













「机器能够思考吗?」
为了解答这个问题,图灵设计了一个能间接提供答案的模仿游戏。该游戏的最初设计涉及到两位见证者(witness)和一位审问者(interrogator)。两位见证者一个是人类,另一个是人工智能;他们的目标是通过一个纯文本的交互接口说服审问者相信他们是人类。这个游戏本质上是开放性的,因为审问者可以提出任何问题,不管是关于浪漫爱情,抑或是数学问题。图灵认为这一性质能够对机器的智能进行广泛的测试。
后来这个游戏被称为图灵测试(Turing Test),但人们也在不断争论这一测试究竟测算的是什么以及哪些系统有能力通过它。
以 GPT-4 为代表的大型语言模型(LLM)简直就像是专为图灵测试而生的!它们能生成流畅自然的文本,并且在许多语言相关的任务上都已达到比肩人类的水平。实际上,已经有不少人在猜测 GPT-4 也许能够通过图灵测试了。
近日,加利福尼亚大学圣迭戈分校的研究者 Cameron Jones 和 Benjamin Bergen 发布了一份研究报告,给出了他们对 GPT-4 等 AI 智能体进行图灵测试的实证研究结果。

论文地址:https://arxiv.org/pdf/2310.20216.pdf
但在介绍这份研究的结果之前,需要说明的是,图灵测试究竟能否作为衡量智能水平的标准一直以来都颇具争议。
但 Jones 和 Bergen 认为图灵测试还是值得研究的,他们给出了两点理由:
一、图灵测试衡量的是AI 系统能否欺骗对话者使之相信它是人类,这项能力本身是值得评估的。因为创造「伪人」可能会对社会产生巨大的影响,包括实现面向客户的工作岗位自动化、更低成本更高效地制造虚假信息、使用非对齐的 AI 模型从事欺诈活动、让人类不再相信人与人之间的真实互动。图灵测试能让人稳健地跟踪模型的这种能力随时间的变化情况。此外,它还能让人理解哪些因素有助于欺骗,比如模型大小和性能、prompt 设计技术、辅助性基础设施(例如访问实时信息的能力)以及审问者的经验和技能。
