译者 | 李睿
审校 | 重楼
Apache Kafka通常简称为Kafka,是由Apache软件基金会维护的一个开源事件流平台。Apache Kafka最初是在LinkedIn构思的,由Jay Kreps、Neha Narkhede和Jun Rao合作创建,并于2011年作为开源项目发布。
如今,Kafka已成为最流行的事件流平台之一,用于处理实时数据源。它被广泛用于构建可扩展、容错和高性能的流式数据管道。
Kafka的用途在不断扩大,主要的五个案例由Brij Pandey在随附的图片中很好地说明了这一点。
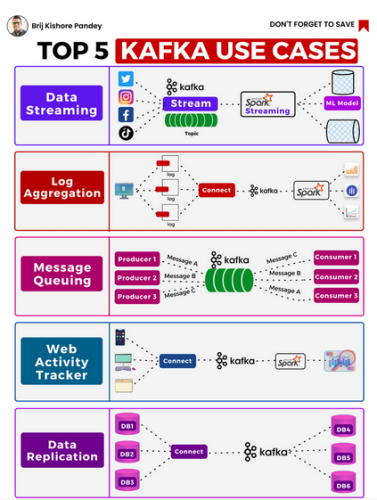
作为一个简单的入门,了解Kafka平台的组件及其工作方式非常重要。
Kafka是一个分布式事件流平台,旨在有效地处理实时数据馈送。它基于发布-订阅消息模型进行操作,并遵循分布式和容错架构。它维护一个持久、有序和分区的记录序列,称为“主题”。生产者编写有关这些主题的数据,消费者从中读取数据。这样可以实现数据生产者和消费者之间的解耦,并允许多个应用程序独立地使用相同的数据流。
Kafka的关键组件包括:
- 主题和分区:Kafka将数据组织到主题中。每个主题都是一个记录流,一个主题中的数据被分成多个分区。每个分区都是一个有序的、不可变的记录序列。通过允许数据分布在多个Kafka代理上,分区实现了水平可扩展性和并行性。
- 生产者:生产者是向Kafka主题写入数据的应用程序。它们将记录发布到特定的主题,然后将记录存储在主题的分区中。生产者可以显式地将记录发送到特定的分区,或者允许Kafka使用分区策略来确定分区。
- 消费者:消费者是从Kafka主题中读取数据的应用程序。它们订阅一个或多个主题,并使用分配给它们的分区中的记录。消费者组用于扩展消费,主题中的每个分区只能由组中的一个消费者使用。这允许多个消费者并行地处理来自同一主题的不同分区的数据。
- 代理:Kafka作为一个服务器集群运行,每个服务器称为一个代理。代理负责处理来自生产者和消费者的读写请求,以及管理主题分区。Kafka集群可以有多个代理来分配负载并确保容错性。
- 分区/复制:为了实现容错性和数据持久性,Kafka允许为主题分区配置复制。每个分区可以有多个副本,其中一个副本指定为领导者,其他副本指定为跟随者。领导者副本处理该分区的所有读写请求,而跟随者副本从领导者副本复制数据以保持同步。如果领导者副本的代理发生故障,其中一个跟随者副本将自动成为新的领导者副本,以确保持续运行。
- 偏移量管理:Kafka维护每个分区的偏移量概念。偏移量表示分区内记录的唯一标识符。消费者跟踪他们当前的偏移量,允许他们在失败或重新处理的情况下从他们离开的地方恢复消费。
- ZooKeeper:虽然不是Kafka本身的一部分,但ZooKeeper经常用于管理元数据和协调Kafka集群中的代理。它有助于领导者的选举、主题和分区信息,以及管理消费者群体的协调。[注:Zookeeper元数据管理工具将很快被Kafka Raft(Kraft是一种内部管理元数据的协议)所取代]
