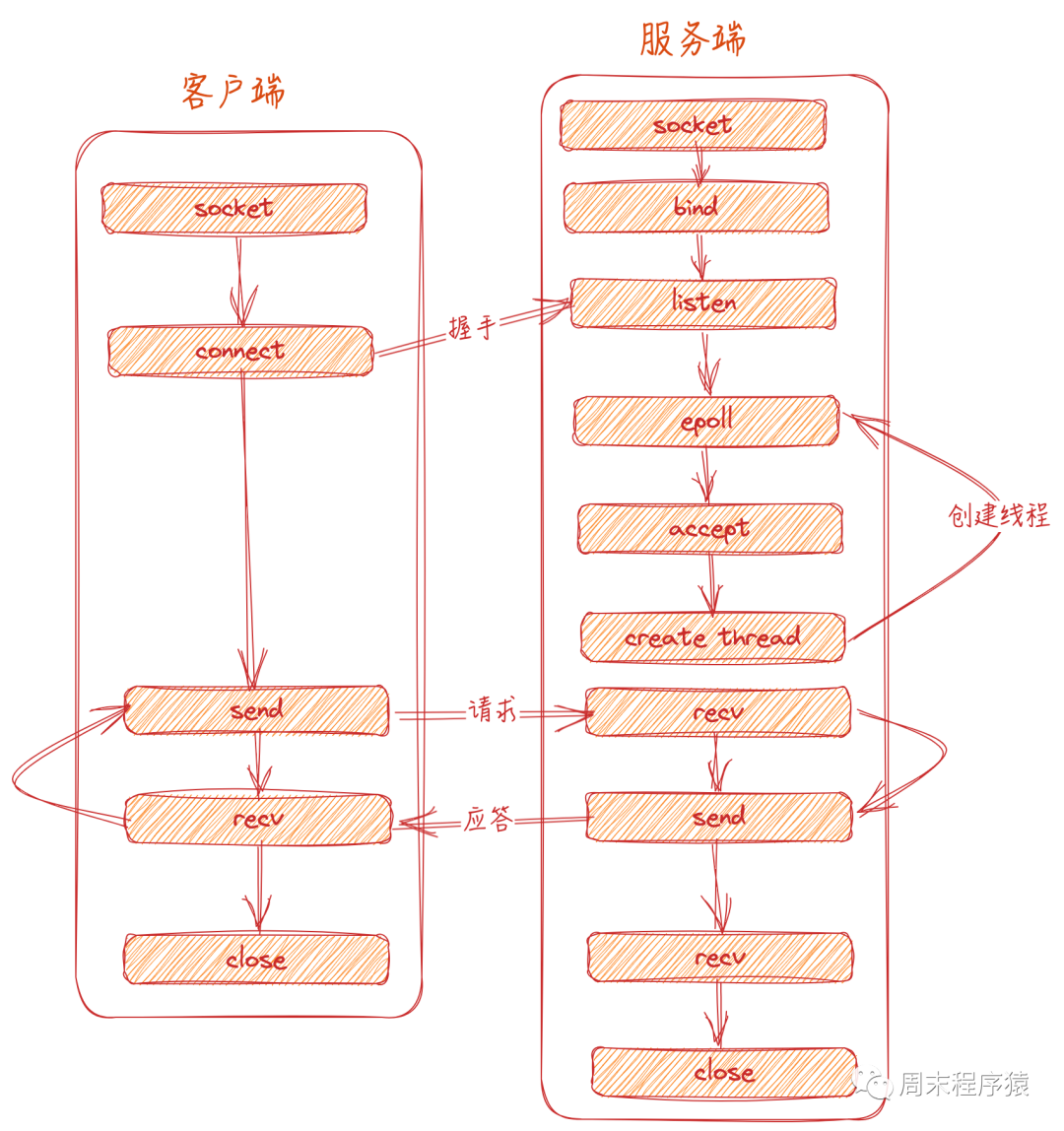
通常我们写一个linux的client和server如下图:
但是怎么提升性能?系统是如何快速处理网络事件?因此本文就来谈谈IO复用和模式。
第一部分:模式
我们都知道socket分为阻塞和非阻塞,阻塞情况就是卡住流程,必须等事件发生;而非阻塞是立即返回,不管事件是否有没有准备好,需要上层代码通过EAGAIN,EWOULDBLOCK和EINPROGRESS等errno返回值来判断,基于非阻塞有两种网络编程模式:Reactor和Proactor事件处理。
1、Reactor
同步IO模型一般使用Reactor,如果使用线程模式,Reactor是遇到事件就通知工作线程处理,然后主线程继续循环等待事件的发生:
 reactor
reactor
(1)对于网络读写,先将socket注册到epoll内核事件表中;
(2)使用epoll_wait等待句柄的读写事件;
(3)当句柄的可读可写事件发生,通知工作线程执行对应的读写动作;
(4)当工作线程处理完读写动作,如果还有后续读写,工作线程可以将句柄继续注册到epoll内核事件表中;
(5)主线程继续用epoll_wait等待事件发生,然后继续告知工作线程处理;
2、Proactor
在讲Proactor之前我们先说说一个例子:
...
