上一篇文章讲了《性能优化(CPU和内存)》,这一节我们主要是聊聊网络优化。
第一部分:网络性能度量
1、设备度量
设备主要是指块设备,由于我们在开发过程中,需要磁盘操作,比如写日志等,所以对于块设备的I/O对于我们需要度量性能的一个重要指标。
(1)I/O等待
CPU等待I/O操作发生的时间,较高和持续的值很多时候表明IO有瓶颈,一般通过iostat -x命令查看:
其中avgqu-sz,avgrq-sz,await,iowait,svctm等这些都需要关注,其含义如下:
- avgqu-sz是平均每次IO操作的数据量(扇区数为单位)
- avgrq-sz是平均等待处理的IO请求队列长度
- await是平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)
- svctm平均每次IO请求的处理时间(毫秒为单位)
- iowait等待磁盘io所消耗的cpu比例
(2)平均队列长度
未完成的I/O请求数量,一般情况下,小于3个是合理的,如果超过表示I/O存储瓶颈,具体可以通过上面的iostat -x命令查看。
(3)平均等待时间
服务I/O请求所测量的平均时间,等待时间不能过长,如果平均等待过长,说明I/O繁忙,具体可以通过上面的iostat -x命令查看。
(4)每秒传输
描述每秒读写的性能,块设备的读写性能随着型号或者调度算法的不同存在比较大的差异,比如使用iostat -x可以看到rkB/s,wkB/s,rrqm/s,r/s和w/s,对于I/0满载的情况下,这些值越大越好。
- rrqm/s是每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并
- wrqm/s是每秒对该设备的写请求被合并次数
- r/s是每秒完成的读次数
- w/s是每秒完成的写次数
- rkB/s是每秒读数据量(kB为单位)
- wkB/s是每秒写数据量(kB为单位)
2、网络度量
高性能编程一般都离不开网络收发,对于RPC Server的开发,我们希望的收发和处理越快越好,那具体指标有哪些?
(1)接收和发送的数据包和字节
网络接口性能可以按照数据包或者字节大小来决定, TODO:
(2)丢包
丢包是指被内核丢弃的数据包,丢弃的原因如下:
- 连接队列满了
- 收发缓冲区满了
- TCP底层重传次数超过设置
- 开启了sync cookie等配置,阻止了一些攻击包
- 防火墙设置等
查看丢包是否增长可以通过netstat -s|grep drop命令查看:
(3)连接队列
这里连接队列是指TCP的三次握手连接队列(SYN半连接队列和ACCEPT连接队列),网络接收队列和网路发送队列。
我们通过netstat -s | grep "SYNs to LISTEN"查看:
或者通过ss -lt查看:
- Recv-Q:表示收到的数据在接收队列中,但是还有多少没有被进程取走(非LISTEN的句柄),如果接收队列一直处于阻塞状态(这个值很高),可能缓存区太小了或者发包太快;
- Send-Q:表示发送的数据在发送队列中未确认的字节数(非LISTEN的句柄),如果发送队列Send-Q不能很快的清零,可能是有应用向外发送数据包过快,或者是对方接收数据包不够快;
(4)其他异常
除了上述度量还有其他一些异常度量,比如大量reset包,大量重传包错误,或者能发包,但是不能收包等,网络相关的度量和排查其实相对复杂,如果大家有兴趣可以读读《Wireshark网络分析就这么简单》,可以通过自己抓包具体分析。
第二部分:网络层优化
1、零拷贝
在《Linux高性能网络编程十谈|系统调用》一文中,当时介绍了网络收发包需要经过多次系统调用和内存拷贝:
 sendfile
sendfile
为了高性能,Linux底层提供了一些零拷贝的系统调用如sendfile,以减少用户态和内核态的切换,原理是什么呢?
