Transformer 的预测器的痛点。

总结来说,本文的贡献有以下三点:
- 研究者对 Transformer 的架构进行了反思,发现原生 Transformer 组件在时间序列上的能力尚未得到充分开发。
- 本文提出的 iTransformer 将独立时间序列视为 token,通过自注意力捕捉多变量相关性,并利用层归一化和前馈网络模块学习更好的序列全局表示法,用于时间序列预测。
- 通过实验,iTransformer 在真实世界的预测基准上达到了 SOTA。研究者分析了反转模块和架构选择,为未来改进基于 Transformer 的预测器指明了方向。
iTransformer
在多变量时间序列预测中,给定历史观测:
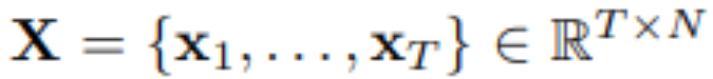
用 T 个时间步长和 N 个变量,研究者预测未来的 S 个时间步长: 。为方便起见,表示为
。为方便起见,表示为 为时间步 t 同时记录的多元变量,
为时间步 t 同时记录的多元变量, 为每个变量由 n 索引的整个时间序列。值得注意的是,在现实世界中,由于监视器的系统延迟和松散组织的数据集,
为每个变量由 n 索引的整个时间序列。值得注意的是,在现实世界中,由于监视器的系统延迟和松散组织的数据集, 可能不包含本质上相同时间戳的时间点。
可能不包含本质上相同时间戳的时间点。
 的元素可以在物理测量和统计分布中彼此不同,变量
的元素可以在物理测量和统计分布中彼此不同,变量 通常共享这些数据。
通常共享这些数据。
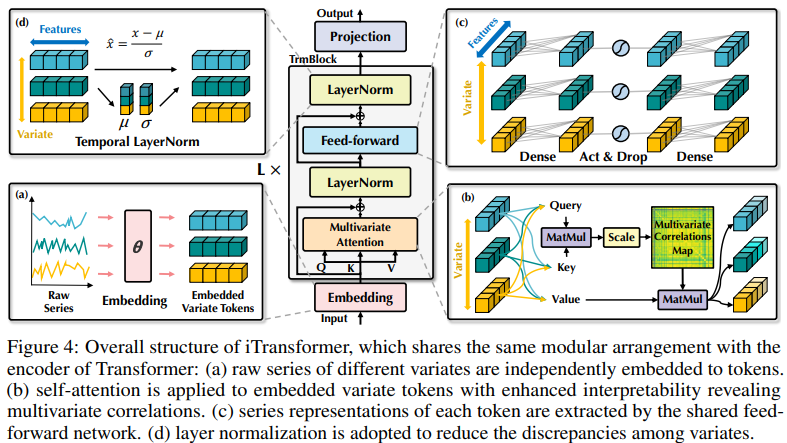
本文所提出架构配备的 Transformer 变体,称为 iTransformer,基本上没有对 Transformer 变体提出更具体的要求,只是注意力机制应适用于多元相关性建模。因此,一组有效的注意力机制可以作为插件,降低变量数量增加时关联的复杂性。
图 4 中所示的 iTransformer 利用了更简单的 Transformer 纯编码器架构,包括嵌入、投影和 Transformer 块。
实验及结果
研究者在各种时间序列预测应用中对所提出的 iTransformer 进行了全面评估,验证了所提出框架的通用性,并进一步深入研究了针对特定时间序列维度反转 Transformer 组件职责的效果。
研究者在实验中广泛纳入了 6 个真实世界数据集,包括 Autoformer 使用的 ETT、天气、电力、交通数据集、LST5 Net 提出的太阳能数据集以及 SCINet 评估的 PEMS 数据集。更多关于数据集的信息,请阅读原文。
预测结果
如表 1 所示,用红色表示最优,下划线表示最优。MSE/MAE 越低,预测结果越准确。本文所提出的 iTransformer 实现了 SOTA 性能。原生 Transformer 组件可以胜任时间建模和多元关联,所提出的倒排架构可以有效解决现实世界的时间序列预测场景。