总的来说,Kafka的设计和架构使它成为一个高度可扩展、容错和高效的平台,可以处理大量的实时数据流。它已经成为许多数据驱动的应用程序和数据基础设施中的核心组件,促进了数据集成、事件处理和流分析。
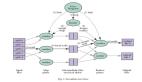
一个典型的Kafka架构如下图所示:
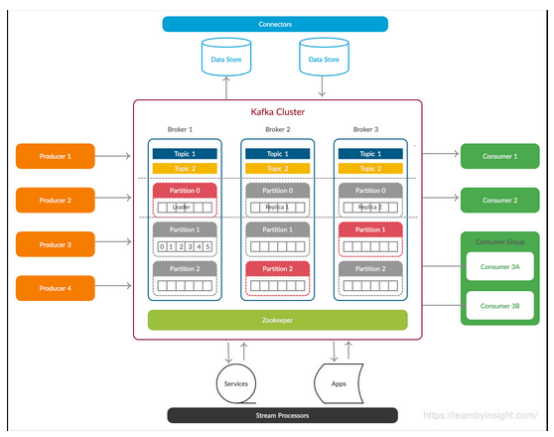
Kafka集群是指将多个Kafka代理作为一个组一起运行以形成Kafka集群的实践。集群是Kafka架构的一个基本方面,它提供了一些好处,包括可扩展性、容错和高可用性。Kafka集群用于处理大规模数据流,并确保系统即使面对故障也能保持运行。
在集群中,Kafka主题被划分为多个分区,以实现可扩展性和并行性。每个分区都是一个线性有序的、不可变的记录序列。因此,分区允许数据跨集群中的多个代理分发。
需要注意的是,一个最小的Kafka集群由三个Kafka代理组成,每个代理都可以运行在单独的服务器上(虚拟或物理)。三节点指导是为了避免在代理失败的情况下出现脑裂(Split-Brain)的情况。
Kafka和Kubernetes
随着越来越多的企业采用Kafka,在Kubernetes上部署Kafka的兴趣也越来越大。
事实上,Dynatrace最近发布的《2023年Kubernetes In the Wild报告》表明,40%以上的大型组织在Kubernetes中运行他们的开源消息传递平台,其中大部分是Kafka。
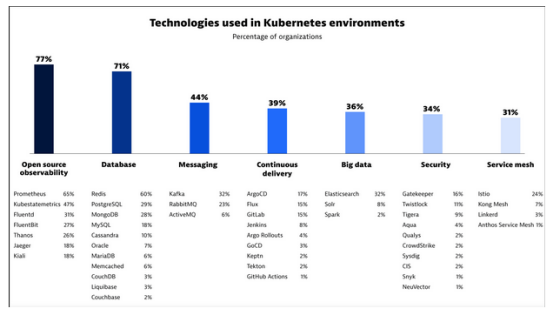
该报告还大胆宣称,“Kubernetes正在成为云计算的‘操作系统’”。
因此,Kafka管理员必须了解Kafka和Kubernetes之间的相互作用,以及如何适当地实现这些相互作用。
多集群Kafka的案例
在单个Kubernetes集群设置中运行Kafka集群相当简单,并且在理论上可以根据需要实现可扩展性。然而在生产中,其画面可能会变得有点模糊。
应该在Kafka和Kubernetes之间区分集群这个术语的使用。Kubernetes部署还使用术语集群来指定一组连接的节点,称为Kubernetes集群。当Kafka工作负载部署在Kubernetes上时,最终会得到一个在Kubernetes集群中运行的Kafka集群,但与这一讨论更相关的是,也可能有一个跨越多个Kubernetes集群的Kafka集群,以实现弹性、性能、数据主权等。
首先,Kafka并不是为多租户设置而设计的。在技术方面,Kafka不理解Kubernetes名称空间或资源隔离等概念。在特定主题中,没有简单的机制来强制多个用户组之间的安全访问限制。
此外,不同的工作负载可能具有不同的更新频率和规模需求,例如,批处理应用程序与实时应用程序。将两个工作负载组合到一个集群中可能会产生不利影响,或者消耗的资源远远超过所需的资源。
数据主权和合规性也会对在特定区域或应用程序中共同定位数据和主题施加限制。
当然,弹性是多个Kafka集群背后的另一个强大驱动力。虽然Kafka集群是为主题容错而设计的,但仍然需要为整个集群的灾难性故障做好准备。在这种情况下,对完全复制集群的需求支持适当的业务连续性规划。
对于正在将工作负载迁移到云端或有混合云策略的企业,可能希望设置多个Kafka集群,并随着时间的推移执行有计划的工作负载迁移,而不是冒险的全面Kafka迁移。
在实践中,很多企业发现自己不得不创建多个Kafka集群,但这些集群需要彼此交互,这只是其中的几个原因。
多集群Kafka
为了使多个Kafka集群相互连接,必须将一个集群中的关键项复制到另一个集群。其中包括主题、偏移量和元数据。在Kafka术语中,这种复制被认为是镜像。
有两种方法可以实现多集群设置:拉伸集群或连接集群。
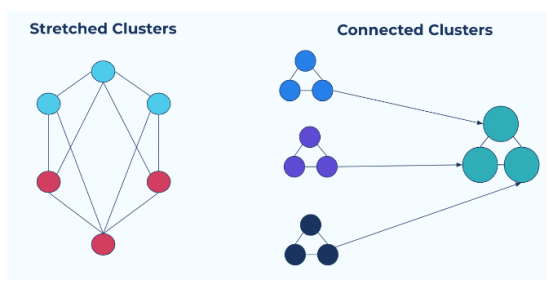
扩展集群:同步复制
拉伸集群是跨多个物理集群“拉伸”的逻辑集群。主题和副本分布在物理集群中,但由于它们被表示为逻辑集群,因此应用程序本身并不知道这种多样性。
拉伸集群具有很强的一致性,并且更易于管理。由于应用程序不知道多个集群的存在,因此与连接集群相比,它们更容易部署在拉伸集群上。
拉伸集群的缺点是它需要集群之间的同步连接。它们对于混合云部署来说并不理想,并且需要至少三个集群的Quorum 机制来避免“脑裂”的情况。
连接集群:异步复制
连接集群通过连接多个独立的集群进行部署。这些独立的集群可以运行在不同的区域或云平台上,并进行单独管理。
连接集群模型的主要优点是,在集群发生故障的情况下不会有停机时间,因为其他集群是独立运行的。每个集群还可以针对其特定资源进行优化。
连接集群的主要缺点是它依赖于集群之间的异步连接。在集群之间复制的主题不是“写时复制”,而是取决于最终的一致性。这可能导致在异步镜像过程中丢失数据。
此外,必须修改跨连接集群工作的应用程序,以识别多个集群。
在解决这个难题之前,简要介绍一下市场上支持Kafka集群连接的常用工具。
开源Kafka自带镜像工具Mirror Maker。
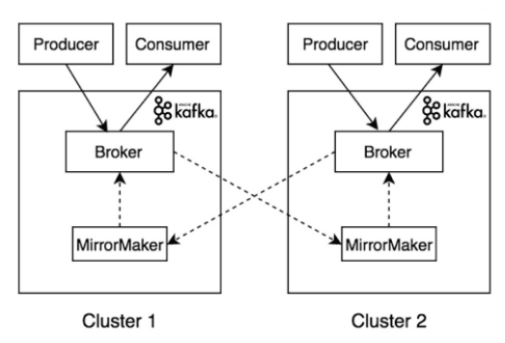
Mirror Maker通过内置生成器在不同的集群之间复制主题。通过这种方式,数据在集群之间进行交叉复制,最终保持一致性,但不会中断单个进程。
值得注意的是,虽然Mirror Maker的概念很简单,但对于IT组织来说,大规模地设置Mirror Maker可能是一个相当大的挑战。必须正确管理IP地址、命名约定、副本数量等,否则可能会导致所谓的“无限复制”,即主题被无限复制,导致最终崩溃。
Mirror Maker的另一个缺点是缺乏允许/不允许更新列表的动态配置。Mirror Maker也不能正确同步主题属性,这使得它在添加或删除要复制的主题时成为大规模操作的难题。Mirror Maker试图解决其中的一些挑战,但许多IT商店仍然难以正确设置Mirror Maker。
其他用于Kafka复制的开源工具包括来自Salesforce的Mirus,来自Uber的uReplicator,以及来自Netflix的定制Flink。
对于商业许可选项,Confluent提供了两个选项:Confluent Replicator和Cluster Linking。Confluent Replicator本质上是一个Kafka Connect连接器,它提供了一种高性能和弹性的方式在集群之间复制主题数据。Cluster Linking是另一种内部开发的产品,其目标是在保留主题偏移的同时进行多区域复制。
即便如此,Cluster Linking还是一种异步复制工具,数据必须跨越网络边界并穿越公共流量路径。
现在应该很清楚,Kafka复制是大规模生产应用程序的关键策略。问题是选择哪一个选项。
富有想象力的Kafka管理员很快就会意识到,根据应用程序的性能和弹性需求,可能需要连接集群和拉伸集群,或者这些部署的组合。
然而,令人生畏的是,设置集群配置和跨多个集群大规模管理这些配置是指数级的挑战。还有什么更优雅的方式来解决这个难题呢?
答案是肯定的!
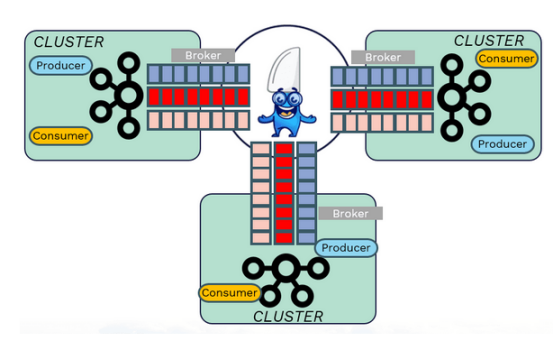
Avesha的KubeSlice是一种两全其美的简单方法。通过在集群或命名空间之间创建直接的服务连接,KubeSlice无需手动配置Kafka集群之间的单个连接。
KubeSlice的核心是在集群之间创建一个安全的、同步的第三层网络网关,在应用程序或名称空间级别进行隔离。一旦设置好了,Kafka管理员就可以自由地在任何集群中部署Kafka代理。
每个代理都与通过片连接的其他每个代理具有同步连接,即使代理本身可能位于不同的集群上。这有效地在代理之间创建了一个拉伸集群,并提供了强一致性和低管理开销的好处。
结语
对于那些可能想将Mirror Maker部署到集群中的人来说,这可以用最少的精力完成,因为集群之间的连接被委托给KubeSlice。因此,Kafka应用程序可以在同一部署中获得同步(速度、弹性)和异步(独立性、规模)复制的好处,并能够根据需要混合和匹配这些功能。这适用于预处理数据中心、公共云或混合设置中的任何组合。
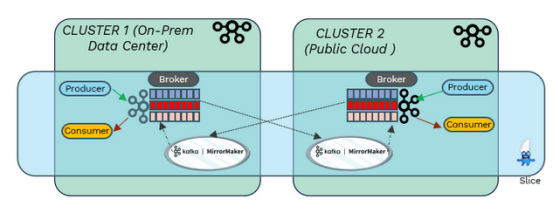
KubeSlice是一个无中断的部署,这意味着不需要卸载任何已经部署的工具。这只是建立一个切片并将Kafka部署添加到该切片上的问题。
本文提供了Apache Kafka的简要概述,并触及了一些更常见的用例。还介绍了当前可用于跨多个集群扩展Kafka部署的工具,并讨论了每种工具的优缺点。最后,本文还介绍了Kubeslice,这是一种新兴的服务连接解决方案,它简化了Kafka多集群部署,并消除了大规模跨多个集群配置Kafka复制带来的麻烦。
原文标题:Kafka Multi-Cluster Deployment on Kubernetes: Simplified!,作者:Ray Edwards