1. 服务发现模式
第一个就是服务发现的模式,服务发现里面其实有两种模式(边车模式,Sidecar暂时范围不是很广),这两种模式对应不同的适用场景会有不同的效果。
 图片
图片
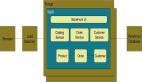
直联模式,客户端从注册中心发现服务端的列表并缓存在本地,这种模式适合于语言统一的这种内网通信,为什么呢?因为直连模式里面大部分 RPC 采用的这样的模式,主要是比较简单、高效,而且在统一语言的内网通信里面,这种服务端的实例的变更通知是比较简单的。
 图片
图片
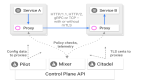
代理模式,服务端注册到网关上,客户端对一个服务端其实是无感知的,这种模式比较适合于外网服务,因为当你的服务端变更的时候,客户端其实是不需要去感知,也不需要对此进行任何变更,这样对外网来说,其实用户侧的设备是不需要去关注信息的,这样通知起来就比较简单。但是它也会面临一个问题,它会多一条的通信,从性能或者效率上来说,肯定是不如直连模式的。
2. 服务通信模式
服务通信模式里面主要有两种,大家其实日常里面比较经常会碰到就是同步的编程模式,这种模式比较简单易懂,非常符合人类的思考习惯,它比较适用于时间比较敏感的、吞吐量也比较小的这种场景。但是这种通信的方式在吞吐量比较大、QPS 比较高的场景里面就会有一系列的问题,比如说可能会把你的资源耗尽,但其实这些资源都处于等待中。比如我们在 Java 里面可能会有线程池的资源,使用起来其实是比较低效的。然后在异步的这种场景里面,它其实比较适用于高吞吐、削峰填谷的作用。
其实这里面会有几种,从我们的实践上来看的话,比如说搜索系统它其实是一个非常高并发的场景,其实对于这种高吞吐的场景下是必须要用异步的,不然的话其实资源的损耗是非常高的,我们在某些系统上做过改造,由原来的同步改为异步的话,基本上可以节省掉 80% 左右的机器的资源。除此之外,交易系统的事件驱动也是比较适合异步的一个场景,因为交易系统的事件其实是非常关键的,但是它又不能每个人都去通知,因为很多人都需要关注这个事件,这个时候利用 MQ 等方式去做这种事件的驱动是比较合适的。
 图片
图片
3. 设计模式
从设计模式上来说的话,我们其实可以知道在互联网的架构里面,特别是在高并发的模式里面,我们有很多折中,这些折中里面其实会有不同的模式和它的沉淀。比如说像 BASE 这样的模式,它其实不追求强一致性,它是有这种基本的可用和软状态这样的优点,进而去避免因为强一致导致的其他的不可用性。
 图片
图片
第二个就是 CQRS,这个模式其实非常有用,至少我发现很多场景是能够用上它的,换句话说其实只要是数据异构的这种场景,都是比较适合去使用它的,当然这取决于你的查询模式。大家都知道查询模式其实有很多种的,比如说像 KV 的查询模式、复杂条件的 Query,除此之外,还有 Scan 这种扫描形式,不同的查询形式会对应着不同的存储结构是比较合适的。但是我们在对这些数据进行操作的时候,其实它的数据载体是唯一的,那这个数据载体怎么样才能支持多种的查询模式呢?其实这里面就需要对这些数据进行异构,比如说像我们的订单、配置等等这些方式都需要去进行一定的异构。
服务治理实践
常见的服务治理的四板斧是:
1. 常规四板斧
 图片
图片
不可避免地,第一,我们一定要设置超时;第二,要在一些场景里面去考虑重试的逻辑;第三,考虑熔断的逻辑,不要被下游拖死;第四,一定要有限流的逻辑,不要被上游打死。
2. 最终目标
 图片
图片
稳定可用指的就是我们通过各类的防控手段去达到在可用的容量场景下,提供有效的服务,这样才能叫稳定可用。第二个可观测,就是我们从多个维度,比如说像关系、性能、异常、资源等维度对它进行度量并且分析。第三个防腐化,我们的代码和架构其实不可避免地都是在腐化的一个过程之中,我们不停地往里面去添加东西的过程中,其实也会缺乏一定的治理。我们服务治理的目标,其中一点就是要做到如何去对它进行防腐,这个里面有一些考虑的维度,比如服务的层级,你的服务并不是越微越好,也不是层级越多越好,所以服务的层级一定要有所控制。
3. 保护机制
第二就是链路的分析,链路里面上下游的超时、串行、并行的调用等等之类的这些东西在编码的过程中可能会被忽略掉的,这些我们其实可以通过偏后置一点的方式对它进行一个分析和预警,这里面提一下我们在保护机制上做的一些工作,我们都知道在 RPC 的框架里面,其实特别是在直连的模式下,调用端 Consumer 端和 Provider 端其实是直连通信的。
对于注册中心来说,它只负责一个注册和变更通知的作用,但是在有一些特定的场景里面并不是这样子的。举个例子来说,当一个注册中心因为自身的原因处于一个半死不活的状态,它一会儿能服务、一会儿不能服务的时候,就会发生一个比较恐怖的事情,Provider 端因为它要跟注册中心去保持心跳判活的状态,所以需要和注册中心保持长期有效的连接。如果是失效的情况,作业中心就会判断这个 Provider 是不存活了。不存活的时候,注册中心就会把这个消息通知给 Consumer 端,Consumer 端只要接收过一次下线通知,Consumer 就会从它的列表里面把这个 Provider 从本地的缓存里面去移除掉。
 图片
图片
