













作者 | 崔皓
审校 | 重楼
摘要
本文作者受到一位国外博主的启发,决定尝试使用大语言模型创建一个地下城文字游戏。通过大语言模型生成富有创意和连贯性的游戏内容。他的游戏灵感主要来源于经典的桌面角色扮演游戏“龙与地下城”(D&D)。该游戏通过对话驱动,包括两个主要角色:故事描述者和主人公。故事描述者负责下达任务和推动故事,而主人公负责完成任务。作者设计了一个对话模拟器,用于处理角色之间的互动和游戏进程。此外,作者还考虑了游戏设计中的两个关键问题:记忆机制和发言规范。

开篇
自从在短视频平台上看到一位国外博主通过AI创建了一个模拟经营游戏,我就被深深吸引了。在他的虚拟小镇上,众多的NPC人物因AI的赋能而拥有了各种独特的性格,使得他们之间的互动充满了趣味和惊喜。这让我有点心痒痒,一直对游戏情有独钟的我,为什么不尝试借助AI的力量,创造一个属于自己的地下城文字游戏呢?然而,缺乏游戏开发经验成了我面前的一道障碍。不过转念一想,最近正在从事大语言模型开发的工作,而大语言模型本身就具备生成文字的能力。 我看到有人利用提示词和大模型可以玩文字的冒险游戏。带着这个想法,我查找了一些资料,发现通过prompt的方式真的可以“催眠”大模型,让它帮我创建一个游戏世界。
探索与尝试
有了上面的想法就要付诸行动了,说干就干,不过在开干之前需要对游戏进行构思,同时还要对实施的可行性进行评估。我的探索开始于ChatGPT,通过手动输入的方式,我和ChatGPT玩起了文字游戏。很快,我发现它与流行的龙与地下城游戏有异曲同工之妙—一个基于角色扮演的奇幻世界,玩家通过解决棘手的问题、勇敢的探险和激烈的战斗来推进故事。
龙与地下城(Dungeons & Dragons, 简称D&D)是一款源于1974年的桌上角色扮演游戏,它允许玩家在一个奇幻的中世纪环境中探险和战斗。玩家可以选择不同的角色,如战士、法师或盗贼,并通过掷骰子来决定行动的结果。游戏由一名地下城主(Dungeon Master, DM)来引导故事和管理游戏规则。D&D不仅创造了桌上角色扮演游戏的标准,也影响了后来的电子游戏和奇幻文学的发展。它的核心是集体讲述故事、解决问题和角色扮演,为玩家提供了一个丰富多彩、想象力驱动的游戏体验。
我可以通过龙与地下城游戏的玩法蓝本,来设计我的文字游戏。由于我没有任何的游戏设计经验,因此将游戏规则设计得简单明了,主要通过角色间的对话来推进游戏进程,以降低新手玩家的入门门槛。这里对话角色分为两个,分别是故事描述者和主人公,通过对话交互,玩家能够逐步深入游戏的核心,挑战和完成各种任务,同时享受与虚拟角色交流的乐趣。
趁热打铁,我们来设计一下文字游戏具体完成的任务。如下图所示,在文字游戏初始化的时候需要定义参与者,包括:主角(主人公)和故事的讲述者,故事的讲述者负责下达任务,而主人公负责完成任务。当然他们之间通过文字完成任务的交互,这里需要定义一个发言的规则。故事讲述者下达任务之后,主角会接着发言,推进故事,接着通过轮流发言的方式完成所有的任务。
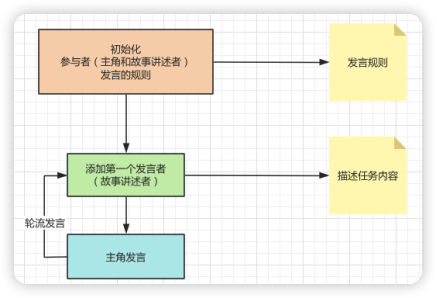
准备出发
有了思路以后就要准备开发所需要的模型和工具了。模型方面,我选择了OpenAI 的GPT-3.5-Turbo的版本,另外也考虑了使用百度千帆模型库中提供的ChatGLM2-6B-32K模型,不过在输入字符长度上前者比较有优势,因此还是选择了GPT,不过后面代码的部分,我会把ChatGLM2版本的代码以remark的方式呈现给大家,如果大家有兴趣可以自行尝试。
有了游戏背景,接着就需要考虑文字游戏都会遇到的两个问题:
记忆机制
在地下城游戏中,保持对话的连贯性和角色身份的一致性至关重要。为解决这个问题,我们设计了一个消息系统,它可以保存参与者的背景信息,包括:身份,发言的方式,以及哪些事情应该做,哪些事情不能做。每次提供提示给大模型时,都会利用该系统强化模型的记忆,确保游戏的流畅进行。刚好可以利用LangChain中的System Message 机制完成。
LangChain的`SystemMessage`是一个特殊的消息类型,它用于在与大语言模型的交互中提供上下文或指令。通过`SystemMessage`,可以向模型传达关于游戏的背景信息或其他重要指示,帮助模型生成更符合场景的回应。它是在构建交互式应用时,提供上下文和指导信息的有效方式。
发言规范
为保证游戏的有序进行,我们需要设定明确的发言顺序。在这个简单的场景中,我们选择了轮流发言的规则。为了未来能够轻松扩展到更多玩家或更复杂的交互规则,我们将发言规则独立为一个模块,从而为游戏提供了更多的灵活性。在实施的时候,也就是通过一个取模的函数就能够轻松搞定。如果遇到多人参与,或者存在交叉发言,玩家互相提问的场景,也可以设计更加负责的发言规则。总之需要将规则的部分独立出来,做到高内聚低耦合。