二、图灵测试能提供一个帮助研究人类和类人智能的框架。图灵测试不仅仅是评估机器;它也会涉及对人类参与者的文化、道德伦理和心理状态的假设。当审问者设计并完善问题时,他们也会隐含地揭示自己的信念 —— 人类有哪些特质以及哪些特质最难模仿。为此,研究者以定性方式分析了参与者设计问题的策略和理由依据,以为这些信念提供一个经验性的描述。
Cameron Jones 和 Benjamin Bergen 在 652 位人类参与者的帮助下检验了 GPT-4 模仿人类的能力,结果发现表现最好的设置能达到 41% 的成功率,还不及随机乱猜,更不及人类水平的 63%,因此可认为 GPT-4 未能通过图灵测试。他们还在测试过程中得到了一些惊人发现和有趣推断,比如诞生于 1966 年的规则式系统 ELIZA 的表现比 GPT-3.5 更好、AI 不犯错或犯错过多都容易暴露自己。
方法
在具体的图灵测试实验中,研究者采用了双玩家设置,即审问者对一位见证者提问,然后说明他认为对方是人类还是 AI。
见证者
研究者创建了 25 个 LLM 见证者,它们使用 OpenAI API 响应用户查询。每个 LLM 见证者都包含一个模型(GPT-3.5 或 GPT-4)、一个温度值(0.2、0.5 或 1.0)和一个 prompt。prompt 描述了交互的上下文以及对于智能体响应方式的指令,如图 2 所示。、

交互界面
研究者将聊天界面设计成了一个聊天软件的样子,如图 1 所示。审问者发送第一条消息,每位用户每次只能发送一条消息。对话整体限时 5 分钟,每条消息最多 300 个字符。

流程
参与者是通过社交媒体在网上招募的。
参与者会先进入一个在线等候室,然后被随机分配与 AI 或另一个人类对话。AI 在响应时有一个等待时间,具体是最近 5 对人类参与者所用的平均等待时间,以防止审问者将等待时间视为一个评估指标。
当随机配对的是两个人类时,则随机分配审问者和见证者角色。见证者得到的指令是说服审问者相信他们是人类。当人类与 AI 匹配时,则人类必定是审问者。
AI 模型的选取使用了「探索 / 利用」策略。对于每个模型,都从以下分布中选取一个样本:

其中 N 是模型数量,α 和 β 分别是模型在游戏过程中的胜负次数并依照审问者对每个判定结果的信心度加权。最后选择得到了最高样本值的模型。
