性能优化目标
1、缩短响应时间
2、提高并发数(增加吞吐量)
3、让系统处于合理状态
 图片
图片
性能优化手段
1、空间换时间
系统时间是瓶颈: 缓存复用计算结果,降低时间开销,因为cpu时间较内存容量更加昂贵。
2、时间换空间
- 数据大小是瓶颈
- 网络传输是瓶颈,使用系统时间换取传输的空间,使用HTTP的gzip压缩算法
- app的请求分类接口,使用版本号判断哪些数据更新,只下载更新的数据
3、找到系统瓶颈
- 分析系统的业务流程,找到关键路径并分解优化
- 调用了多少RPC接口,载入多少数据,是用什么算法,非核心流程是否异步化。
性能优化层次
1、架构设计层次
如何拆分系统 如何使用部分系统整体负载更加均衡 充分发挥硬件设施性能优势 减少系统内部开销等
2、算法逻辑层次
关注算法选择是否高效,算法逻辑优化,空间时间优化任务执行吃力,使用无锁数据结构。
空间换时间:ThreadLocal
时间换空间:采用压缩算法压缩数据,更复杂的逻辑减少数据传输。
3、代码优化层次
关注代码细节优化,代码实现是否合理,是否创建了过多的对象,循环遍历是否高效,cache使用是否合理
优化层次:从整理到细节,从全局角度到局部视角。
代码优化层次(1)
- 循环遍历是否合理高效,不要在循环里调RPC接口,传输分布式缓存 执行SQL等
- 先调用批量接口组装好数据,再循环处理
- 代码逻辑避免生成过多的对象和无效对象
- 输出Log时候的log级别判断 避免new无效对象
- ArrayList、HashMap初始容量设置是否合理
- 对数据对象是否合理重用 比如RPC查到的数据能复用则必须复用,根据数据访问特性选择合适数据结构,比如读多写少考虑 CopyOrWriteArrayList(写时copy副本),会否正确初始化数据,有些全局共享的数据,饿汉式模式,在用户使用之前先初始化好。
代码优化层次(2)
- CPU Cache结 构
- 速度越来越高:内存 - >L3->L2->L1多级缓存
- 本质上内存是一个大的一维数组,二维数组在内存中按行排列,先存放a[0]行,再存放a[1]行
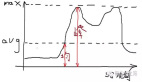
- 第一种遍历方式,是行遍历,先遍历完一行再遍历第二行,符合局部性原理Cache Hit (缓存命中率高)
- 第二种遍历方式,是列遍历,遍历完第一列遍历第二列,由于下一列和 上 一 列的数组元素在内存中并不是连续的,很可能导致Cache Miss ( 缓 存 未 命 中 ) , CPU 需要去内存载入数据,速度较CPU L1Cache的速度降低 了很多(主存100ns,L1 cache 0.5ns)
 图片
图片
数据优化层次
select count(*)from table where add time<"2017- 11-0623:59:59" and status=0 add count in(1,2) ORDER BY id ASC;代码逻辑要适应数据变化的场景
 图片
图片
 图片
图片
 图片
图片
算法优化逻辑层次
●用更高效的算法替换现有算法,而不改变其接口
● 增量式算法,复用之前的计算结果,比如一个报表服务,要从全量数据中生成报表数据量很大,但是每次增量的数据较少,则可以考虑只计算增量数据和之前计算结果合并,这样处理的数据量就小很多
● 并发和锁的优化,读多写少的业务场景下,基于CAS的LockFree比mutex 性能更好
● 当系统时间是瓶颈,采取空间换时间逻辑算法,分配更多空间节省系统时间
● 缓存复用计算结果,降低时间开销, CPU时间较内存容量更加昂贵
● 当系统空间容量是瓶颈,采取时间换空间算法策略
● 网络传输是瓶颈,使用系统时间换取空间的压缩, HTTP的gzip 压缩算法
● APP的请求分类接口,使用版本号判断哪些数据更新,只下载更新的数据,使用更多的代码逻辑处理更细粒 度的数据
● 并行执行,比如一段逻辑调用了多个RPC接口,而这些接口之间并没有数据依赖,则可以考虑并行调用,降低响 应时间
● 异步执行,分析业务流程中的主次流程,把次要流程拆分出来异步执行,更进一步可以拆分到单独的模块去执行, 比如使用消息队列,彻底和核心流程解耦,提高核心流程的稳定性以及降低响应时间
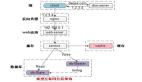
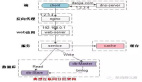
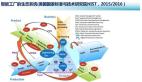
架构层次优化
● 系统微服务化
● 无状态化设计,动态水平弹性扩展
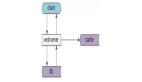
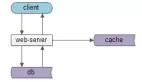
● 调用链路梳理,热点数据尽量靠近用户
● 分布式Cache 、 多级多类型缓存
● 提前拒绝,保证柔性可用
● 容量规划
● 分库分表,读写分离,数据分片
案例:
 图片
图片
Feed流系统分级缓存
读多写少、冷热数据明显,热点数据缓存到调用链路更靠近用户的地方
● L1缓存容量小负责抗最热点的数据, L2缓存考虑目标是容量,缓存更大范围的数据(一般用户的timeline), 高热点,数据单独缓存,比如设置白名单,大V 的用户数据放在L1缓存
● feed(关注的feed 、topic 的feed,一些运营的feed),前几页的访问比例,前三页占了90%+,针对这种业务特性,把 前面几页数据作为热点数据提到L1 cache
 Feed系统消息发布
Feed系统消息发布
写扩散 (PUSH)
● 推送策略:拆分数据并行推,活跃用户先推,非活跃用户慢慢推
● 有 1w个用户关注,发了一个feed,拆分成100份,每份100个并行推
● 1w个用户里活跃的可能有2000个,活跃用户先推,非活跃用户慢慢推,保证活跃用户体验,非活跃用户推 了很大概率也不看
读扩散(PULL)
 图片
图片
Feed系统存储选型
 图片
图片