如果内核在读取文件后,直接把PageCache中的内容拷贝到socket缓冲区,待到网卡发送完毕后,再通知进程,这样就只有2次上下文切换,和3次内存拷贝;
如果网卡支持SG-DMA(The Scatter-Gather Direct Memory Access)技术,还可以再去除socket缓冲区的拷贝,这样一共只有2次内存拷贝;
除了上述说的sendfile这种零拷贝可以减少用户态到内核态切换和拷贝(因为网络调用),还有一种DirectIO,这种常用于大文件读写(比如FTP Server或者其他CDN下载服务器),原因是由于大文件拷贝难以命中PageCache,导致额外的内存拷贝,如果用DirectIO就可以直接操作磁盘,开发者自己控制缓存。
2、解决C1000K
在早期的服务器开发,从C10K(服务器同时处理1万个TCP连接),C100K(服务器同时处理10万个TCP连接)到C1000K(服务器同时处理100万TCP连接),其实原理上还是使用前面说的方式:事件驱动,异步IO或者协程等,具体的原理在《IO复用和模式》《协程》这两篇文章已经介绍了,如果有兴趣可以再回顾一下。而这里我们讨论一下可能面临的几个场景如何解决:
遇到计算任务,虽然内存、CPU 的速度很快,然而循环执行也可能耗时达到秒级,所以,如果一定要引入需要密集计算才能完成的请求,为了不阻碍其他事件的处理,要么把这样的请求放在独立的线程中完成,要么把请求的处理过程拆分成多段,确保每段能够快速执行完,同时每段执行完都要均等地处理其他事件,这样通过放慢该请求的处理时间,就保障了其他请求的及时处理,比如像Nginx;
读写文件,充分利用PageCache,小文件通过mmap加载到内存,而大文件拆分多个小文件处理;
所有socket操作全部都改为非阻塞,通过epoll或者kqueue来监听读写事件,并将事件拆分给对应的线程处理;
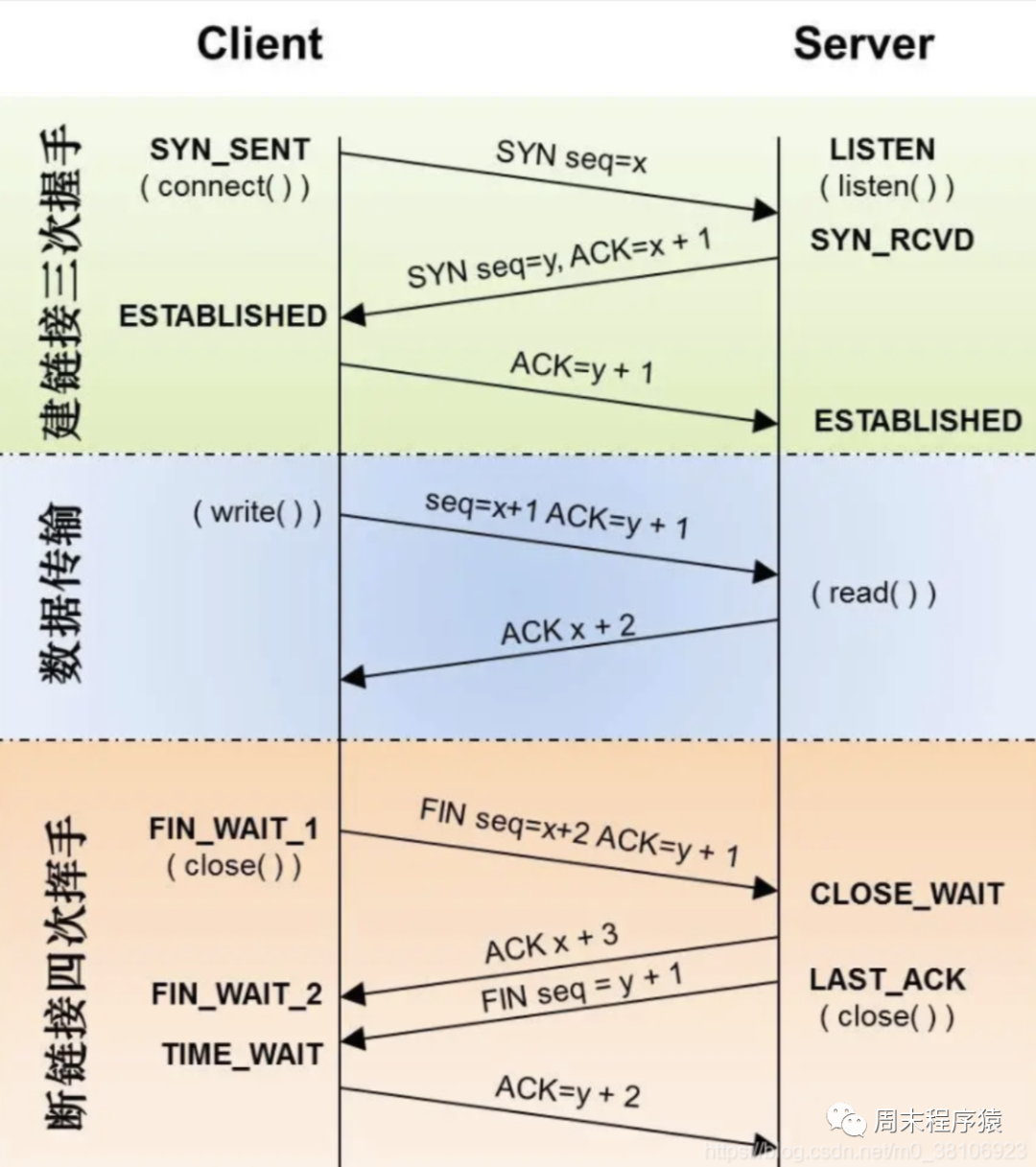
3、提升TCP握手和挥手性能
我们在前面网络篇中已经清楚了讲解了三次握手和四次挥手的流程,但是实际由于TCP的握手协议和挥手协议交互流程过多,会导致一些性能问题,该如何解决?
