在Linux网络编程中,信号处理和定时器是经常遇到的功能,在聊这块内容之前如果您看过上一篇文章《Linux高性能网络编程十谈|IO复用和模式》,应该比较完整的了解epoll了,但是这里还遗漏了一个知识点,那开始先补上这个坑。
关于epoll惊群问题,什么是惊群呢?
比如我们在写代码过程中,使用两个线程的epoll监听socket,当socket上有事件发生时,两个epoll都会被唤醒,导致会操作同一个socket,这就是惊群,那如何解决呢?
(1)使用EPOLLEXCLUSIVE:EPOLLEXCLUSIVE是epoll的扩展选项,它允许一个线程独占一个epoll实例,从而避免了epoll的惊群问题;
(2)使用EPOLLONESHOT:对于注册了EPOLLONESHOT事件的文件描述符,操作系统最多触发一个可读,可写或者异常事件,且触发一次,这样就能确保一个线程获取事件并处理,但是需要注意的是对于监听类型(如accept)不能使用EPOLLONESHOT,否则就不能持续监听连接,对于处理完了的非监听事件,需要重置EPOLLONESHOT;
第一部分:信号
1、发送信号给进程
#include <sys/types.h>
#include <signal.h>
int kill(pid_t pid, int sig);(1)pid的取值和含义如下:
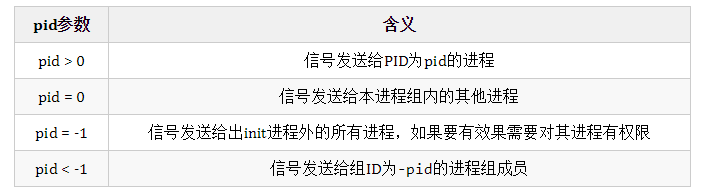
(2)sig的取值和含义如下(在linux命令行使用kill -l查看取值,这里列几个经常使用的):
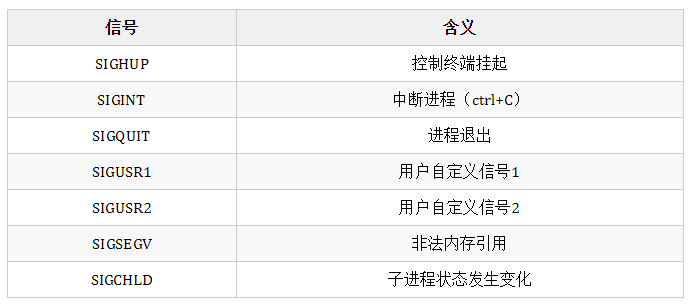
2、信号回调函数
#include <signal.h>
typedef void (&__sighandler_t) (int);
__sighandler_t signal(int sig, __sighandler_t _handler);
int sigaction(int sig, const struct sigaction *act, struct sigaction *oact);(1)__sighandler_t信号处理的函数指针,其中处理参数为触发信号当前值,其中有两个默认宏(SIG_DFL:使用信号默认处理,SIG_IGN:忽略目标信号);
(2)signal注册信号回调处理函数,返回值为一个函数指针,含义是这个信号上一次处理的回调函数或者是系统默认的处理函数,这里目的是让用户可以自己恢复信号处理方式,比如系统对于一些信号是杀掉进程的,这里就应该处理完自己的回调逻辑后再调用系统默认行为;
(3)sigaction函数的功能是检查或修改与指定信号相关联的处理动作,使用样例如下:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <signal.h>
int main()
{
struct sigaction newact, oldact;
newact.sa_handler = SIG_IGN; // 设置信号忽略,也可以设置为处理函数
sigemptyset(&newact.sa_mask);
newact.sa_flags = 0;
int count = 0;
pid_t pid = 0;
sigaction(SIGINT, &newact, &oldact); // 原始的备份到oldact,为后续的处理恢复
pid = fork();
if (pid == 0)
{
while(1)
{
printf("child exec ...\n");
sleep(1);
}
return 0;
}
while (1)
{
if (count++ > 3)
{
sigaction(SIGINT, &oldact, NULL); // 恢复父进程信号处理方式
kill(pid, SIGKILL); // 父进程发信号给子进程
}
printf("father exec ...\n");
sleep(1);
}
return 0;
}第二部分:定时器
在Linux网络编程中,定时器的作用主要是管理定时任务,处理过期连接,检测超时队列等,那我们可以通过哪些方式实现定时器呢?
1、利用系统API
...