程序设计
有了游戏设计思路,接着我们对基本的程序进行设计。如下图所示,在入口的Main函数中我们会进行对话参数的初始化,例如:人物基本信息,背景信息的定义。然后,调用DialogueSimulator 添加玩家,同时设置发言规则,以及发起任务。接下来就是通过DialogueAgent 类进行文字消息的处理,这里只需要处理发送消息和接受消息。由于,本例中只有两个参与者,故事描述者和主人公所以发送和介绍消息会在两者之间轮流进行。
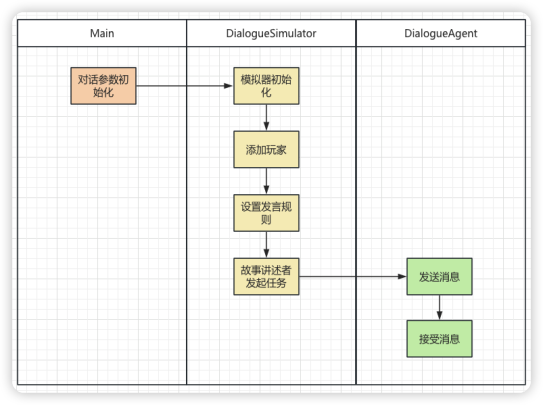
代码实践
完成了基本的设计工作,就是写代码了。这里我们使用Colab作为IDE工具,以及如何在此环境中配置和使用Langchain和GPT-3.5 Turbo。
Colab,即Google Colaboratory,是一个免费的Jupyter笔记本环境,无需进行任何设置就可以在浏览器中使用。它不仅提供了可靠的计算资源,还配备了GPU和TPU,可以加速机器学习或深度学习项目。Colab的特点包括实时多人协作、免费GPU资源、易于分享和集成Google Drive等。使用Colab的主要原因是它的便捷性和高效性。它省去了配置环境的麻烦。
首先,通过如下代码在colab中安装包和相关依赖:
!pip install openai langchain该命令用于安装Python包,以支持后续的开发工作:
1. `openai`:OpenAI的Python客户端库。
2. `langchain`:可能是与LangChain相关的库,支持与大语言模型的交互。
DialogueAgent 类
一个简单的封装器,围绕 ChatOpenAI 模型进行操作,通过简单地将消息作为字符串连接起来,从而存储 dialogue_agent 角度看到的消息历史。
它提供了两个方法:
- send():将 chatmodel 应用于消息历史,并返回消息字符串。
- receive(name, message):将由 name 发出的消息添加到消息历史中。
# 定义DialogueAgent类,用于表示对话中的一个代理(或参与者)
class DialogueAgent:
# 初始化方法,用于设置代理的基础属性
def __init__(
self,
name: str, # 代理名称:参与者,故事描述者,主人公
system_message: SystemMessage, # 系统消息对象
model: ChatOpenAI, # 聊天模型
) -> None:
self.name = name # 设置代理名称
self.system_message = system_message # 设置系统消息
self.model = model # 设置聊天模型
self.prefix = f"{self.name}: " # 设置消息前缀,用于标识消息来源
self.reset() # 调用reset方法初始化消息历史
# reset方法,用于重置或初始化消息历史
def reset(self):
self.message_history = ["Here is the conversation so far."] # 初始化消息历史
# send方法,用于生成并发送消息
def send(self) -> str:
"""
Applies the chat model to the message history
and returns the message string
"""
# 调用模型生成消息
message = self.model(
[
self.system_message, # 系统消息:背景
HumanMessage(content="\n".join(self.message_history + [self.prefix])), # 人类消息(包含历史和前缀)
]
)
#message = self.model(
# "\n".join([
# str(self.system_message),
# str(HumanMessage(content="\n".join(self.message_history + [self.prefix])))
# ])
#)
#return message.content
return message # 返回生成的消息
# receive方法,用于接收并记录消息
def receive(self, name: str, message: str) -> None:
"""