(1)优化握手参数
正常情况下,握手环节客户端发送SYN开启握手,服务器会在几毫秒内返回ACK,但如果客户端迟迟没有收到ACK会怎么样呢?客户端会重发SYN,重试的次数由tcp_syn_retries参数控制,默认是6次:
同时每次传输时间是按照倍数递增(1,2,4,8,32,64 ... 秒),所以在网络繁忙情况下或者在业务明确不能太多超时情况下,调整这个时间到net.ipv4.tcp_syn_retries = 3,这样能减少服务端在网络繁忙情况下的连锁反应。
上述是客户端侧调整,而服务端可能会出现半连接队列满了的场景,控制半连接队列是net.ipv4.tcp_max_syn_backlog = 1024内核参数,可以适当的调大取值;同样服务端在从半连接队列转换到ESTABLISHED,也需要确认客户端回复的确认ACK,如果没有收到也会重发SYN+ACK,所以这里Linux也提供调整的参数net.ipv4.tcp_synack_retries = 5,减少重传次数,降低加剧的风险;
除了以上的调整,减少握手的RTT也是一种优化手段 —— TOF(TCP fast open),TFO到底怎样达成这一目的呢?它把通讯分为两个阶段,第一阶段为首次建立连接,这时走正常的三次握手,但在客户端的SYN报文会明确地告诉服务器它想使用TFO功能,这样服务器会把客户端IP地址用只有自己知道的密钥加密,作为Cookie携带在返回的SYN+ACK报文中,客户端收到后会将Cookie缓存在本地;
第二阶段就是每次TCP底层的报文都会带上Cookie,只要带上了Cookie的请求,服务端不需要收到客户端的确认包,就可以直接传输数据了,这样就减少了RTT;设置参数可以通过net.ipv4.tcp_fastopen = 3;
(2)优化挥手参数
握手优化有一些相应的方法,那挥手阶段是否也可以优化呢?我们应该在开发中经常遇到是TIME_WAIT状态,估计踩过坑的应该不少,TIME_WAIT过多会消耗系统资源,端口耗尽导致想新建连接失败,触发Linux内核查找可用端口导致循环问题等。如何解决?设置tcp_max_tw_buckets参数,当TIME_WAIT的连接数量超过该参数时,新关闭的连接就不再经历TIME_WAIT而直接关闭;或者快速复用端口tcp_tw_reuse,在安全条件下使用TIME_WAIT状态下的端口。
在回顾一下TCP挥手的图,被调方会有CLOSE_WAIT,如果在我们服务中有大量的CLOSE_WAIT时候,我们就得注意:
- 是否在处理完调用方的时候后,忘记关闭连接
- 服务负载太高,导致close调用被延时
- 处理进程处于Pending状态,导致不能及时关闭连接
4、一些网络内核参数
"提升TCP握手和挥手性能"已经提到了一些优化参数,除了这些参数外还有一些对性能有帮助的参数:
- net.ipv4.tcp_syncookies = 1减少SYN泛洪攻击
- net.ipv4.tcp_abort_on_overflow = 1快速回复RST包,减缓accept队列满的情况
- net.ipv4.tcp_orphan_retries = 5如果FIN_WAIT1状态连接有很多,考虑调小该值
- net.ipv4.tcp_fin_timeout = 60调整该值可以减少FIN的确认时间