如果注册中心处于一个半死不活的状态,最后会处于一个什么状态呢?Consumer 端慢慢地会把所有的 Provider 都移除掉,这样就会导致我们的 Consumer 端到 Provider 端其实是不可通信的。对于这个问题,我们其实基于 Dubbo 做了一定的改造,做了一个保护机制。这个保护机制就是当 Provider,特别是注册中心上的 Provider 数少于一定的阈值的时候,我们的保护机制就会自动地启用,它的生效是在 Consumer 端的,也就意味着 Consumer 端需要缓存这段时间内所有历史的 Provider 的列表。
大家可能在这里会有一点担心,你缓存的 Provider 如果失效了怎么办?它是真的失效了,比如说它被下线了,或者是它本身经过迁移,像我们在容器场景里面,经过了一定的发布,其实它对应的信息都变化了,这个时候你再去通信不就有问题吗?其实我们在保护机制里面也考虑了这个问题,我们在通信之前还是会做一个直连的检查,Consumer 到 Provider 的连接存活是否是真正存在,如果不存在,我们会把这一个连接给扔掉,保证通信的时候使用的是一个可用的连接。
当这个信息机制启用了之后,注册中心恢复到一定的状态的,这个 Provider 又能重新注册到注册中心里面了,接着我们又会把保护机制自动关闭掉,这样的话 Consumer 就只会调用注册中心上存活的这些 Provider,就可以避免掉因为注册中心半死不活,导致所有的这些分布式的应用里面的 RPC 调用是不可用的。
这其实是一个比较有效的方式,因为如果出现了这种场景,其实你内网里面的大部分应用通信其实是处于一个不可用的状态,甚至你想让它恢复都是非常困难的事情。比如你想启动的时候,其实 Consumer 发现 Provider 都不存活了,这也会导致启动失败等等各方面的问题。
4. 动态限流
接着我来介绍一下限流里面我们做的一些工作,这里面我们做的模式我把它叫做动态限流。普通的一个限流里面,通常来说是这样的一个方式,我们有 A、B、C 的服务都对 X 这个服务进行了调用,它的来源可能是不一样的,X 为了保护自身的状态是可用的,它不可避免就要对上游 A、B、C 的这些访问分配固定的一些配额,谁超过了配额就不可用了。
 图片
图片
比如说像 A 分配了 100、B 也分配 100、C 分配给了 50。当 A 超过了 100 的时候,其实它的一些请求是会被拒绝掉的,这个是基于容量的考虑,X 不可能具备无限的容量,这时它需要一定的保护措施。但是这地方就会有一个问题,假如 A、B、C 里面,比如说 B 服务,它其实是从 App 过来的,它的价值不可避免来说的话,要更高一点。比如说第三个服务 C,它是从 Web 里面来,它的价值相对来说比较低一点。这个价值是基于你的业务形态来的,比如说你的 App 的成单、转化更高,那就意味着它的请求更珍贵。
这个里面就会出现一个问题,服务 B 和服务 C 自己都得到了一定数量的配额,但是假如 App 的流量上涨了,Web 的流量没有上涨,这时就会面临一个问题,服务 C 的配额没用完,但是服务 B 的配额又不够用,这个场景下怎么解决呢?就需要靠人工来不停地去调整它,而且这个调整需要相当实时才可以,我们有没有办法能够相对统一地解决这个问题呢,其实我们做了一个探索,这个探索从实践结果来看的话是比较有效的。
 图片
图片
我们对这些服务进行配额分配的时候,其实不是一个固定的配额,而是一个动态的分配。动态的分配意思就是,我只有一个总的容量,并不给每一个服务进行分配,总的容量我分配给所有人。但是我要对所有的调用方进行一个排序,也就是说谁的价值高谁就排在前面,这样的话就能得到一个比较有效的结果。你的限流模型是基于你的业务逻辑来的,也是基于你的业务价值来的,当你发生限流的时候,优先丢掉的一定是最没有价值的那部分的业务请求。
当然这里面也会有一个前提,你的请求来源是需要有差异化的。还有第二个点,你的这些 trace 连通性一定要高,也就意味着,你的这些标志要能够一路畅通地携带下去,如果只是基于某一层去做限流逻辑,其实是没有意义的。
5. 防腐化
接着就是防腐化,这里面其实我们需要对架构、应用的分布、应用的关系去做大量的分析,得出改进的措施,我们在这上面改进的措施其实有很多。比如我们会分析哪些应用是频繁修改的,这些频繁修改的意思是不是所有的需求,这些应用都相关地需要去做修改,那就意味着说它的业务域是一样的。如果这些业务域一样的情况下,你把它的微服务划分得很细,实际上它是一一绑定的话,其实并不符合微服务化的原则。
第二个是否存在重复的调用,这条链路里面,这些重复的调用是否能够去缓存化,或者是避免它重复调用。
第三个大量的串行调用是不是能够把它异步化,比如常见的,从数据库里面拿出一批记录,这一批记录通过循环的方式,挨个去对它发起远程调用,这些过程里面其实比较有效的方式就是通过异步化、并行化的方式去把速度给提上来。
第四个异步的整个链路的这些超时配置里面,其实会有一定的相关的关系。比如上游的超时是不应该比下游短的,如果下游的超时比上游的还长,那意味着说下游还在计算,上游可能已经超时了,这个计算的结果其实有可能返回不了上游,这些就是无用的配置。除了这之外其实整个链路里面大量的超时可能是不合理的,比如刚才提到的大量重复的调用,这些重复的调用或者循环的调用,再乘以同样的超时时间,可能就会比整个终端的操作时间要长很多,这些都需要去做一定的分析和考虑,才能达到它防腐化的目的。