setsockopt(socketfd, SOL_SOCKET, SO_SNDTIMEO, &timeout, len);
setsockopt(socketfd, SOL_SOCKET, SO_RCVTIMEO, &timeout, len);
int number = epoll_wait(fd, events, MAX_EVENT_NUMBER, timeout);
...通过使用socket的参数,设置连接句柄的发送和接收数据超时时间,可以实现定时处理:
(1)SO_SNDTIMEO发送数据超时时间,根据timeout设置;
(2)SO_RCVTIMEO接收数据超时时间,根据timeout设置;
IO复用的参数中都带了一个timeout参数,可以设置来达到定时触发分支逻辑,比如epoll_wait;
2、简单的定时器
(1)启动一个线程实现定时器,具体实现如下图:
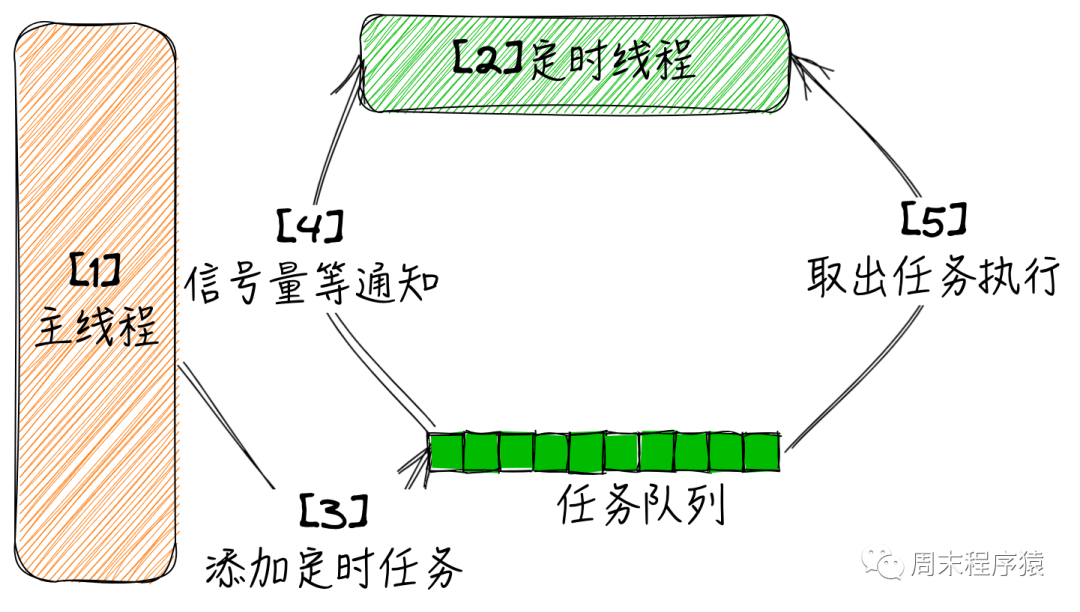
- 主线程启动,开始执行任务,这里可以是网络收发或者其他;
- 启动一个线程,做定时任务处理使用;
- 主线程需要增加定时任务,可以将任务封装为task,添加到任务队列中;
- 同时通知定时线程,队列中有任务了,这里通知机制可以是信号量或者广播方式;
- 定时线程取出队列中任务,判断当前任务是否过期,如果过期就执行,没有过期就继续放入任务队列中,同时这里需要让线程等待队列中距离下一个周期最短的时间,继续取队列任务;
(2)使用epoll_wait设置timeout,是在网络事件触发的定时器中最方便的方式,具体逻辑如下:
...
start_timer = ... // 开始执行时间
while (true) {
int number = epoll_wait(epfd, events, MAX_EVENT_NUMBER, timeout);
for (...) {
...
// 处理连接任务
...
}
end_timer = ... // epoll_wait返回并处理任务时间
// 处理定时任务,判断当前时间是否在一个timeout
if (end_timer - start_timer > timeout) { // 这里是伪代码,具体时间判断可以参考linux结构体
...
// 启动线程执行定时任务逻辑
...
}
}3、时间轮
时间轮是一种高效定时器,通过类似圆盘的形式定义每个tick,定时转动圆盘,假设每次tick时间为si,一个时间轮有N个tick,那么执行转动一圈时间为N*si;
现在插入一个任务,需要to1时间周期后执行,这里就分情况处理:
(1)如果to1 < N*si,则需要分配到(当前时间轮的位置 + to1 / si)的位置上,等待自然tick到达执行当前to1的定时任务;
(2)如果to1 > N*si,则需要分配到(当前时间轮的位置 + (to1 % N) / si + N)的位置上,由于to1执行时间超过一轮的周期,所以需要等待多轮转动后才能执行,那如何处理呢?因此我们将每个轮的tick上挂一个链表,这个链表的节点表示到达这个tick需要执行的任务to1,这里的节点有可能是大于一个轮转动的事件周期,也可能就是当前轮时间周期内执行,我们只需要当事件到达tick时,取出链表遍历链表节点to1,判断是否是当前事件周期内执行,如果是摘除链表节点然后执行任务,如果不是则重新计算to1需要多久后执行,计算方法就和上面的一样(当前时间轮位置 + ((to1 - 链表最小的周期时间) % N) / si + N),然后将当前链表节点重新放回;
 事件轮
事件轮
4、时间堆
堆的数据结构应该大家都比较熟悉了,堆是一种满足以下条件的树:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树;
- 添加堆节点的时间复杂度O(lgn),删除节点是O(lgn),获取节点是O(1);
 时间堆
时间堆
(1)循环线程读取最小时间堆的堆顶元素;
(2)取出最小节点,判断当前事件是否过期,如果过期则继续执行,否则不处理;
(3)将最小节点对应的事件丢给执行线程执行;
这里最小时间堆节点在代码实现中可以用一个数组表示,使用完全二叉树的排列。
#include<iostream>
void heapify(int arr[], int n, int i) {
if (i >= n) return;
int min_node = i;
int lson = i * 2 + 1;
int rson = i * 2 + 2;
if (lson < n && arr[min_node] > arr[lson]) { // 和左孩子比较,找到最小节点
min_node = lson;
}
if (rson < n && arr[min_node] > arr[rson]) { // 和右孩子比较,找到最小节点
min_node = rson;
}
if (min_node != i) {
swap(arr[min_node], arr[i]);
heapify(arr, n, min_node); // 递归处理
}
}
void heapSort(int arr[], int n) {
// 反向取出最后一个节点
int lastNode = n - 1;
int parent = (lastNode - 1) / 2;
for (int i = parent; i >= 0; i--) {
heapify(arr, n, i);
}
for (int i = n - 1; i >= 0; i--) {
swap(arr[i], arr[0]);
heapify(arr, i, 0); // 调整堆节点
}
}
int main() {
int arr[5] = { 70, 41, 10, 90, 18, 26 };
heap_sort(arr, sizeof(arr) / sizeof(arr[0]));
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
cout << arr[i] << endl;
}
return 0;
}