#include <libaio.h>
int main() {
io_context_t context;
struct iocb io[1], *p[1] = {&io[0]};
struct io_event e[1];
...
// 1. 打开要进行异步IO的文件
int fd = open("xxx", O_CREAT|O_RDWR|O_DIRECT, 0644);
if (fd < 0) {
printf("open error: %d\n", errno);
return 0;
}
// 2. 创建一个异步IO上下文
if (0 != io_setup(nr_events, &context)) {
printf("io_setup error: %d\n", errno);
return 0;
}
// 3. 创建一个异步IO任务
io_prep_pwrite(&io[0], fd, wbuf, wbuflen, 0);
// 4. 提交异步IO任务
if ((ret = io_submit(context, 1, p)) != 1) {
printf("io_submit error: %d\n", ret);
io_destroy(context);
return -1;
}
while (1) {
// 5. 获取异步IO的结果
ret = io_getevents(context, 1, 1, e, &timeout);
if (ret < 0) {
printf("io_getevents error: %d\n", ret);
break;
}
...
}
...
}以上就是linux的aio处理一个读写文件的流程,可以看到整个流程不需要工作线程处理,而是由内核直接处理后,主线程只需要等待处理结果即可。
 proactor
proactor
3、Half-Reactor
前面提到Reactor大家从图中看出,都是主线程等待事件,分发事件,然后工作线程争抢事件后处理,这里会有几个缺点:
(1)工作线程需要加锁取出自己的工作任务,浪费CPU;
(2)工作线程取出队列一次只能处理一个,对于CPU密集型的任务可以跑满CPU,但是如果是IO密集型任务,这个工作线程又会切换到休眠或者等待其他任务,不能充分利用CPU;
为了解决以上缺点,于是提出了Half-Reactor半反应堆模式:
 Half-Reactor
Half-Reactor
第二部分:IO复用
在开发一些业务面前,我们可能会面对C10K,C100K或者C10M等问题,只是靠堆服务器可能不能完全解决,所以我们就需要从IO复用来处理服务的并发能力,这里我们就直接讲epoll(对于select,poll和epoll的大概区别应该都知道了,所以就不详细说了,如果有疑问可以留言给我),同时找了一张libevent的几个事件处理性能对比:
 libevent
libevent
1、epoll的使用
#include <sys/epoll.h>
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);(1)epoll_create创建一个内核事件表,size可以指定大小,但是并没有作用;
(2)epoll_ctl操作事件,epfd就是epoll事件表,op指定操作类型(EPOLL_CTL_ADD往事件表添加fd,EPOLL_CTL_MOD往事件表修改fd,EPOLL_CTL_DEL往事件表删除fd);
(3)struct epoll_event其结构体:
sturct epoll_event{ _uint32_t events; // EPOLLIN(数据可读),EPOLLOUT(数据可写)... epoll_data_t data; // 用于存储用户监听事件句柄需要在上下文携带的用户数据}
(4)epoll_wait等待事件发生,events返回发生事件的列表,timeout等待一定的超时时间,如果没有事件发生依旧返回,maxevents最多一次监听集合的大小;
2、LT和ET
(1)LT是epoll对文件操作符的模式,表示电平触发(Level Trigger),当epoll_wait监听了事件,上层可以不处理该事件,下一次epoll_wait依旧会触发;
(2)ET是epoll对文件描述符的高效模式,表示边缘触发(Edge Trigger),当epoll_wait监听了事件,如果不处理下一次不会再触发,需要应用层一次就处理完,这样可以减少触发的次数,从而提升性能。
所以要注意对于read使用将套接口设置为非阻塞,再用while循环包住read一直读到产生EAGAIN错误,采用非阻塞套接口的原因在于防止read被阻塞住。
3、样例
详细代码由于篇幅原因,就不写了,大概流程如下:
...
listen_fd = bind(...);
listen(listen_fd, LISTENQ);
int epoll_fd;
struct epoll_event events[10];
int nfds, i, fd;
...
