接着上篇《PyTorch简明教程上篇》,继续学习多层感知机,卷积神经网络和LSTMNet。
1、多层感知机
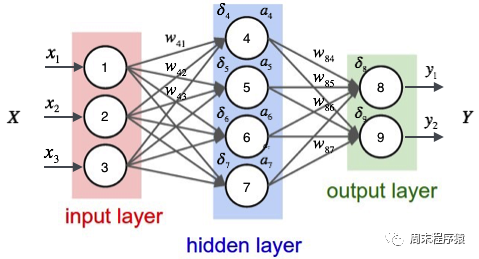
多层感知机通过在网络中加入一个或多个隐藏层来克服线性模型的限制,是一个简单的神经网络,也是深度学习的重要基础,具体图如下:
(1)以上代码和单层神经网络的代码类似,区别是build_model构建一个包含三个线性层和两个ReLU激活函数的神经网络模型:
- 向模型中添加第一个线性层,该层的输入特征数量为input_dim,输出特征数量为512;
- 接着添加一个ReLU激活函数和一个Dropout层,用于增强模型的非线性能力和防止过拟合;
- 向模型中添加第二个线性层,该层的输入特征数量为512,输出特征数量为512;
- 接着添加一个ReLU激活函数和一个Dropout层;
- 向模型中添加第三个线性层,该层的输入特征数量为512,输出特征数量为output_dim,即模型的输出类别数量;
(2)什么是ReLU激活函数?ReLU(Rectified Linear Unit,修正线性单元)激活函数是深度学习和神经网络中常用的一种激活函数,ReLU函数的数学表达式为:f(x) = max(0, x),其中x是输入值。ReLU函数的特点是当输入值小于等于0时,输出为0;当输入值大于0时,输出等于输入值。简单来说,ReLU函数就是将负数部分抑制为0,正数部分保持不变。ReLU激活函数在神经网络中的作用是引入非线性因素,使得神经网络能够拟合复杂的非线性关系,同时,ReLU函数相对于其他激活函数(如Sigmoid或Tanh)具有计算速度快、收敛速度快等优点;
(3)什么是Dropout层?Dropout层是一种在神经网络中用于防止过拟合的技术。在训练过程中,Dropout层会随机地将一部分神经元的输出置为0,即"丢弃"这些神经元,这样做的目的是为了减少神经元之间的相互依赖,从而提高网络的泛化能力;
(4)print("Epoch %d, cost = %f, acc = %.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输出如下:
可以看出最后相同的数据分类,准确率比单层神经网络要高(98.59% > 97.68%)。
2、卷积神经网络
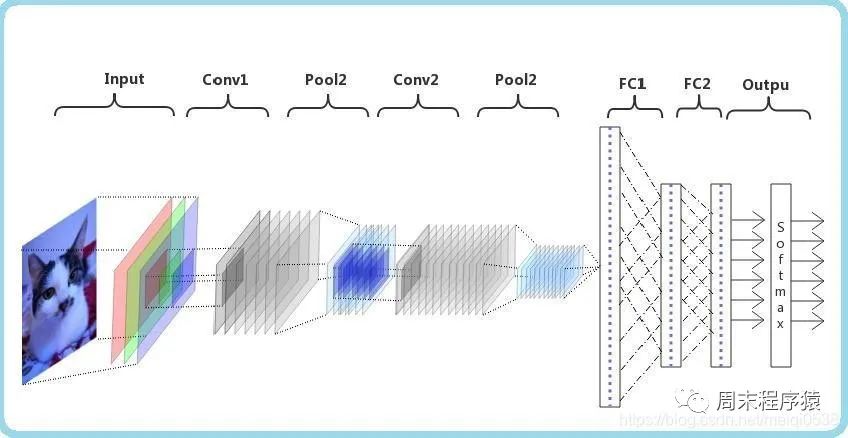
卷积神经网络(CNN)是一种深度学习算法,如果输入一个矩阵,CNN能够区分出重要的部分和不重要的部分(分配权重),相比较其他分类任务,CNN对数据预处理的要求不是很高,只要经过足够的训练,就可以学习到矩阵中的特征,如下图:
import numpy as np
import torch
from torch.autograd import Variable
from torch import optim
from data_util import load_mnist
class ConvNet(torch.nn.Module):
def __init__(self, output_dim):
super(ConvNet, self).__init__()
self.conv = torch.nn.Sequential()
self.conv.add_module("conv_1", torch.nn.Conv2d(1, 10, kernel_size=5))
self.conv.add_module("maxpool_1", torch.nn.MaxPool2d(kernel_size=2))
self.conv.add_module("relu_1", torch.nn.ReLU())
self.conv.add_module("conv_2", torch.nn.Conv2d(10, 20, kernel_size=5))
self.conv.add_module("dropout_2", torch.nn.Dropout())
self.conv.add_module("maxpool_2", torch.nn.MaxPool2d(kernel_size=2))
self.conv.add_module("relu_2", torch.nn.ReLU())
self.fc = torch.nn.Sequential()
self.fc.add_module("fc1", torch.nn.Linear(320, 50))
self.fc.add_module("relu_3", torch.nn.ReLU())
self.fc.add_module("dropout_3", torch.nn.Dropout())
self.fc.add_module("fc2", torch.nn.Linear(50, output_dim))
def forward(self, x):
x = self.conv.forward(x)
x = x.view(-1, 320)
return self.fc.forward(x)
def train(model, loss, optimizer, x_val, y_val):
model.train()
optimizer.zero_grad()
fx = model.forward(x_val)
output = loss.forward(fx, y_val)
output.backward()