iTransformer 通用性
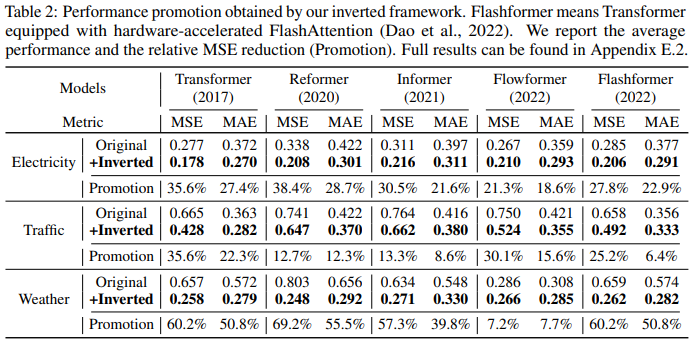
研究者将该框架应用于 Transformer 及其变体来评估 iTransformers,这些变体通常解决了 self-attention 机制的二次复杂性问题,包括 Reformer、Informer、Flowformer 和 FlashAttention。研究者发现了简单的倒置视角可以提高基于 Transformer 的预测器的性能,从而提高效率、泛化未见变量并更好地利用历史观测数据。
表 2 对 Transformers 和相应的 iTransformers 进行了评估。值得注意的是,该框架持续改进了各种 Transformer。总体而言,Transformer 平均提升了 38.9%,Reformer 平均提升了 36.1%,Informer 平均提升了 28.5%,Flowformer 平均提升了 16.8%,Flashformer 平均提升了 32.2%。
此外,由于倒置结构在变量维度上采用了注意力机制,因此引入具有线性复杂性的高效注意力从根本上解决了因 6 个变量而产生的效率问题,这一问题在现实世界的应用中十分普遍,但对于 Channel Independent 来说可能会消耗资源。因此,iTransformer 可广泛应用于基于 Transformer 的预测器。
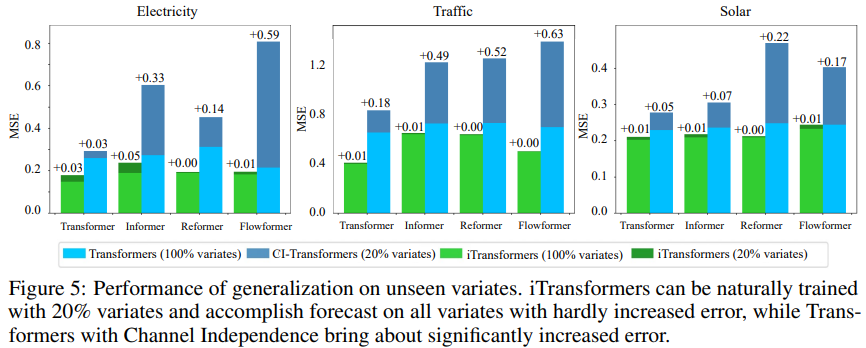
为了验证假设,研究者将 iTransformer 与另一种泛化策略进行了比较:Channel Independent 强制采用一个共享 Transformer 来学习所有变体的模式。如图 5 所示, Channel Independent(CI-Transformers)的泛化误差可能会大幅增加,而 iTransformer 预测误差的增幅要小得多。
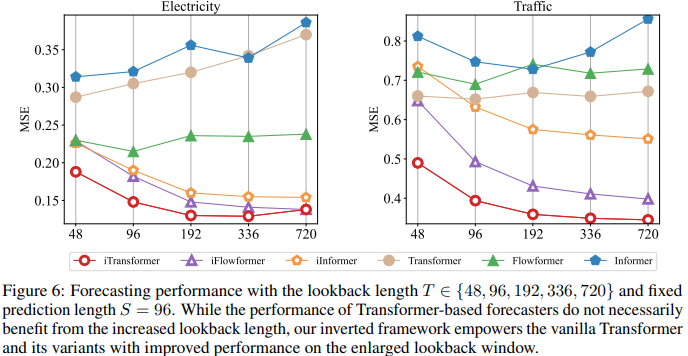
由于注意力和前馈网络的职责是倒置的,图 6 中评估了随着回视长度的增加,Transformers 和 iTransformer 的性能。它验证了在时间维度上利用 MLP 的合理性,即 Transformers 可以从延长的回视窗口中获益,从而获得更精确的预测。
模型分析
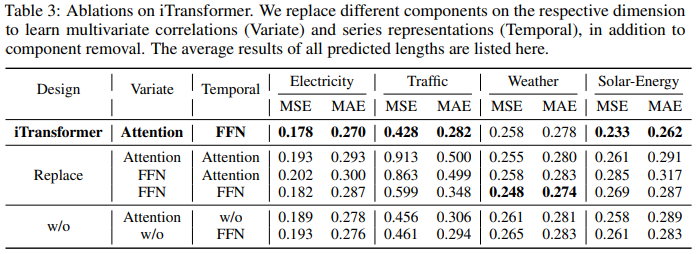
为了验证 Transformer 组件的合理性,研究者进行了详细的消融实验,包括替换组件(Replace)和移除组件(w/o)实验。表 3 列出了实验结果。
更多详细内容,请参考原文。




















