让我们从一个场景开始,以建立对我们讨论主题的基本理解。现在大多数人都熟悉的是“忠诚度或奖励计划”。
顾客使用他们的信用卡/借记卡进行金融交易,购买杂货、T恤、书籍...或者订购度假时的航班和酒店房间...使用专用支付方式进行任何购买。
公司然后根据消费金额向顾客提供积分、里程、返现或福利。顾客可以使用这些积分/里程/返现/奖励来获得折扣、免费产品或会员特权。企业这样做是为了激励再次购买,并建立与顾客的信任。
图像来源:tibco.com
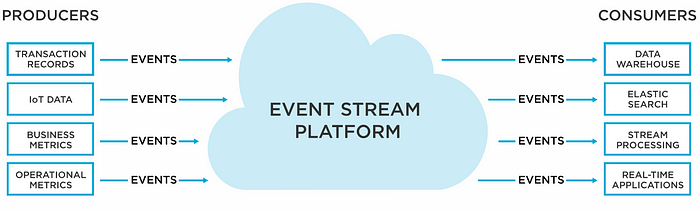
什么是事件流处理 (ESP)? 那么,这是如何发生的?我的信用卡公司是如何将我花的每一美元与适当的费用类别匹配,然后向我授予我可以用来预订酒店房间或机票的里程数的?这就是“事件流处理 (ESP)”发挥作用的地方。ESP是一种能够处理持续数据流(事件流)的技术,一旦事件或变化发生,就能立即处理。通过处理单个数据点而不是整个批次,事件流处理平台提供了一种架构,使软件能够理解、对事件作出反应,并在事件发生时运行。
ESP 平台
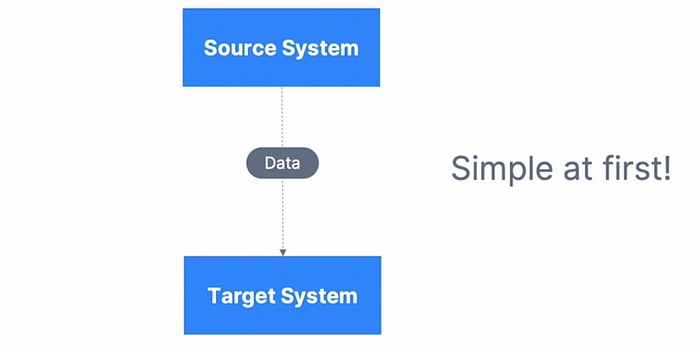
让我们从数据集成的角度来考虑这个过程,我们有一个从“源系统”开始的事件,其中包含有关新交易的数据,然后连接到“目标系统”,在那里事件变化被加载、分析和转换成期望的结果。只需几行代码的简单软件可以执行此操作:
图像来源:Learn Apache Kafka for Beginners
随着源系统和/或目标系统的数量增加,数据集成挑战也增加了。
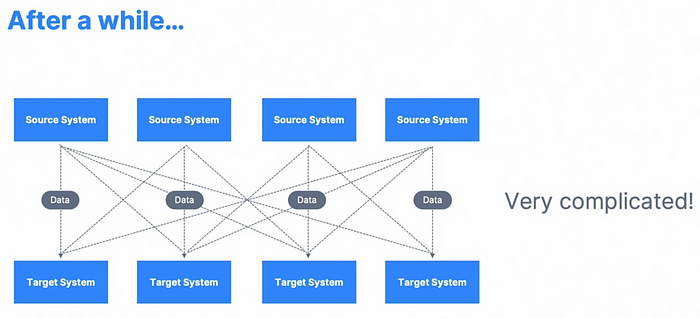
图像来源:Learn Apache Kafka for Beginners
因此,正如您所看到的,集成变得并不容易。源系统和/或目标系统的数量越多,就需要建立越多的集成,使架构变得非常复杂。此外,每个源系统可能会因来自目标系统的请求和连接数量增加而负担过重。每个集成还会涉及协议、数据格式、数据模式和演变方面的困难。
这就是事件流处理平台的用武之地。正如我们上面讨论的,ESP平台提供了一种使软件能够理解、对事件作出反应并在事件发生时运行的架构。
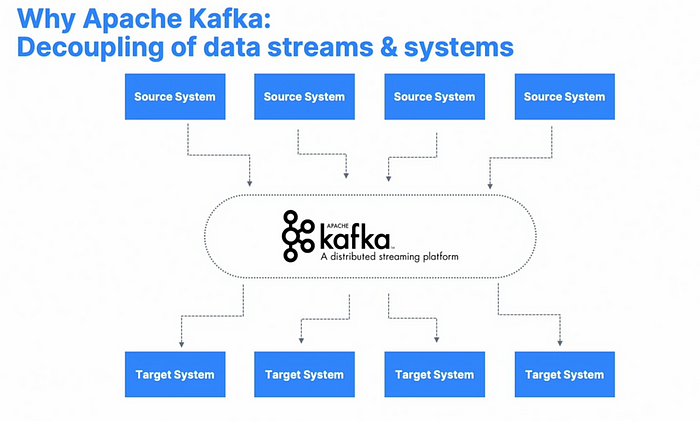

什么是 Apache Kafka? — Kafka 是一种流行的事件流处理平台。 与许多 ESP 平台一样,Kafka通过在源系统和目标系统之间引入解耦来解决数据集成挑战:
Apache Kafka将收集、分类和存储来自源系统(例如网站、定价数据、金融交易、用户互动等)的所有数据。这些源系统被称为“生产者”,它们生成 Kafka 数据流。当目标系统需要接收数据时,它们只需从 Kafka 数据中提取数据。因此,目标系统被称为“消费者”。Kafka现在位于生成者接收数据和向消费者发送数据之间。
它是如何工作的?
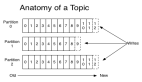
Kafka的工作方式与消息队列(例如 RabbitMQ)非常相似,但具有一些增强功能。Kafka有生产者和消费者的概念,正如前面讨论过的。生产者将消息推送到Kafka,而接收者获取它们。许多消息可能通过Kafka传递,因此为了区分它们并允许您隔离不同的处理上下文,Kafka将消息分组到“主题”中。
每个试图发布某些内容的生产者都必须提供“主题名称”。另一方面,消费者订阅一组主题(可以同时有许多主题),然后从这些主题中获取消息。
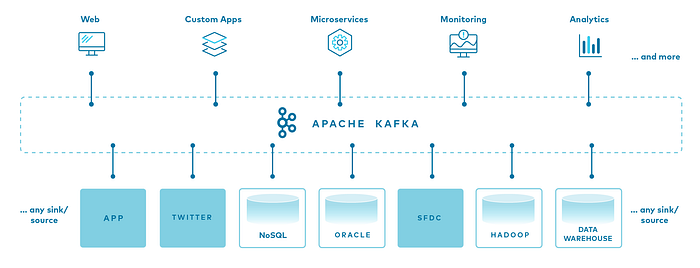
图片来源:hevodata.com
总结一下,这些是关于Kafka的关键重要信息:
- 生产者将消息发布到队列,消费者获取它们进行处理。
- 消费者和生产者在一组被称为主题的消息上工作。这使您能够隔离不同类型的消息。
- 消费者分组成消费者组,允许您将工作负载分布到处于同一组的不同消费者实例中。
- 消费者是Java应用程序,可以扩展以提供更多(或更少)的处理能力。
- 每个主题分为分区 —— 单独的消息块,具有一个分区内的顺序保证。可以根据需要配置分区的数量。
- 每条消息由主题名称、分区号和偏移量唯一标识。
- 偏移量是从主题和分区存在的开始位置的消息编号。
- 提交的偏移量是存储在Kafka中的偏移量,用于在消费者崩溃或重新启动后恢复处理。可以将其视为检查点。
- 消费者位置是消费者内部使用的偏移量,用于跟踪下一次轮询时要获取的消息。
为什么使用 Apache Kafka?
Kafka是一个开源项目。它具有分布式、弹性的架构,并且容忍故障(您可以对其进行修补和维护,而无需关闭整个系统)。Kafka具有横向扩展性。该项目旨在提供一个统一的、高吞吐量、低延迟(低于10毫秒)的平台,用于处理实时数据流。
Kafka被许多组织(如Netflix、Uber、LinkedIn等)和IT团队用作消息系统、活动跟踪系统、流处理、微服务发布/订阅、应用程序日志收集、度量数据收集、解耦系统依赖关系以及与其他大数据技术集成。
- Netflix使用Kafka实时应用建议,当用户在他们的应用上观看电视节目时。
- Uber使用Kafka实时收集用户和行程数据,以计算和预测需求以及价格涨跌情况。这就是为什么您的Uber应用中相同行程的价格随时都会发生变化。
Kafka是一个非常酷的平台。我们可以使用Docker轻松在您的笔记本电脑上设置单节点Kafka集群。