Concatenates message spoken by {name} into message history
"""
# 将接收的消息加入到消息历史中
self.message_history.append(f"{name}: {message}")DialogueSimulator 类
DialogueSimulator 类接受一个代理列表。在每一步中,它执行以下操作:
选择下一个发言者。调用下一个发言者来发送消息。将消息广播给所有其他代理。更新步骤计数器。下一个发言者的选择可以通过任何函数来实现,但在这种情况下,我们简单地遍历代理。
代码如下:
# 定义一个DialogueSimulator类来模拟对话
class DialogueSimulator:
# 初始化方法,用于设置类的基本属性
def __init__(
self,
agents: List[DialogueAgent], # 代理列表,包含所有对话的参与者
selection_function: Callable[[int, List[DialogueAgent]], int], # 选择下一个说话者的函数
) -> None:
self.agents = agents # 将传入的代理列表保存为实例变量
self._step = 0 # 初始化步数为0
self.select_next_speaker = selection_function # 设置选择下一个说话者的函数
# 重置方法,用于重置所有代理的状态
def reset(self):
for agent in self.agents: # 遍历每个代理
agent.reset() # 调用每个代理的reset方法进行重置
# 初始化对话的方法
def inject(self, name: str, message: str):
"""
Initiates the conversation with a message from a specific agent
"""
for agent in self.agents: # 遍历每个代理
agent.receive(name, message) # 让每个代理接收初始消息
self._step += 1 # 增加步数计数
# 进行一步对话的方法
def step(self) -> tuple[str, str]:
# 1. 选择下一个说话的代理
speaker_idx = self.select_next_speaker(self._step, self.agents) # 使用选择函数选择代理
speaker = self.agents[speaker_idx] # 获取选中的代理
# 2. 让选中的代理发送消息
message = speaker.send() # 获取代理发送的消息
# 3. 让所有代理接收这条消息
for receiver in self.agents: # 遍历所有代理
receiver.receive(speaker.name, message) # 让每个代理接收消息
# 4. 增加步数计数
self._step += 1 # 更新步数
# 返回说话代理的名字和消息内容
return speaker.name, message定义角色
在这段代码中,定义了四个变量,用于存储故事或任务的关键信息。
这四个变量为我们在进一步编写或生成故事提供了基础信息。
protagonist_name = "马小虎"
storyteller_name = "神秘老人"
quest = "找到传说中的七件神器。"
word_limit = 50 1. `protagonist_name = "马小虎"`:这一行定义了主角(故事中的主要人物)的名字为"马小虎"。
2. `storyteller_name = "神秘老人"`:这一行定义了讲故事的人(故事的叙述者)的名字为"神秘老人"。
3. `quest = "找到传说中的七件神器。"`:这一行定义了主角需要完成的任务或探险目标。
4. `word_limit = 50`:这一行定义了用于任务的字数限制为50字。在进行任务时,需要设置一个字数限制以保持焦点和简洁性。
故事背景描述
下面这段代码主要用于生成一个地下城冒险游戏的描述和提示。它涉及到两个主要角色:主人公(由变量 `protagonist_name` 定义)和故事讲述者(由变量 `storyteller_name` 定义)。代码的目的是通过自然语言模型(在这里是 GPT-3.5 Turbo 或一个名为 "QianfanLLMEndpoint" 的模型)来生成这两个角色的详细描述。
game_description = f"""这是一场地下城冒险游戏: {quest}.
游戏中存在一名玩家: 主人公, {protagonist_name}.
故事由故事的讲述者来描述, {storyteller_name}."""
player_descriptor_system_message = SystemMessage(
content="你可以为这场地下城冒险游戏添加细节."
)
#主人公提示词
protagonist_specifier_prompt = [
player_descriptor_system_message,
HumanMessage(
content=f"""{game_description}
请用创意的方式来描述主人公, {protagonist_name}, 描述字数不超过 {word_limit} 个.
并且说出主人公的名字, {protagonist_name}.
除此之外不要添加其他信息."""
),
]
#llm 生成对主人公的描述
protagonist_description = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=1.0)(
protagonist_specifier_prompt
).content
#llm = QianfanLLMEndpoint( model="ChatGLM2-6B-32K", temperature = 1.0)
#protagonist_description= llm.generate([str(protagonist_specifier_prompt)])
#故事讲述者提示词
storyteller_specifier_prompt = [
player_descriptor_system_message,
HumanMessage(
content=f"""{game_description}
请用创意的方式来描述故事讲述者, {storyteller_name}, 描述字数不超过 {word_limit} 个.
并且说出故事讲述者的名字, {storyteller_name}.
除此之外不要添加其他信息."""
),
]
#llm 生成对故事描述者的描述
storyteller_description = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=1.0)(
storyteller_specifier_prompt
).content
#storyteller_description = llm.generate([str(storyteller_specifier_prompt)])
1. 生成游戏描述: 使用前面定义的 `quest`, `protagonist_name`, 和 `storyteller_name` 变量来形成一个完整的游戏描述 (`game_description`)。
2. 创建系统消息:一个名为 `SystemMessage` 的类被用来生成一个提示消息,提示玩家可以为这场游戏添加更多细节。
3. 生成主人公描述:使用自然语言模型和一个特定的提示 (`protagonist_specifier_prompt`) 来生成主人公的描述 (`protagonist_description`)。
4. 生成故事讲述者描述:同样地,使用自然语言模型和一个特定的提示 (`storyteller_specifier_prompt`) 来生成故事讲述者的描述 (`storyteller_description`)。
我们将上面的信息打印出来验证一下:
print("Protagonist Description:")
print(protagonist_description)
print("Storyteller Description:")
print(storyteller_description)打印内容:
Protagonist Description:
马小虎,一个年轻而勇敢的剑士,有着黑色的蓬松头发和剑刃一样锐利的眼神。
Storyteller Description:
故事讲述者: 神秘老人,耄耋仙人。主角与地下城主的系统消息
这段代码生成一个更具体和详细的任务描述(`specified_quest`),该任务描述是为地下城冒险游戏的主角(`protagonist_name`)准备的。
# 定义一个名为 quest_specifier_prompt 的列表,包含 SystemMessage 和 HumanMessage 对象
quest_specifier_prompt = [
# 系统消息,提示可以使任务更具体
SystemMessage(content="你可以使任务更具体。"),
# 人类消息,要求故事讲述者更具体地描述任务
HumanMessage(
content=f"""{game_description}
你是故事讲述者,{storyteller_name}。
请使任务更具体化。请富有创意和想象力。
请用{word_limit}个词或更少回复指定的任务。
直接对主角{protagonist_name}说话。
不要添加其他任何内容。"""
),
]
specified_quest = ChatOpenAI(model_name='gpt-3.5-turbo',temperature=1.0)(quest_specifier_prompt).content