// 创建一个描述符
epoll_fd = epoll_create(...);
// 添加监听描述符事件
epoll_ctl(epoll_fd, ... listen_fd, ... EPOLLIN);
for ( ; ; )
{
nfds = epoll_wait(epoll_fd, events, sizeof(events)/sizeof(events[0]), 1000);
for (i = 0; i < nfds; i++)
{
fd = events[i].data.fd;
if (fd == listen_fd)
{
// 创建新连接
...
}
else if (events[i].events & EPOLLIN)
{
// 读取socket数据
....
}
else if(events[i].events & EPOLLOUT)
{
// 写入socket数据
...
}
}
}
close(epoll_fd);4、epoll的实现
epoll底层数据结构是红黑树和链表组成,通过epoll_ctrl增加、减少事件,其中epoll结构体如下:
struct eventpoll
{
wait_queue_head_t wq;
struct list_head rdlist;
struct rb_root rbr;
...
} epoll
epoll
(1)wq是等待队列,用于epoll_wait;
(2)rdlist是就绪队列,当有事件触发时候,内核会将句柄等信息放入rdlist,方便快速获取,不需要遍历红黑树;
(3)rbr是一颗红黑树,支持增加,删除和查找,管理用户添加的socket信息;
第三部分:提升网络编程中服务器性能的建议
在网络编程中我们会遇到各种各样的处理任务,比如纯转发的proxy,需要处理https的server,需要处理任务的业务逻辑server等等,而且在微服务时代和云原生时代可能这些问题更加复杂,比如我们需要在server前加上断路器,在容器服务中我们都适用多线程模式等等。虽然面临很多问题,但是网络编程中服务器性能还是最基础的那些问题,于是基于我的一些经验,我整理了一些。
1、复用
(1)线程复用 :前面提到的工作线程,我们不应该对于每个客户端都开一个线程,而是构建一个线程pool,当某些线程空闲就可以从队列中取事件或者数据进行处理,毕竟linux中的线程和进程调度方式一样,线程太多必然加剧内核的负载;
(2)内存复用 :在网络状态流转和工作线程流转过程中,我们需要尽可能考虑内存复用,而不是在每一层中都拷贝,比如一个请求从内核读到数据以后,尽可能在当前请求的什么周期内,一直使用相同的内存块(包括在业务层,尽量使用指针偏移量操作),减少拷贝;
当然减少内存拷贝以外,还需要做的就是同一块内存用完不是让系统回收,而是自己放到内存pool中,等待下一次请求需要再复用;
2、减少内存拷贝
这里上一篇文章提到的零拷贝,就是减少内存拷贝的一种方式,比如在文件读写方面能提升性能(可以参考nginx的sendfile),另一种可以使用共享内存,通过一写多读的方式解决一些场景下的内存拷贝;
3、减少上下文切换和竞争
上下文切换是阻碍性能提升的一个问题,比如频繁的事件触发会导致主线程和工作线程之间切换,其CPU时间会被浪费;小量的数据包多次触发读处理等。因此我们在写server过程中对于能在同一个上下文处理的,就不必要再丢该其他线程处理,对于多个小块数据可以等待一段超时时间一起处理(当然具体问题可以分析);
竞争也是阻碍性能提升的一个问题,挣抢共享资源会一段CPU时间片内阻塞操作,减少锁的使用或者将锁拆分更加细粒度的锁,减少锁住临界区的范围,是我们需要注意的;
4、利用CPU亲和性
这里以nginx为例,提供了一个worker_cpu_affinity,cpu的亲和性能使nginx对于不同的work工作进程绑定到不同的cpu上面去。就能够减少在work间不断切换cpu,进程通常不会在处理器之间频繁迁移,进程迁移的频率小,来减少性能损耗。
这种可以参考CPU性能提升方式,比如在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器(存储器的地方到另一个处理器之间共享的处理器或存储器)快一些,所以针对NUMA架构系统的特点,可以通过将进程/线程绑定指定CPU(一个或多个)的方式,提高CPU CACHE的命中率,减少进程/线程迁移CPU造成的内存访问的时间消耗,从而提高程序的运行效率。
5、协程
协程是一种用户态线程,在现在主流的server框架,协程已经成为一个提升性能的银弹(比如golang写server又快又方便),后续文章会专门介绍协程(在此埋一个坑),但是协程也不是万能的,需要定位本身业务特点,比如IO密集型就适合(当然这里也需要情况而定,比如纯转发类型的面对长尾延时,可能协程也不合适),CPU密集型自己调度协程还是比较麻烦的,所以在做优化的适合可以拷贝业务的特性和后续的扩展而定,毕竟没有一个框架是万能的。