结果
实验共有 652 位参与者参加,总共完成了 1810 场游戏。其中 389 场游戏被移出最终结果,因为这些场之前审问者已经连续三次与 AI 对话了,这种情况说明此时只有一个人类在线。用户反馈表明,这种情况会导致审问者产生一个先验信念 —— 相信见证者不是人类。另外还有 11 场游戏被移除的原因是审问者表示他们私下认识对话的人类见证者。
最终结果基于剩余的 1405 场游戏,其中 260 场有人类见证者参与。
51% 的参与者只玩了一场游戏,91% 的参与者少于 4 场。
游戏平均时长为 187 秒(σ = 95.3),平均消息数为 8(σ = 5.16),平均词数为 320(σ = 210)。
下图展示了一些游戏示例:

成功率
成功率(SR)的定义是审问者认为一个见证者是人类(即见证者成功)的游戏场数的比例。人类见证者的表现最好,成功率为 63%(见图 4)。

表现最好的 GPT-4 prompt(Sierra)的成功率为 41%,也有其它几个表现相近的 GPT-4 prompt(November 为 40%,Papa 为 36%)。但是,从图中也可看出,不同 prompt 的表现差异很大。
GPT-3.5 的成功率只有 5% (Victor) 到 14% (Juliet)。而 1966 年诞生的基于规则的 ELIZA 反倒实现了 27% 的成功率,甚至超过一些 GPT-4 prompt。
不过需要注意的是,由于整体游戏场数较少,某些 prompt 被调用的次数还格外少,比如 Victor (GPT-3.5) 仅被采样了 21 次(见表 1),因此成功率结果并不非常可靠。

审问者的人口学信息
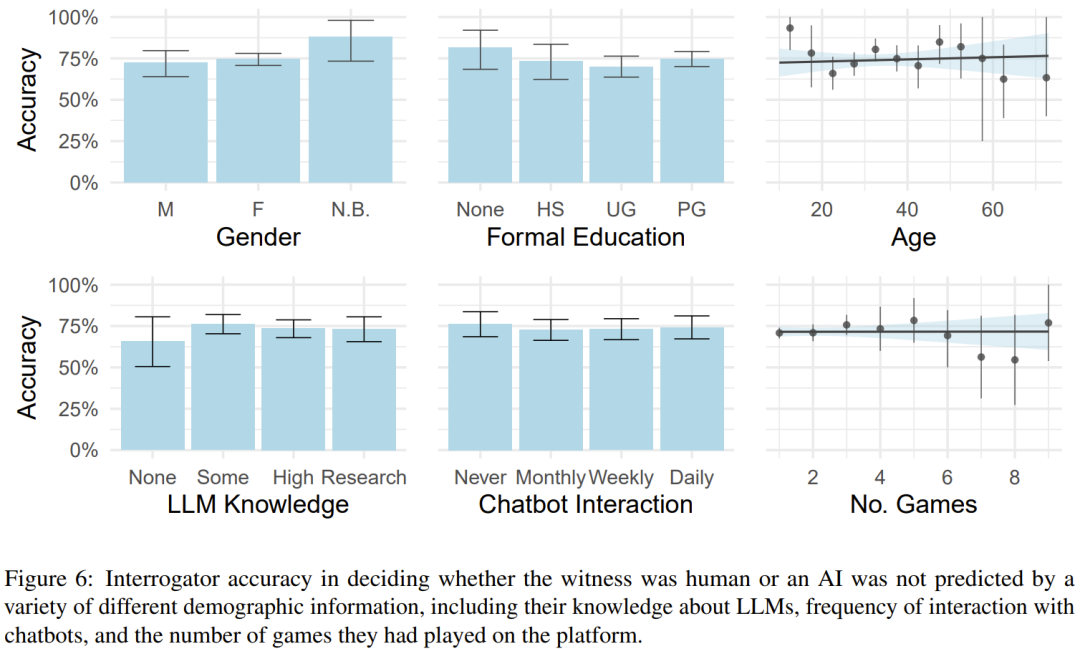
我们知道人口学因素(比如年龄、性别和教育水平)会对人机交互产生影响,而研究者也测试了是否可通过这些因素来预测审问者的辨别能力。
但他们表示并未发现这些因素对准确度有明显影响。这里的准确度是指审问者正确猜出对方是人类或 AI 的比例,见图 6。
策略
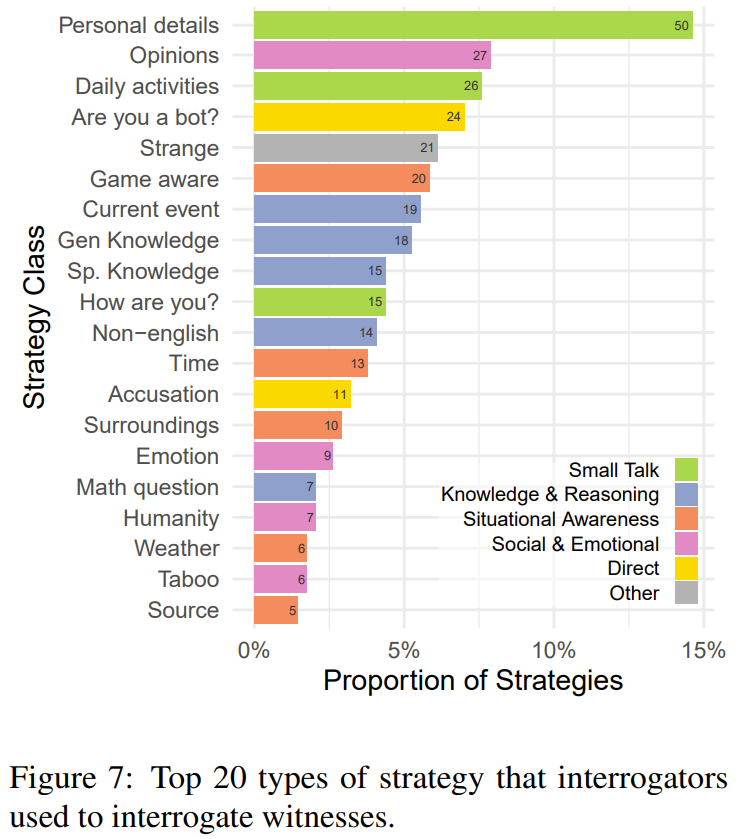
研究者基于 300 场游戏样本,对审问者采用的策略进行了分类。
图 7 给出了被使用最多的 20 种策略。其中最常见的策略是闲聊(27%),也就是问见证者的日常生活和个人细节。
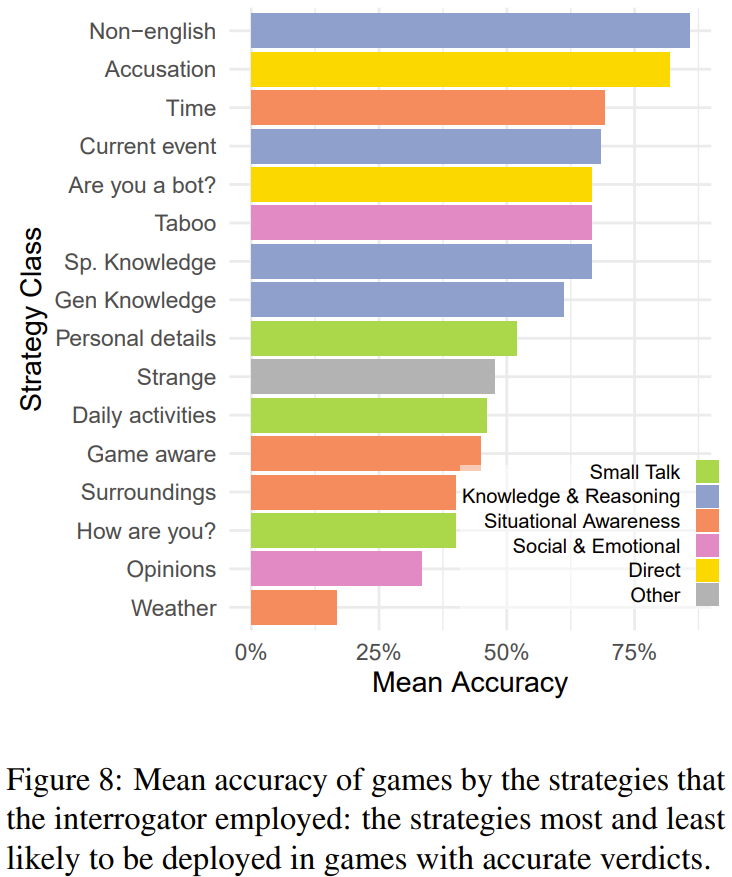
研究者分析了不同策略的有效性,给出了使用不同策略时的平均准确度(见图 8),可以看到,最可能成功的策略是让见证者说外语、询问时间或时事以及直接询问对方是不是 AI 或宣称对方是 AI。
判断的理由或依据
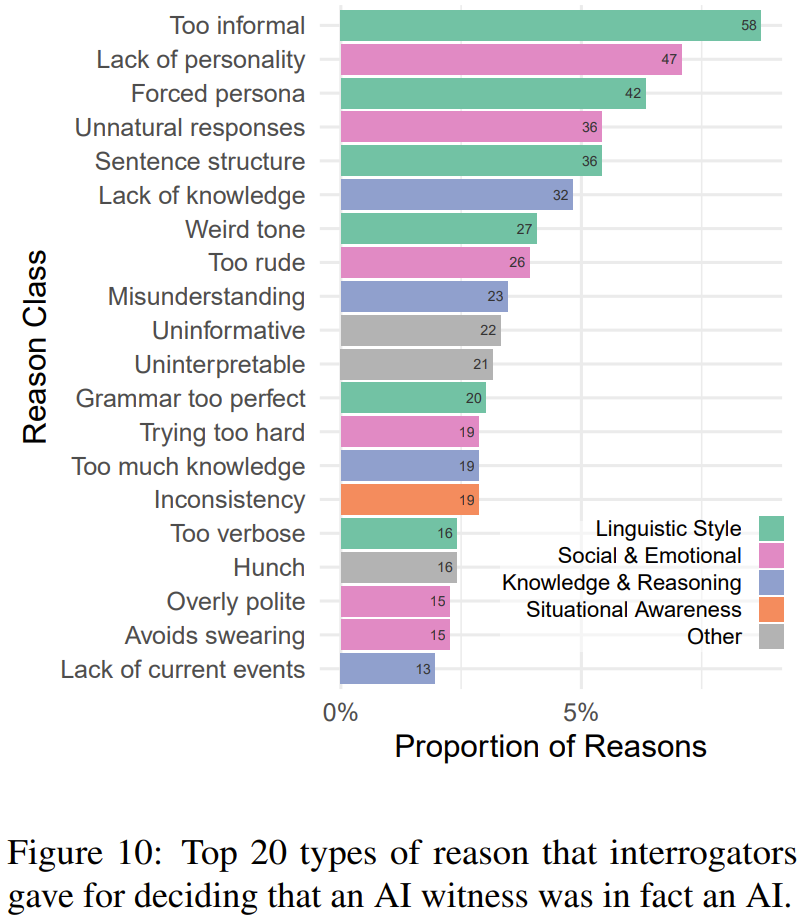
一些参与者提供了判断的理由或依据,研究者将它们分成了 6 大类别:语言风格、社交和情感、知识和内容、情境感知能力、元信息(模型控制范围外的游戏方面)、无信息(模糊或不相关的原因)。图 10 给出了审问者判断时最常采用的 20 个理由。
讨论
GPT-4 通过了图灵测试吗?
这里的结果表明,一些 GPT-4 见证者满足图灵设定的标准,即 30% 的时间骗过审问者,使其判断错误。但是,以 30% 为标准断言成功恐怕并不合适。更常用的基准应该是 50%。这可以表明审问者在一般情况下无法区分 AI 模型和人类。但这一基准也有个缺陷:随机乱猜也能达到 50% 的成功率。
研究者表示,如果要更严格的测试,那么至少应该要求 AI 见证者被认为是人类的频率与人类见证者被认为是人类的频率一样高。也就是说 AI 见证者在图灵测试中的表现应当与人类一样好。但研究者又讨论说这种比较可能对 AI 来说并不公平,因为 AI 必须欺骗审问者,而人类只需说实话即可。
更保守的方案是要求 AI 系统的表现显著超过随机乱猜或人类基准。从理论上讲,这个标准高得没有必要。而从实践角度看,用频率统计来展示图灵测试结果可能是最简单的方法。
这里测试的所有 AI 见证者都没达到 50% 的成功率,更不及人类水平(63%)了。因此,对于这里使用的 prompt,可以判定 GPT-4 没能通过图灵测试。
GPT-4 能通过图灵测试吗?
