前面几篇文章介绍了特征归一化和张量,接下来开始写两篇PyTorch简明教程,主要介绍PyTorch简单实践。
1、四则运算
import torch
a = torch.tensor([2, 3, 4])
b = torch.tensor([3, 4, 5])
print("a + b: ", (a + b).numpy())
print("a - b: ", (a - b).numpy())
print("a * b: ", (a * b).numpy())
print("a / b: ", (a / b).numpy())加减乘除就不用多解释了,输出为:
a + b: [5 7 9]
a - b: [-1 -1 -1]
a * b: [ 6 12 20]
a / b: [0.6666667 0.75 0.8 ]2、线性回归
线性回归是找到一条直线尽可能接近已知点,如图:
 图1
图1
import torch
from torch import optim
def build_model1():
return torch.nn.Sequential(
torch.nn.Linear(1, 1, bias=False)
)
def build_model2():
model = torch.nn.Sequential()
model.add_module("linear", torch.nn.Linear(1, 1, bias=False))
return model
def train(model, loss, optimizer, x, y):
model.train()
optimizer.zero_grad()
fx = model.forward(x.view(len(x), 1)).squeeze()
output = loss.forward(fx, y)
output.backward()
optimizer.step()
return output.item()
def main():
torch.manual_seed(42)
X = torch.linspace(-1, 1, 101, requires_grad=False)
Y = 2 * X + torch.randn(X.size()) * 0.33
print("X: ", X.numpy(), ", Y: ", Y.numpy())
model = build_model1()
loss = torch.nn.MSELoss(reductinotallow='mean')
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
batch_size = 10
for i in range(100):
cost = 0.
num_batches = len(X) // batch_size
for k in range(num_batches):
start, end = k * batch_size, (k + 1) * batch_size
cost += train(model, loss, optimizer, X[start:end], Y[start:end])
print("Epoch = %d, cost = %s" % (i + 1, cost / num_batches))
w = next(model.parameters()).data
print("w = %.2f" % w.numpy())
if __name__ == "__main__":
main()(1)先从main函数开始,torch.manual_seed(42)用于设置随机数生成器的种子,以确保在每次运行时生成的随机数序列相同,该函数接受一个整数参数作为种子,可以在训练神经网络等需要随机数的场景中使用,以确保结果的可重复性;
(2)torch.linspace(-1, 1, 101, requires_grad=False)用于在指定的区间内生成一组等间隔的数值,该函数接受三个参数:起始值、终止值和元素个数,返回一个张量,其中包含了指定个数的等间隔数值;
(3)build_model1内部实现:
- torch.nn.Sequential(torch.nn.Linear(1, 1, bias=False))中使用nn.Sequential类的构造函数,将线性层作为参数传递给它,然后返回一个包含该线性层的神经网络模型;
- build_model2和build_model1功能一样,使用add_module()方法向其中添加了一个名为linear的子模块;
(4)torch.nn.MSELoss(reductinotallow='mean')定义损失函数;
(5)optim.SGD(model.parameters(), lr=0.01, momentum=0.9)实现随机梯度下降(Stochastic Gradient Descent,SGD)优化算法;
(6)通过batch_size将训练集拆分,循环100次;
(7)接下来是训练函数train,用于训练一个神经网络模型,具体来说,该函数接受以下参数:
- model:神经网络模型,通常是一个继承自nn.Module的类的实例;
- loss:损失函数,用于计算模型的预测值与真实值之间的差异;
- optimizer:优化器,用于更新模型的参数;
- x:输入数据,是一个torch.Tensor类型的张量;
- y:目标数据,是一个torch.Tensor类型的张量;
(8)train是PyTorch训练步骤的通用方法,步骤如下:
- 将模型设置为训练模式,即启用dropout和batch normalization等训练时使用的特殊操作;
- 将优化器的梯度缓存清零,以便进行新一轮的梯度计算;
- 将输入数据传递给模型,计算模型的预测值,并将预测值与目标数据传递给损失函数,计算损失值;
- 对损失值进行反向传播,计算模型参数的梯度;
- 使用优化器更新模型参数,以最小化损失值;
- 返回损失值的标量值;
(9)print("Epoch = %d, cost = %s" % (i + 1, cost / num_batches))最后打印当前训练的轮次和损失值,上述的代码输出如下:
...
Epoch = 95, cost = 0.10514946877956391
Epoch = 96, cost = 0.10514946877956391
Epoch = 97, cost = 0.10514946877956391
Epoch = 98, cost = 0.10514946877956391
Epoch = 99, cost = 0.10514946877956391
Epoch = 100, cost = 0.10514946877956391
w = 1.983、逻辑回归
逻辑回归即用一根曲线近似表示一堆离散点的轨迹,如图:
 图2
图2
import numpy as np
import torch
from torch import optim
from data_util import load_mnist
def build_model(input_dim, output_dim):
return torch.nn.Sequential(
torch.nn.Linear(
input_dim, output_dim, bias=False)
)
def train(model, loss, optimizer, x_val, y_val):
model.train()
optimizer.zero_grad()
fx = model.forward(x_val)
output = loss.forward(fx, y_val)
output.backward()
optimizer.step()
return output.item()
def predict(model, x_val):
model.eval()
output = model.forward(x_val)
return output.data.numpy().argmax(axis=1)
def main():
torch.manual_seed(42)
trX, teX, trY, teY = load_mnist(notallow=False)
trX = torch.from_numpy(trX).float()
teX = torch.from_numpy(teX).float()
trY = torch.tensor(trY)
n_examples, n_features = trX.size()
n_classes = 10
model = build_model(n_features, n_classes)
loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
batch_size = 100
for i in range(100):
cost = 0.
num_batches = n_examples // batch_size
for k in range(num_batches):
start, end = k * batch_size, (k + 1) * batch_size
cost += train(model, loss, optimizer,
trX[start:end], trY[start:end])
predY = predict(model, teX)
print("Epoch %d, cost = %f, acc = %.2f%%"
% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))
if __name__ == "__main__":
main()(1)先从main函数开始,torch.manual_seed(42)上面有介绍,在此略过;
(2)load_mnist是自己实现下载mnist数据集,返回trX和teX是输入数据,trY和teY是标签数据;
(3)build_model内部实现:torch.nn.Sequential(torch.nn.Linear(input_dim, output_dim, bias=False))用于构建一个包含一个线性层的神经网络模型,模型的输入特征数量为input_dim,输出特征数量为output_dim,且该线性层没有偏置项,其中n_classes=10表示输出10个分类;
(4)其他的步骤就是定义损失函数,梯度下降优化器,通过batch_size将训练集拆分,循环100次进行train;
(5)optim.SGD(model.parameters(), lr=0.01, momentum=0.9)实现随机梯度下降(Stochastic Gradient Descent,SGD)优化算法;
(6)每一轮训练完成后,执行predict,该函数接受两个参数model(训练好的模型)和teX(需要预测的数据),步骤如下:
- model.eval()模型设置为评估模式,这意味着模型将不会进行训练,而是仅用于推理;
- 将output转换为NumPy数组,并使用argmax()方法获取每个样本的预测类别;
(7)print("Epoch %d, cost = %f, acc = %.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输出如下(执行很快,但是准确率偏低):
...
Epoch 91, cost = 0.252863, acc = 92.52%
Epoch 92, cost = 0.252717, acc = 92.51%
Epoch 93, cost = 0.252573, acc = 92.50%
Epoch 94, cost = 0.252431, acc = 92.50%
Epoch 95, cost = 0.252291, acc = 92.52%
Epoch 96, cost = 0.252153, acc = 92.52%
Epoch 97, cost = 0.252016, acc = 92.51%
Epoch 98, cost = 0.251882, acc = 92.51%
Epoch 99, cost = 0.251749, acc = 92.51%
Epoch 100, cost = 0.251617, acc = 92.51%4、神经网络
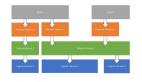
一个经典的LeNet网络,用于对字符进行分类,如图:
 图3
图3
- 定义一个多层的神经网络
- 对数据集的预处理并准备作为网络的输入
- 将数据输入到网络
- 计算网络的损失
- 反向传播,计算梯度
import numpy as np
import torch
from torch import optim
from data_util import load_mnist
def build_model(input_dim, output_dim):
return torch.nn.Sequential(
torch.nn.Linear(input_dim, 512, bias=False),
torch.nn.Sigmoid(),
torch.nn.Linear(512, output_dim, bias=False)
)
def train(model, loss, optimizer, x_val, y_val):
model.train()
optimizer.zero_grad()
fx = model.forward(x_val)
output = loss.forward(fx, y_val)
output.backward()
optimizer.step()
return output.item()
def predict(model, x_val):
model.eval()
output = model.forward(x_val)
return output.data.numpy().argmax(axis=1)
def main():
torch.manual_seed(42)
trX, teX, trY, teY = load_mnist(notallow=False)
trX = torch.from_numpy(trX).float()
teX = torch.from_numpy(teX).float()
trY = torch.tensor(trY)
n_examples, n_features = trX.size()
n_classes = 10
model = build_model(n_features, n_classes)
loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
batch_size = 100
for i in range(100):
cost = 0.
num_batches = n_examples // batch_size
for k in range(num_batches):
start, end = k * batch_size, (k + 1) * batch_size
cost += train(model, loss, optimizer,
trX[start:end], trY[start:end])
predY = predict(model, teX)
print("Epoch %d, cost = %f, acc = %.2f%%"
% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))
if __name__ == "__main__":
main()(1)以上这段神经网络的代码与逻辑回归没有太多的差异,区别的地方是build_model,这里是构建一个包含两个线性层和一个Sigmoid激活函数的神经网络模型,该模型包含一个输入特征数量为input_dim,输出特征数量为output_dim的线性层,一个Sigmoid激活函数,以及一个输入特征数量为512,输出特征数量为output_dim的线性层;
(2)print("Epoch %d, cost = %f, acc = %.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输入如下(执行时间比逻辑回归要长,但是准确率要高很多):
...
Epoch 91, cost = 0.054484, acc = 97.58%
Epoch 92, cost = 0.053753, acc = 97.56%
Epoch 93, cost = 0.053036, acc = 97.60%
Epoch 94, cost = 0.052332, acc = 97.61%
Epoch 95, cost = 0.051641, acc = 97.63%
Epoch 96, cost = 0.050964, acc = 97.66%
Epoch 97, cost = 0.050298, acc = 97.66%
Epoch 98, cost = 0.049645, acc = 97.67%
Epoch 99, cost = 0.049003, acc = 97.67%
Epoch 100, cost = 0.048373, acc = 97.68%