大型语言模型 (LLMs) 在各种自然语言任务中展现出了卓越的性能,但是由于训练和推理大参数量模型需要大量的计算资源,导致高昂的成本,将大语言模型应用在专业领域中仍存在诸多现实问题。因此,北理团队先从轻量级别模型入手,最大程度发挥数据和模型的优势,立足更好地服务特定领域,减少下游任务的训练与推理成本。
10 月 24 日,北京理工大学自然语言处理团队发布系列双语轻量级大语言模型明德 (Ming De LLM)——MindLLM,全面介绍了大型模型开发过程中积累的经验,涵盖了数据构建、模型架构、评估和应用过程的每个详细步骤。MindLLM 从头开始训练,具有 1.3B 和 3B 两个版本, 在某些公共基准测试中始终匹配或超越其他开源大型模型的性能。MindLLM 还引入了专为小型模型量身定制的创新指令调整框架,来有效增强其能力。此外,在法律和金融等特定垂直领域的应用,MindLLM 也具有出色的领域适应能力。


- 论文地址:https://arxiv.org/abs/2310.15777
MindLLM 亮点
- 我们分享了数据处理方面的经验,包括维护高质量和高比例的网络文本、保留书籍和对话等长期数据、对数学数据进行下采样,同时对代码数据进行上采样。我们建议均匀地打乱数据以进行能力学习,并将一些样本分块以用于小样本学习场景。
- 我们的评估结果优于部分大型模型,在未使用指令微调和对齐时,MindLLM模型 在 MMLU 和 AGIEval 评测上的性能优于 MPT-7B 和 GPT-J-6B 等大型模型。在中文方面,MindLLM 在 C-Eval 和 CMMLU 上表现出与更大参数模型相当的性能。具体来说,MindLLM-3B 在数学能力上优于 MOSS-Base-16B、MPT-7B 等较大模型,在双语能力上超过 Baichuan2-7B 和 MOSS-Base-16B。而且,MindLLM-1.3B 在数学上比同等大小的 GPT-Neo-1.3B 更好。
- 我们比较了双语学习中两种不同的训练策略,并研究在预训练期间是否保持数据均匀分布的影响。我们得出的结论,对于容量规模有限的轻量级模型(≤7B)来说,通过预训练然后迁移训练的策略来实现数学、推理或双语对齐等复杂能力并不是最优的,因为整合新知识和现有知识是困难的。相比之下,更有效的策略是从头开始,结合下游任务的需求,对多种数据类型进行整合,从而确保所需能力能够稳定且有效地获取。
- 我们发现在指令调优过程中利用针对特定能力的定制数据,可以显着增强轻量级模型的特定能力,例如综合推理能力或学科知识能力。
- 我们介绍了使用基于熵的质量过滤策略构建指令集的方法,并证明了其在过滤轻量级模型的高质量指令调整数据方面的有效性。我们证明,在轻量级模型的背景下,通过改善指令调优数据质量可以更有效地实现模型性能的优化,而不是仅仅增加数据量。
- 我们的模型在特定领域展现出了出色表现,特别是在法律和金融等领域。我们发现模型参数大小的差异不会在特定领域内产生显着差异,并且较小的模型可以优于较大的模型。我们的模型在特定领域优于参数大小从 1.3B 到 3B 的所有模型,同时与参数大小从 6B 到 13B 的模型保持竞争力,而且模型在特定领域内的分类能力在 COT 方法下显著增强。
数据相关
数据处理
我们使用英文和中文两种语言的训练数据。英文数据源自Pile数据集,经过进一步处理。中文数据包括来自Wudao、CBooks等开源训练数据,以及我们从互联网上爬取的数据。为确保数据质量,我们采用了严格的数据处理方法,特别是对于从网络爬取的数据。
我们采用的数据处理方法包括如下几个方面:
- 格式清洗:我们使用网页解析器从源网页中提取和清理文本内容。这一阶段包括去除无用的HTML、CSS,JS标识和表情符号,以确保文本的流畅性。此外,我们处理了格式不一致的问题。我们还保留了繁体中文字符,以便我们的模型能够学习古代文学或诗歌。
- 低质量数据过滤:我们根据网页中的文本与内容的比例来评估数据质量。具体来说,我们会排除文本密度低于75%或包含少于100个中文字符的网页。这一阈值是通过对抽样网页进行初步测试确定的。
- 数据去重:鉴于WuDao的数据也源自网页,某些网站可能会重复发布相同的信息。因此,我们采用了局部敏感哈希算法,用以去除重复内容,同时保留了我们训练数据的多样性。
- 敏感信息过滤:鉴于网页通常包含敏感内容,为构建一个积极正向的语言模型,我们采用了启发式方法和敏感词汇词库来检测和过滤这些内容。为了保护隐私,我们使用正则表达式来识别私人信息,如身份证号码、电话号码和电子邮件地址,并用特殊标记进行替换。
- 低信息数据过滤:低信息数据,如广告,通常表现为重复内容。因此,我们通过分析网页文本内容中的短语频率来鉴别这类内容。我们认为来自同一网站的频繁重复短语可能对模型学习不利。因此,我们的过滤器主要关注广告或未经认证的网站中的连续重复短语。
最终我们获得了数据如下表:

Scaling Law
为了确保在深度学习和大型语言模型的训练成本不断增加的情况下获得最佳性能,我们进行了数据量和模型容量之间的关系研究,即Scaling Law。在着手训练具有数十亿参数的大型语言模型之前,我们首先训练较小的模型,以建立训练更大模型的扩展规律。我们的模型大小范围从1千万到5亿参数不等,每个模型都在包含高达100亿tokens的数据集上进行了训练。这些训练采用了一致的超参数设置,以及前文提到的相同数据集。通过分析各种模型的最终损失,我们能够建立从训练FLOP(浮点运算数)到Loss之间的映射。如下图所示,不同大小的模型饱和的训练数据量不同,随着模型大小的增加,所需的训练数据也增加。为了满足目标模型的精确数据需求,我们使用了幂律公式来拟合模型的扩展规律,并预测出3B参数模型的训练数据量与Loss数值,并与实际结果进行对照(图中星标)。

数据混杂与数据课程
数据对模型的影响主要涵盖两个方面:(1)混合比例,涉及如何将来自不同来源的数据组合在一起,以在有限的训练预算下构建一个特定大小的数据集;(2)数据课程,涉及来自不同来源的数据的排列方式,以训练模型特定的技能。
我们将每个数据来源等比例缩小,用于训练15M参数量的模型。如下图所示,不同类型的数据对学习效率和模型最终结果有不同的影响。例如,数学题数据的最终损失较低,学习速度较快,表明它具有更为明显的模式且容易学习。相比之下,来自信息丰富的书籍或多样化的网络文本的数据需要更长的适应时间。一些领域相似的数据可能在损失上更为接近,例如技术相关数据和百科全书。
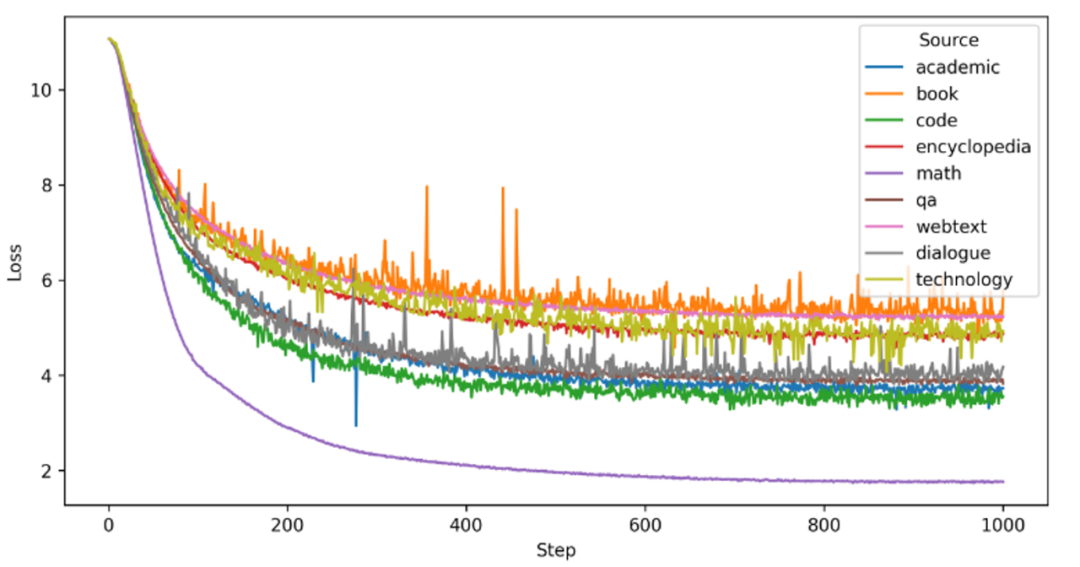
为了进一步探究模型从单一数据泛化到其他数据的性能,我们使用这些在单一数据上训练好的模型在其他数据上进行测试,结果如下图所示:

不同数据集展现出不同程度的泛化能力,例如:网页文本、百科全书和问答数据训练的模型在多个数据源上展现出较强的泛化能力,表明它们的内容包含了各个领域的多样信息。相比之下,学术论文数据和代码数据训练的模型在数学能力上表现出色,但在泛化方面较弱,可能是由于领域特定性和独特的格式信息。
此外,我们进行了多次的数据比例调整,以平衡模型在各种技能和数据类型之间的表现。基于我们的实验,我们最终确定了数据混合比例的一些原则:
- 保持高质量网络文本和百科全书数据的比例,因为它们具有多样性。
- 降低数学数据的比例,以避免过拟合。
- 利用代码和学术数据来增强数学能力,同时通过多样化的抽样和相关处理减轻格式的影响。
- 保留一些对话和书籍数据,有助于学习长程依赖关系。
除了混合比例,数据课程(数据的训练顺序)也会影响模型的能力学习。实验表明,不同来源的数据将使模型学习不同的技能,由于技能之间的相关性,采用特定的学习顺序可能有助于模型学习新的技能。我们的实验集中于非均匀混合数据和语言迁移学习对模型能力的影响。我们的实验表明,非均匀混合数据会导致模型在同一类型数据上进行连续训练,这更接近于上下文内学习的情境,因此在少样本学习方面表现更好;然而,由于学习的不均匀性,后期可能会出现明显的遗忘现象。此外,语言迁移学习有助于模型获得双语能力,通过语言对齐可能提高整体性能,但我们认为使用混合语言数据进行训练更有利于模型能力的分配与习得。
MindLLMs 模型架构
MindLLM-1.3B采用的是GPTNeo-1.3B相同的模型架构,而MindLLM-3B则是在此基础上增加了一些改进。基于训练稳定性和模型能力方面的考虑,我们使用旋转位置编码(RoPE)DeepNorm、RMS Norm、FlashAttention-2、GeGLU等优化算子。
我们在GPTNeo-1.3B的基础上增加了中文词表,并采用迁移学习的策略训练MindLLM-1.3B的双语能力。而MindLLM-3B,我们则是使用来自SentencePiece的BPE来对数据进行分词,我们的Tokenizer的最终词汇量大小为125,700。通过两种不同的双语训练方式,我们总结了一些普遍实用的预训练方法。
预训练
预训练细节
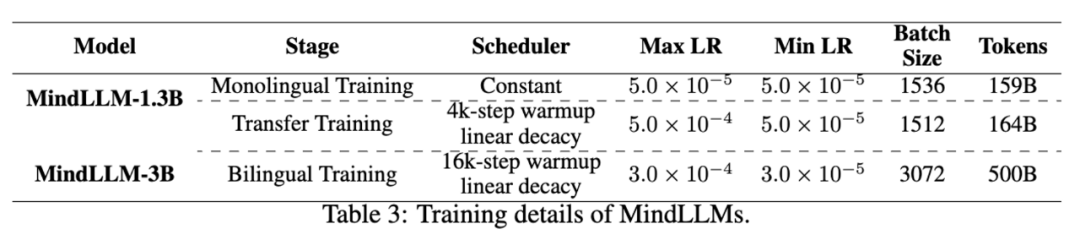
我们使用了两种不同的策略从头训练双语模型MindLLM。对于MindLLM-3B,我们直接在混合的中英文双语数据上预训练了800,00步,同时学习中英文能力;对于MindLLM-1.3B,我们首先在英文数据集上进行预训练101,100步,然后使用中英文混合数据训练了105,900步。预训练细节如下:
预训练阶段评估
较小的模型可以击败更大的模型
为评估模型的中英文能力,我们使用MMLU(5-shot)和AGIEval(4-shot)评估模型英文能力,使用C-Eval(5-shot)和CMMLU(4-shot)评估模型的中文能力。其中AGIEval采用英文部分的多选题部分。评估结果如下:

在英文表现上,MindLLMs平均水平超过了GPT-J-6B,MPT-7B,MOSS-Base-16B等更大的模型,并接近Falcon-7B,而后者均有更大的模型规模和更多的预训练数据。在中文能力上,MindLLMs则和开源的LLMs表现相当。值得说明的是,目前MindLLMs仍在训练增强中。
此外,我们发现数据量更少,但是使用了中英文数据训练的MindLLM-1.3B在MMLU上的表现优于GPT-Neo-1.3B,我们推测这可能是双语学习带来的增益,因为不同语种在能力之间也存在共通性。详细实验和分析可查看论文4.4节。
较小的模型在具体能力上存在巨大的潜力
对于轻量级模型,在应用于下游任务时,只需要存在相关的能力上展现出出色的表现即可。因此,我们本部分想要探究MindLLMs和其他轻量级LLM在(≤7B)具体能力上的表现和影响因素。
我们主要从数学能力、推理能力和双语对齐能力三个角度评估不同模型表现,因为这三种能力复杂且对于双语模型的应用相对重要。
(1) 数学
我们使用Arithmetic(5-shot)数据集评估模型的算数能力,使用GSM8K(4-shot)和MATH(4-shot)评估模型的通用数学能力。评估结果如下:

我们发现,MindLLM-3B在数学能力上的平均分数达到了16.01,超过了MOSS-Base-16B(15.71)和MPT-7B(13.42),GPT-J-6B(13.15)。此外MindLLM-1.3B的数学平均水平也超过了相同大小的GPT-Neo-1.3B。以上结果表明,轻量级模型在数学上有着巨大的潜力,较小的模型也可以在具体领域表现出超越或者与更大模型相当的水平。进一步,我们可以看到数学能力较为出色的(均分≥15),除MindLLM-3B,均为7B左右的模型。这表明,如数学能力类似的复杂能力的全面获取可能会收到模型规模的限制,这一猜测可以进一步在模型双语能力和推理能力的评估进一步体现。
(2) 推理
我们使用HellaSwag、WinoGrande评估模型语言推理能力(5-shot),使用LogiQA评估模型逻辑推理能力(5-shot),使用PubMedQA、PIQA、MathQA评估模型知识推理能力(5-shot),使用BBH评估模型综合推理能力(3-shot)。具体评估结果如下:

首先,在模型容量有限的条件下,双语带来的能力增益可能需要和语言学习对模型能力容量的消耗进行平衡。语言学习会占据部分模型能力容量,使得复杂能力如推理能力可能无法全面获取。比如MindLLM-1.3B在英文MMLU评估指标上均优于GPT-Neo-1.3B,但在推理能力的平均水平上弱于后者(35.61 vs 38.95)。而Blooms的推理能力没有特别出色,但后续评估的双语能力出色,这也一定程度上印证了以上观点。其次,规模越大的预训练数据集可能包含的世界知识更多,这样边有助于模型进行推理任务,例如Open-LLaMA-3B的推理表现和较大的模型表现相当,而其预训练数据为1T B,超过了其它同规模的模型所使用的预训练数据。因此,较小规模的模型依旧能够有潜力在推理能力上获得和较大模型相当的表现。另外,我们发现MOSS在推理上的水平似乎没有从前期代码数据的学习获得增益而表现更好(MOSS在CodeGen上进行了继续训练),但相关工作表明,代码确实有利于模型推理能力的提升,那么到底代码数据如何以及何时加入训练来增强模型的推理能力值得进一步探讨。
(3) 双语能力
我们使用Flores-101(8-shot)中的zh-en部分评估双语或者多语模型在中英文上的对齐能力。我们加入Chinese-LLaMA-2-7B进行评估,其为在LLaMA-2-7B基础上进行中文领域适应的模型。结果如下所示:

我们发现,模型在英文到繁体中文的翻译表现均不佳,这主要是预训练数据中的繁体中文占比很少。除此外,只有Blooms和MindLLM-3B在中文到英文和英文到中文双向的语言对齐上表现出色,其次为LLaMA-2-7B和MOSS-Base-16B。而LLaMA-7B和Open-LLaMA-7B则只能在中文到英文上对齐。结合模型预训练的数据可以知道,Blooms和MindLLM-3B的预训练数据中中英文比例较平衡,而LLaMA-2-7B中中文数据比例远低于英文,在LLaMA-7B和Open-LLaMA-7B的预训练数据中中文比例更少。
因此,我们有两个结论,其一是模型可以通过在某种语言上进行大量的训练学习到通过的语言表示,同时混入少量的另一种语言就可以理解并进行单向对齐,如LLaMA-7B和Open-LLaMA-7B的表现。其二则是,若需要获得更好的双语或多语对齐能力,那么在预训练开始阶段就需要有较平衡的双语或多语数据比例,如Blooms和MindLLM-3B。进一步,我们发现MOSS-Base-16B和Chinese-LLaMA-2-7B存在较合理的中英文数据比例,单依旧没有表现出双向对齐,我们的假设是双语对齐能力在迁移训练的时候加入是困难的,因为此时的模型已经存在了大量的知识,这在容量较小的情况下会产生矛盾冲突。这也解释了容量更小,前期单语训练的数据量少的MindLLM-1.3B也没有获得双语对齐能力的现象。而Baichuan2-7B在其他表现方面非常出色,可能也就占据了较大的能力容量,无法学习到较好的双向对齐能力。
(4) 总结
通过评估预训练阶段的评估结果,我们有一下两个结论:
- 轻量级模型在特定的领域或者能力上有巨大的潜力超过或者达到更大模型的水平。
- 对于容量有限的模型(≤7B),我们可以在预训练数据中根据下游任务的具体能力需求合理分配数据比例,这样有利于模型从头稳定地学习获取目标能力,并进行不同知识与能力的融合和促进。
此外,论文中还对比了是否保持数据均匀分布对模型预训练性能的影响,实验结果显示类似课程学习的数据构造方式可能在前期和均匀混合的数据构造方式下训练的模型表现相当,但是最终可能出现灾难性遗忘而导致表现突然下降,而后者表现则更持续稳定,获取的预训练数据知识也更加全面,这也佐证了以上第二点结论。另外我们发现类似课程学习的数据构造方式可能产生更多有利于增强模型上下文学习能力的数据分布。具体细节可以查看论文4.5部分。
指令微调
我们想要探讨在轻量级模型上,不同类别数据集的指令微调会有什么样的性能表现。下表是我们使用的指令微调数据集,包含我们重新构造的中文数据集MingLi、公开数据集Tulu(英文)和中英双语数据集MOSS。

对于MindLLM来说,指令微调的数据质量要比数据数量更加重要。
MindLLM-1.3B和MindLLM-3B模型在不同数据下指令微调后在C-Eval上的性能表现如下。从实验结果看,使用精心挑选的50,000条指令微调数据集训练的模型性能要高于多样性高、数据量大的指令微调数据集训练的模型性能。同样,在英文指标MMLU上,模型也表现出相同的性能(详见论文Table 14)。因此,对于轻量级模型来说,如何定义和筛选出高质量的指令微调数据集是非常重要的。

基于数据熵的指令微调数据筛选策略
如何定义高质量的指令微调数据?有学者提出指令微调数据的多样性可以代表指令微调数据集的数据质量。然而根据我们的实验发现,指令微调的数据熵和数据长度会更加影响轻量级模型的性能。我们将每条数据在预训练模型上的交叉熵损失定义为该数据的数据熵,并通过K-Means算法依据数据熵对数据进行聚类得到不同的数据簇。MindLLM经过每个数据簇的指令微调后再C-Eval的结果如下表所示(MMLU的结果详见论文Table19):

依据表中结果可知,MindLLM-1.3B和MindLLM-3B在不同数据簇上的表现相差明显。进一步的,我们对数据熵和模型在C-Eval和MMLU上的准确率的关系进行和函数拟合分析,如图所示:

图像中红色五角星的点为预训练模型的熵值。根据分析可知,当数据的熵比预训练模型的熵高1-1.5时,模型经过该区间的数据指令微调后性能最佳。因此,我们通过数据熵定义了高质量数据,并且提出了筛选高质量数据的方法。
MindLLM可以经过指定指令微调数据集获得特定能力
为了探究MindLLM能否经过指令微调有效的提升其特定能力,我们使用万卷数据集中的exam数据部分微调模型,目的是为了增强模型的学科知识能力。我们在C-Eval上进行了评估,结果如下:

可以看到,经过指令微调之后,模型在学科知识能力上有了很大的提升,1.3B的MindLLM的性能甚至超过ChatGLM-6B、Chinese-Alpaca-33B等更大规模的模型。因此我们认为MindLLM在指令微调后可以提升其特定能力,又鉴于其轻量级的特点,更适合部署在下游垂直领域任务之中。
领域应用
为了展示小模型在具体领域应用的效果,我们采用了在金融和法律两个公开数据集来做出验证。从结果中可以观察到,模型的参数大小对领域性能有一定影响,但表现并不明显。MindLLM的性能在领域应用内超越了其它同等规模的模型,并且与更大的模型有可比性。进一步证明了小模型在领域应用落地有极大潜力。
金融领域
在该领域,对金融数据进行情绪感知分类任务。首先,我们从东方财富网爬取了2011年5月13日至2023年8月31日的数据,并根据接下来的股价波动对数据进行了标记。随后,按照日期将数据划分为训练集和测试集。考虑到类别的不平衡性,我们对数据进行了采样,最终使用了32万条数据作为训练集,而测试集则采用了2万条数据。

我们通过两种不同的训练方法来比较不同模型的表现。第一,仅适用简单的监督微调(Supervised Fine-Tuning, SFT)对文本进行分类训练。第二,从ChatGPT中蒸馏推理过程数据,并将其作为辅助数据添加到训练中,具体采用了COT(Chain-Of-Thought)训练方式。

实验结果表明,通过补充辅助信息,可以在不同程度上提升所有baseline模型和MindLLM模型效果。进一步可观察到,COT 训练使得 MindLLM-1.3B 和 3B 的性能比 SFT训练性能分别提高了 27.81% 和 26.28%,除了Baichuan-7B以外,MindLLM比其他模型提高幅度更加显著。此外,MindLLM-1.3B 和 3B 在相同规模下达到了最佳性能,而且超过了 ChatGLM2-6B 和 Open-LLaMA-7B。
法律领域
我们收集了一些公开的法律相关数据,并结合了一些通用指令数据对 MindLLM 进行指令微调 (SFT)。为了探究数据的 token 长度是如何影响模型在具体领域上的性能的,我们使用不同数据长度的数据来分别训练 MindLLM。我们首先筛选了长度小于450的全部数据,然后分别使用 MindLLM-1.3B 和 MindLLM-3B 的Tokenizer筛选出长度在200-300和300-450之间的数据。数据统计和所对应的训练模型如下表所示:

为了避免人类评估产生的偏差和专业知识不足造成的错误,我们使用采用chatgpt作为评估器,具体方法如下。由ChatGPT生成的多轮法律咨询对话数据集,提取了其中100个对话作为我们的评估数据。我们使用ChatGPT来评估模型对于法律咨询的回复,让ChatGPT对于模型的回复进行排序,再根据排序结果计算Elo分数。最终筛选出一个最佳模型作为 MindLLM-Law 和其它开源模型相比较。
对于 Bloom,GPT-Neo 和 Open-LLaMA 模型使用了和 MindLLM-Law 一样的数据集进行了微调,比较结果如下所示:

结果显示 MindLLM-Law 尚未超越具有 13B 参数的模型和 ChatGLM2-6B,其主要原因是我们在预训练阶段法律方面数据不足,未能带来更大的增益。但是,MindLLM相较于 Baichuan2-7B-Chat、微调后的 Open-LLaMA-7B 和其他同规模模型来讲,整体优势非常明显。
总结
本文介绍了 MindLLM 系列模型,目前包括两款轻量级大语言模型。我们详细探讨了它们的训练过程,包括数据处理、预训练、微调、以及领域应用,分享了在这些领域所积累的宝贵经验和技术应用。尽管 MindLLM 的参数规模相对较小,但它们在多个性能评测中表现出色,甚至在某些方面超越了一些更大体量的模型。MindLLM 在领域适应方面相对于其他轻量模型表现出更卓越的性能。同时,与更大规模的模型相比,它们能够以更快的训练速度和更少的训练资源取得相当的成绩。基于以上分析,我们认为小模型仍然具有极大的潜力。我们将进一步提升数据质量,优化模型训练过程和扩展模型规模,以多维度方式提升 MindLLM 的性能。未来,我们计划在更多下游任务和特定领域进行尝试,以更深入地实现轻量级大模型的具体应用。