#specified_quest = llm.generate([str(quest_specifier_prompt)])
print(f"原始任务描述:\n{quest}\n")
print(f"详细任务描述:\n{specified_quest}\n")1. 定义任务指定提示(`quest_specifier_prompt`)**:这个列表包含两种类型的消息对象:`SystemMessage` 和 `HumanMessage`。`SystemMessage` 提供了一种简单的提示,即"你可以使任务更具体"。`HumanMessage` 则给出了详细的指示,包括当前的游戏描述、故事讲述者的名字,以及对任务应如何具体化的要求。
2. 生成具体任务(`specified_quest`)**:使用前面定义的 `quest_specifier_prompt` 和自然语言模型(在这里是 GPT-3.5 Turbo)来生成一个更具体和详细的任务描述。
3.*输出结果:最后,代码打印出原始的任务描述和新生成的更具体的任务描述。
打印结果如下:
output
原始任务描述:
找到传说中的七件神器。
详细任务描述:
马小虎,你需要穿越一条幻想之河,进入寒冰之洞穴。在那里,你将遇到一只被诅咒的巨龙。唤醒它的心灵,获取神器第一件:冰霜之剑。完成任务,勇士。哈哈,此时我们的参与者(故事描述者和主角)都已经有了,并且各自的背景都准备好了,任务也随之生成了。接下来就是执行游戏的部分了。
主函数入口
这段代码的主要目的是模拟一个交互式故事,其中包括两个角色:主人公(`protagonist`)和故事讲述者(`storyteller`)。这些角色在一个预定义的对话模拟器(`DialogueSimulator`)中轮流互动。
#主人公
protagonist = DialogueAgent(
name=protagonist_name,
system_message=protagonist_system_message,
model=ChatOpenAI(model_name='gpt-3.5-turbo',temperature=0.2),
#model = llm,
)
#故事描述者
storyteller = DialogueAgent(
name=storyteller_name,
system_message=storyteller_system_message,
model=ChatOpenAI(model_name='gpt-3.5-turbo',temperature=0.2),
#model = llm,
)
#发言顺序:轮流发言
def select_next_speaker(step: int, agents: List[DialogueAgent]) -> int:
idx = step % len(agents)
return idx
max_iters = 12
n = 0
simulator = DialogueSimulator(
agents=[storyteller, protagonist], selection_function=select_next_speaker
)
simulator.reset()
#故事描述者 , 任务的描述
simulator.inject(storyteller_name, specified_quest)
print(f"({storyteller_name}): {specified_quest}")
print("\n")
while n < max_iters:
name, message = simulator.step()
print(f"({name}): {message}")
print("\n")
n += 11. 初始化角色:使用 `DialogueAgent` 类创建两个不同的角色,其中包括他们的名字、系统消息和使用的模型(这里是 GPT-3.5 Turbo)。
2.选择发言人函数: `select_next_speaker` 函数用于确定在对话中哪个角色应该接下来发言。这里使用了一个简单的轮流机制。
3.对话模拟:使用 `DialogueSimulator` 类创建一个对话模拟器,该模拟器接受角色列表和选择发言人的函数。
4.注入初始任务:使用 `simulator.inject()` 方法将特定的任务描述(`specified_quest`)作为故事讲述者的初始发言注入。
5.对话循环:在一个循环中,角色轮流发言,直到达到最大迭代次数(`max_iters`)。
执行代码我们可以看到如下的结果,如下图所示看来马小虎和神秘老人的文字游戏进展还是比较顺利的,随着他们的对话,给我们揭开了一个奇幻的游戏世界。

总结
本文展示了如何用AI技术创建一个简单的文字游戏,是对大语言模型应用的一次尝试。通过使用大语言模型,作者能够生成复杂性的游戏内容,从而提供了富有想象力的游戏体验。文章还强调了模块化在游戏设计中的重要性,特别是在处理记忆和发言规范等方面。是一个非常有趣的项目,不仅展示了大语言模型在游戏开发中的应用,也为那些对AI和游戏感兴趣的人提供了启示和经验。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。


