从图 4 可以看到,不同 prompt 得到的结果的差异很大。
研究者猜想:考虑到实验中探索的 prompt 有限,也许存在某个 prompt 能使 GPT-4 的成功率超过 50% 或人类基准。此外,一些辅助审问者判断见证者是 AI 的理由依据实际上很容易改正和解决,比如给出的信息过于充分、使用重复性的句子结构以及回避禁忌话题。
不过,prompt 工程设计的难度可不小。研究者谈到了自己的经验:在设计这些 prompt 时,为了解决一个问题所做的改变往往会引入新的指示因素,说明该系统不是人类。
其中表现最好的一些能达到 40% 左右的成功率。这一数值与另一项研究报告《Human or Not? A Gamified Approach to the Turing Test》的结果相近,因此可以认为这能代表当前 LLM 的能力。
讯问者人口学信息
令人惊讶的是,这里收集的人口学统计数据(包括与聊天机器人互动的频率、有关 LLM 的知识水平和所玩游戏的场数)对审问者的准确度没有任何显著影响。这说明与 LLM 的交互经验可能无助于区分 LLM 和人类。
对此,研究者给出了可能的解释:他们在设计 prompt 时为了使 LLM 给出的答案接近人类的答案,在冗长性、正式性、是否礼貌、拼写和语法错误方面都有专门设计。要是参与者原本很熟悉 LLM 的典型互动模式,可能会对这些聊天机器人给出的结果感到惊讶,因此之前的经验在这里就用不上了。
另一个可能的解释是选择性偏差。由于参与者是通过社交媒体招募的,因此占大多数的是 20-30 岁、接受过研究生教育且对 LLM 感兴趣的男性。
ELIZA 效应
ELIZA 相对的成功也出乎了研究者的意料,毕竟这个聊天机器人采用的是基于规则的技术,并且诞生于 1966 年。ELIZA 组合使用了模式匹配和替换,可以根据从用户输入中提取的关键内容和模板生成响应。
尽管如此,ELIZA 却在 27% 的游戏中骗过了人类审问者,超过了一些 GPT-4 见证者和所有 GPT-3.5 见证者。
这样的结果可以佐证:图灵测试确实不能精准地衡量智能水平。
策略
审问者采用了大量不同策略来辨别 AI 模型,这展现了图灵测试作为一种交互式评估方法的灵活性。很多参与者采用的策略是闲聊,但 AI 模型其实非常擅长模仿这些典型类型的人类对话,因此闲聊并不是一个很有效的策略。
最有效的策略是使用外语,因为审问者会假定如果回答很专业,那就更可能是来自多语言语言模型。另一个有效的策略是询问当前的时间和发生的事件。尽管 prompt 中包含 UTC 标准的时间戳,但模型往往在转换时区时出错。
许多审问者会直接问对方是不是 AI。虽然 AI 会给出否定答案,但这个策略却相当有效。因为 AI 模型在说服审问者相信它们是人类时往往会「用力过猛」,而人类通常会给出随意即兴的回答。
判断的理由或依据
审问者在做出正确判断时所给出的理由中往往有语言风格一项。因为尽管 LLM 的训练语料中包含大量不同风格的文本,但生成与语境风格一致的内容还依然是一大难题。审问者会发现 AI 模型生成的结果要么过于正式,要么就过于不正式;语法要么太好,要么就糟糕得不真实;要么过于冗长,要么就过于简练。
这可能表明:1)在这种相当不寻常的语境中,适当的风格其实很微妙;2)不同的审问者对风格有不同的预期:没有一种风格能够说服每个审问者。
第二个最常见的原因类别是社交和情感。LLM 学习的是生成完备的响应,并且经过微调以避免生成自相矛盾的结果。这些过程可能会鼓励模型生成一般化的典型响应,但也因此缺乏个性,这也算是一种生态谬误(ecological fallacy)。
值得注意的是,很少有原因与见证者的知识或推理能力有关,这进一步证明经典意义上的智能不足以通过图灵测试。判断理由的分布还说明现在的 LLM 模型已经足够智能了,因此社会 - 感情和语言风格才成为了审问者更看重的因素。当然也可能是因为这些线索一般来说可能更明显,因此对于尚未掌握这些能力的模型,可以将这些线索用作判断理由。
结论
人们普遍认为图灵测试并非是一种完美的衡量智能的方法:要么太容易,要么太困难。Cameron Jones 和 Benjamin Bergen 在这个实证研究中找到了分别支持这两种观点的证据。
最终,他们认为 GPT-4 没能通过图灵测试。
尽管如此,41% 的成功率也表明使用 AI 模型来进行欺诈已经有可能实现,尤其是当人类对话者没有提防对方可能并非人类时。
如果 AI 模型能够稳健地假装成人类,可能会造成广泛的社会和经济后果。随着 AI 模型能力日益增强,识别导致欺骗成功的因素并找到应对策略也会变得越来越重要。






