- net.ipv4.tcp_window_scaling = 1调整滑动窗口的指数
- net.ipv4.tcp_wmem = 4096 16384 4194304调整写缓冲区大小
- net.ipv4.tcp_rmem = 4096 87380 6291456调整读缓冲区大小
- net.ipv4.tcp_congestion_control = cubic调整拥塞控制的算法,可以分析具体网络场景,通过设置拥塞控制算法提升发包的效率
5、DPDK
在C1000K问题中,各种软件、硬件的优化很可能都已经做到头了,无论怎么调试参数,提升性能能力已经有限,根本的问题是,LINUX网络协议栈做了太多太繁重的工作。
于是英特尔公司的网络通信部门2008年提出DPDK,提供丰富、完整的框架,让CPU快速实现数据平面应用的数据包处理,高效完成网络转发等工作,具体细节大家可以查阅资料,这里我整理了DPDK高性能的大概原理:
跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收,在PPS非常高的场景中,查询时间比实际工作时间少了很多,绝大部分时间都在处理网络包,而跳过内核协议栈后,就省去了繁杂的硬中断、软中断再到 Linux 网络协议栈逐层处理的过程,应用程序可以针对应用的实际场景,有针对性地优化网络包的处理逻辑,而不需要关注所有的细节;
通过大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率;
 DPDK网络图
DPDK网络图
第三部分:应用层协议优化
网络编程中除了设计一个好的底层server和调整内核参数外,其实应用层的协议选型和设计也很重要,那本小节讨论一下当前的优化方案。
1、HTTP/1.1
从互联网发展到现在,HTTP/1.1一直是最广泛使用的应用层协议,主要是使用简单,方便,但是缺点也很明显:HTTP头部使用 ASCII编码,信息冗余,协议滥用等,导致对其的优化都集中在业务层。那有哪些优化,我这里总结一些:
1.充分利用缓存
- 客户端缓存:利用Cache-control,Expires,etags等HTTP/1.1特性,减少重复请求的次数;
- CDN缓存:静态资源优先考虑使用CDN服务,本身CDN是边缘节点,同时已经充分考虑HTTP/1.1一些性能加速策略;
- 3XX状态码:返回3XX状态码,让客户端根据状态码使用缓存策略
2.合并请求
- 当多个访问小文件的请求被合并为一个访问大文件的请求时,这样虽然传输的总资源体积未变,但减少请求就意味着减少了重复发送的HTTP头部,同时也减少了TCP连接的数量,因而省去了TCP握手和慢启动过程消耗的时间
- 由于浏览器限制同一个域名下并发请求数(如Chrome是6个),所以我们优先加载客户端急需的数据,其他数据可以懒加载
3.使用压缩算法
- 利用HTTP的Accept-Encoding头部字段,让服务端知道客户端的压缩算法然后返回压缩后的数据给客户端
- 对于图片请求,可以考虑使用webp,svg等格式,这些图片压缩后的数据较小
4.优化HTTPS
- 优先使用TLS1.3,减少RTT次数
- 明确某些静态资源不需要加密,或者可以自己通过预埋加密协议的,改为HTTP请求,减少握手次数
- 使用长连接,缓解每次请求都需要走TLS的握手协议
2、HTTP/2
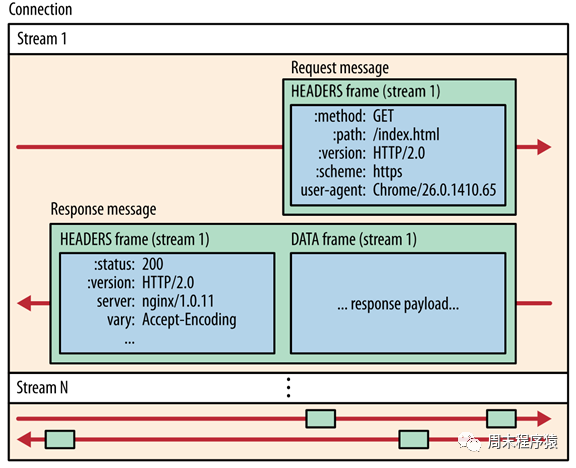
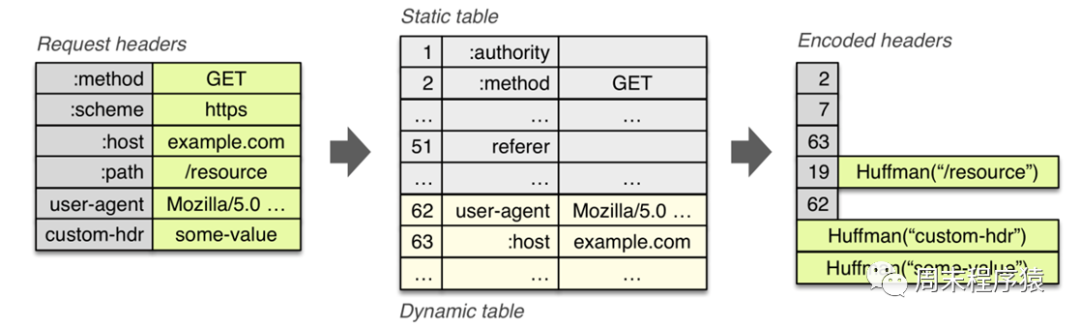
现在使用HTTP/2的服务越来越多了,包括gRPC框架的默认协议就是HTTP/2,对比HTTP/1,HTTP/2性能非常大的提升,可以从上图看出:
- 图1 中HTTP/2使用的流式传输,在一条连接上可以有多个数据帧,这样就不需要再像HTTP/1一个请求需要新建一个连接了;
- 图2 中HTTP/2使用HTTP Header静态和动态编码表的方式,这样每次请求不需要传递重复或者通用的一些Header信息,减少了包体的大小;
HTTP/1.1 不支持服务器主动推送消息,因此当客户端需要获取通知时,只能通过定时器不断地拉取消息,而HTTP/2的消息可以主动推送,可以节省大量带宽和服务器资源;
3、HTTP/3
 HTTP3图3
HTTP3图3
上面介绍的HTTP/2虽然已经提升很多性能,减少了网络请求,但是底层使用TCP,避免不了握手,慢启动和拥塞控制等问题,于是HTTP/3通过使用UDP绕过这些限制来优化性能。
- HTTP/3可以实现0 RTT建立连接,HTTP/2的连接建立需要3 RTT,如果考虑会话复用,即把第一次握手计算出来的对称密钥缓存起来,那也需要2 RTT,更进一步的,如果TLS升级到1.3,那么HTTP/2连接需要2 RTT,考虑会话复用需要1 RTT。而HTTP/3首次连接只需要1 RTT, 后面的链接只需要0 RTT,其原理和cookie类似,维持conntion id,实现连接迁移。
- 解决队头阻塞,在HTTP/2中虽然是TCP多路复用,但是TCP的包确是顺序的,所以如果一个连接上的包在TCP层没有被确认,这个连接上HTTP/2请求都会被卡住,但是HTTP/3基于UDP就可以不存在这个问题,Packet可以发送给服务端,服务端根据需要自己组装包顺序,即使Packet丢了,可以重传当前Packet即可;
上述都是HTTP/3对比HTTP/2改进的地方,但是从目前看全面使用还是有一些局限,比如:防火墙对UDP包限制,连接迁移特性使情况变得更加复杂等问题,有兴趣的可以在客户端尝试,但是估计会要踩比较多的坑。
4、RPC协议
RPC协议包括很多(如HTTP JSON,XML,ProtoBuf等),框架也比较多(gRPC,Thrift,Brpc,Spring Cloud),随着微服务的架构被大家熟知,内网的RPC协议设计往往是网络框架的重要部分。当然RPC框架底层的架构还是前面介绍的异步,多路复用,多线程等设计,但是上层我们要考虑高性能,更多要解决如下问题:
- 根据业务场景设计不同的协议,比如采用ProtoBuf能压缩编码,采用HTTP JSON协议方便支持各个客户端对接;
- 报文的格式设计,好的报文格式能提升编码和解码效率;
- 降低开发成本,考虑注册中心和负载均衡,让框架和RPC紧密结合,减少业务层的开发负担;
- 充分考虑分布式场景,比如事务超时,消息幂等等等问题;
之前在业务中也开发了一些RPC框架,以上便是我对RPC协议的简单总结,不过RPC框架对于性能的考虑可能不是那么重要,更多的是考虑便利性,我们只需要把底层网络框架设计的足够高性能,并且选择与业务匹配的网络协议,这样基本能满足大部分业务需求。