optimizer.step()
return output.item()
def predict(model, x_val):
model.eval()
output = model.forward(x_val)
return output.data.numpy().argmax(axis=1)
def main():
torch.manual_seed(42)
trX, teX, trY, teY = load_mnist(notallow=False)
trX = trX.reshape(-1, 1, 28, 28)
teX = teX.reshape(-1, 1, 28, 28)
trX = torch.from_numpy(trX).float()
teX = torch.from_numpy(teX).float()
trY = torch.tensor(trY)
n_examples = len(trX)
n_classes = 10
model = ConvNet(output_dim=n_classes)
loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
batch_size = 100
for i in range(100):
cost = 0.
num_batches = n_examples // batch_size
for k in range(num_batches):
start, end = k * batch_size, (k + 1) * batch_size
cost += train(model, loss, optimizer,
trX[start:end], trY[start:end])
predY = predict(model, teX)
print("Epoch %d, cost = %f, acc = %.2f%%"
% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))
if __name__ == "__main__":
main()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
(1)以上代码定义了一个名为ConvNet的类,它继承自torch.nn.Module类,表示一个卷积神经网络,在__init__方法中定义了两个子模块conv和fc,分别表示卷积层和全连接层。在conv子模块中,我们定义了两个卷积层(torch.nn.Conv2d)、两个最大池化层(torch.nn.MaxPool2d)、两个ReLU激活函数(torch.nn.ReLU)和一个Dropout层(torch.nn.Dropout)。在fc子模块中,定义了两个线性层(torch.nn.Linear)、一个ReLU激活函数和一个Dropout层;
(2)定义池化层的目的?池化层(Pooling layer)是CNN中的一个重要组成部分。池化层的主要目的有以下几点:
- 降低维度:池化层通过对输入特征图(Feature maps)进行局部区域的下采样操作,降低了特征图的尺寸。这样可以减少后续层中的参数数量,降低计算复杂度,加速训练过程;
- 平移不变性:池化层可以提高网络对输入图像的平移不变性。当图像中的某个特征发生小幅度平移时,池化层的输出仍然具有相似的特征表示。这有助于提高模型的泛化能力,使其能够在不同位置和尺度下识别相同的特征;
- 防止过拟合:通过减少特征图的尺寸,池化层可以降低模型的参数数量,从而降低过拟合的风险;
- 增强特征表达:池化操作可以聚合局部区域内的特征,从而强化和突出更重要的特征信息。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling),分别表示在局部区域内取最大值或平均值作为输出;
(3)print("Epoch %d, cost = %f, acc = %.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输出如下:
可以看出最后相同的数据分类,准确率比多层感知机要高(99.10% > 98.59%)。
3、LSTMNet
LSTMNet是使用长短时记忆网络(Long Short-Term Memory, LSTM)构建的神经网络,核心思想是引入了一个名为"记忆单元"的结构,该结构可以在一定程度上保留长期依赖信息,LSTM中的每个单元包括一个输入门(input gate)、一个遗忘门(forget gate)和一个输出门(output gate),这些门的作用是控制信息在记忆单元中的流动,以便网络可以学习何时存储、更新或输出有用的信息。
import numpy as np
import torch
from torch import optim, nn
from data_util import load_mnist
class LSTMNet(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(LSTMNet, self).__init__()
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(input_dim, hidden_dim)
self.linear = nn.Linear(hidden_dim, output_dim, bias=False)
