1. kube-controller-manager 对网段的管理
在 kube-controller-manager 有众多控制器,与 Pod IP 相关的是 NodeIpamController。
NodeIpamController 控制器主要是管理节点的 podcidr,当有新节点加入集群时,分配一个子网段给节点;当节点删除时,回收子网段。
每个节点的子网段不会重叠,每个节点都能够独立地完成 Pod IP 的分配。
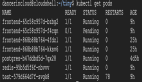
下面看一个 kube-controller-manager 的运行示例:
其中关于网段配置的部分为:
cluster-cidr 指定了 Pod IP 的范围,掩码位数 16,如果不考虑保留 IP,意味着集群最多可以容纳 2^16 = 65536 个 pod。
这些 Pod 分布在若干个节点上,接着看 node-cidr-mask-size 为 24,每个节点只剩下 32-24=8 位留给 pod,每个节点最多能创建 2^8=256 个 pod。
相应的,这个集群能够容纳的节点数量为 2^(32-16-8)=256 个节点。
在规划集群时,需要根据集群的规模来调整这两个参数。
开启 allocate-node-cidrs、设置 cluster-cidr 之后,kube-controller-manager 会给每个节点分配子网段,将结果写入 spec.podCIDR 字段。
下面我们从源码分析一下这一过程。
1. 启动 NodeIpamController
RunWithMetrics 只是提供了一些监控指标,真正的启动逻辑在 Run 方法中。
1.2 监听节点变化
在查找 cidrAllocator 接口实现的时候,我发现了三种 CIDR 分配器,分别是 RangeAllocator 适用单网段分配、MultiCIDRRangeAllocator 适用于多 CIDR、CloudCIDRAllocator 适用于对接云厂。
这里看看 RangeAllocator 的实现。
其实 RangeAllocator 分配器的实现与写 Operator 时的控制器类似,都是通过 informer 来监听资源的变化,然后调用相应的方法。
1.3 更新节点的 podCIDR
这里比较特殊的是,控制器并不是直接操作资源,而是将变更放到了一个 channel 中,然后通过 goroutine 处理状态更新。
nodeCIDRUpdateChannel 的长度是 5000。
而更新 Node Spec 的逻辑是通过 30 个 goroutine 来处理。
cidrUpdateRetries = 3 这里会重试 3 次更新,如果一直更新失败,会将节点重新放入 channel 中,等待下次更新。
使用 Patch 方法更新节点对象的 Spec 字段。
2. kubelet 对网络的配置
 图片
图片
上图是 Kubelet 创建 Pod 的过程,这里截取其中对网络配置的部分进行分析:
- Pod 调度到某个节点上
- kubelet 通过 cri 调用 container runtime 创建 sandbox
- container runtime 创建 sandbox
- container runtime 调用 cni 创建 Pod 网络
- IPAM 对 Pod IP 的管理
下面从源码实现的角度来看看这个过程。
2.1 Pod 调度到某个节点上
Kubernetes 中调度的过程是 kube-scheduler 根据 Pod 的资源需求和节点的资源情况,将 Pod 调度到某个节点上,并将调度结果写入 pod.spec.nodeName 字段。
这部分不是网络的重点,之前我也在生产环境下定制过调度器,感兴趣的话可以看看Tekton 优化之定制集群调度器 。
2.2 kubelet 调用 cri 创建 sandbox
SyncPod 是 kubelet 中的核心方法,它会根据 Pod 的状态,调用 cri 创建或删除 pod。
调用 RuntimeService 接口的 RunPodSandbox 方法创建 sandbox。
经过 runtimeService、instrumentedRuntimeService 接口的封装,最终会调用 remoteRuntimeService 的 RunPodSandbox 方法。
这里的 runtimeClient 是一个 rpc client,通过 rpc 调用 container runtime 创建 sandbox。
2.3 container runtime 创建 sandbox
以 containerd 为例,创建 sandbox:
调用 CNI 创建网络,创建 sandbox。
2.4 container runtime 调用 cni 创建 Pod 网络
在上一步骤中,调用 RunPodSandbox 创建 sandbox 之前,会先调用 setupPodNetwork 配置网络。这里展开看一下 setupPodNetwork 的实现。
libcni 实现了 netPlugin 接口
attachNetworks 起了很多协程,每个协程调用 asynchAttach 方法,asynchAttach 方法调用 Attach 方法。
运行了很多协程调用 CNI,但 rc channel 的长度为 1,处理结果时却一个一个的。
Attach 方法中才真正开始调用 CNI 插件。
在 https://github.com/containernetworking/cni/blob/main/libcni/api.go 中 CNI 接口定义了很多方法,其中最重要的是 AddNetwork 和 DelNetwork 方法,带 List 的方法是批量操作。
AddNetwork 用于为容器添加网络接口,在主机上创建 veth 网卡绑定到容器的 ech0 网卡上。DelNetwork 用于在容器删除时,清理容器相关的网络配置。
CNI 调用插件的核心是 Exec 接口,直接调用二进制程序。
CRI 以标准输入、环境变量的形式将网络配置信息传递给 CNI 插件。CNI 插件处理完成之后,将网络配置信息写入到标准输出中,CRI 将标准输出中的网络配置信息解析出来,写入到容器的网络配置文件中。
再回到 container runtime 的实现 containerd:
这里的 /etc/cni/net.d 是 CNI 网络配置文件的默认存放路径,/opt/cni/bin 是 CNI 网络插件的默认搜索路径。
这些配置用来初始化 CRI 获取 CNI 插件的 netPlugin map[string]cni.CNI 结构。
2.5 IPAM 对 Pod IP 的管理
IPAM 是 IP Address Management 的缩写,负责为容器分配 ip 地址。IPAM 组件通常是一个独立的二进制文件,也可以直接由 CNI 插件实现。在 https://github.com/containernetworking/plugins/tree/main/plugins/ipam 中,目前有三种实现 host-local、dhcp、static。 这里以 host-local 为例:
- 查看 CNI 的配置文件
指定了 CNI 插件的类型为 host-local,指定了 Pod IP 的网段为 "10.234.58.0/24" 。
- 查看 CNI 插件的存储目录
这里有一组以 ip 命名的文件,而文件里面又是一串字符串。那么这些到底是什么呢?
- 以 ip 命名的文件是如何生成的
申请一个 Pod IP 时,先获取一个可用 ip
获取到可用 ip 之后,先尝试着存储到本地目录文件中
直接写本地文件目录
写入的内容为 strings.TrimSpace(id) + LineBreak + ifname,这里的 id 其实是容器的 id,ifname 是网卡名称,LineBreak 是换行符。
通过 id 在主机上可以找到对应的容器:
- last_reserved_ip.0 文件的用途
在获取可用 IP 时,IPAM 会创建一个迭代器。
而迭代器需要依靠 last_reserved_ip.0 找到上一次分配的 IP,然后从这个 IP 之后开始分配。
这里的 lastIPFilePrefix = "last_reserved_ip."
host-local 分配 ip 时是按照轮询的方式,递增分配,如果分配到最后一个 IP,就又从头开始分配。
- lock 文件
每次存储操作都会进行加锁,IP 分配不会并发进行,确保唯一性。
3. 总结
本篇主要是从 Pod IP 管理的角度,梳理了一下从 kube-controller-manager 到 kubelet 的 Pod IP 管理过程。主要内容如下:
- kube-controller-manager 通过 NodeIpamController 控制器为每个节点分配 Pod IP 网段,在集群规划时需要根据集群规模调整 cluster-cidr、node-cidr-mask-size 参数
- kubelet 通过 cri 调用 container runtime 创建 sandbox
- container runtime 调用 cni 创建 Pod 网络
- IPAM 对 Pod IP 的管理
在工作中很多熟悉的路径,可能仅仅只是知道大概的流程,不知道具体的实现。通过源码分析,可以更加深入地了解相关的细节,也能学习到新的知识。
比如,在源码中,我看到了 InPlacePodVerticalScaling 这个参数,发现是 Kubernetes 1.27 的一个 alpha 特性,可以在不重启 Pod 的情况下,调整 Pod 的资源配置;在写 Operator 更新 CR 状态时,在合适的场景下,可以学习 nodeCIDRUpdateChannel 的实现,将更新的状态放入 channel 中,然后通过 goroutine 处理状态更新。