def forward(self, x):
batch_size = x.size()[1]
h0 = torch.zeros([1, batch_size, self.hidden_dim])
c0 = torch.zeros([1, batch_size, self.hidden_dim])
fx, _ = self.lstm.forward(x, (h0, c0))
return self.linear.forward(fx[-1])
def train(model, loss, optimizer, x_val, y_val):
model.train()
optimizer.zero_grad()
fx = model.forward(x_val)
output = loss.forward(fx, y_val)
output.backward()
optimizer.step()
return output.item()
def predict(model, x_val):
model.eval()
output = model.forward(x_val)
return output.data.numpy().argmax(axis=1)
def main():
torch.manual_seed(42)
trX, teX, trY, teY = load_mnist(notallow=False)
train_size = len(trY)
n_classes = 10
seq_length = 28
input_dim = 28
hidden_dim = 128
batch_size = 100
epochs = 100
trX = trX.reshape(-1, seq_length, input_dim)
teX = teX.reshape(-1, seq_length, input_dim)
trX = np.swapaxes(trX, 0, 1)
teX = np.swapaxes(teX, 0, 1)
trX = torch.from_numpy(trX).float()
teX = torch.from_numpy(teX).float()
trY = torch.tensor(trY)
model = LSTMNet(input_dim, hidden_dim, n_classes)
loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
for i in range(epochs):
cost = 0.
num_batches = train_size // batch_size
for k in range(num_batches):
start, end = k * batch_size, (k + 1) * batch_size
cost += train(model, loss, optimizer,
trX[:, start:end, :], trY[start:end])
predY = predict(model, teX)
print("Epoch %d, cost = %f, acc = %.2f%%" %
(i + 1, cost / num_batches, 100. * np.mean(predY == teY)))
if __name__ == "__main__":
main()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
(1)以上这段代码通用的部分就不解释了,具体说LSTMNet类:
- self.lstm = nn.LSTM(input_dim, hidden_dim)创建一个LSTM层,输入维度为input_dim,隐藏层维度为hidden_dim;
- self.linear = nn.Linear(hidden_dim, output_dim, bias=False)创建一个线性层(全连接层),输入维度为hidden_dim,输出维度为output_dim,并设置不使用偏置项(bias);
- h0 = torch.zeros([1, batch_size, self.hidden_dim])初始化LSTM层的隐藏状态h0,全零张量,形状为[1, batch_size, hidden_dim];
- c0 = torch.zeros([1, batch_size, self.hidden_dim])初始化LSTM层的细胞状态c0,全零张量,形状为[1, batch_size, hidden_dim];
- fx, _ = self.lstm.forward(x, (h0, c0))将输入数据x以及初始隐藏状态h0和细胞状态c0传入LSTM层,得到LSTM层的输出fx;
- return self.linear.forward(fx[-1])将LSTM层的输出传入线性层进行计算,得到最终输出。这里fx[-1]表示取LSTM层输出的最后一个时间步的数据;
(2)print("Epoch %d, cost = %f, acc = %.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输出如下:
4、辅助代码
两篇文章的from data_util import load_mnist的data_util.py代码如下: