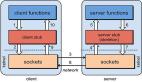
通常,面试官在评估你的系统架构设计能力时,经常会要求你分享在上一家公司如何设计系统架构,以便了解你的设计能力和思维过程。
在解释架构设计时,你会逐步向面试官证明自己负责的系统如何实现高可用性。这需要涉及一个公认的指标 - 服务水平协议(Service-Level Agreement,SLA)。服务水平协议是由服务提供者和用户双方签订的合同或协议,规定了双方的商务关系或部分商务关系。简单来说,SLA是衡量服务可用性的一个重要指标。
业界通常使用"几个9"的标准来衡量互联网应用的可用性。例如,京东的可用性是四个9(99.99%)。这意味着京东的服务承诺在所有运行时间中只有0.01%的不可用时间,也就是说一年中只有大约52.6分钟不可用。这个99.99%被称为系统的可用性指标。
52.6 分钟是怎么计算出来的呢?
 图片
图片
从公式中可以看出, SLA 等于 4 个 9,也就是可用时长达到了 99.99% ,不可用时长则为是0.01%,一年是 365 天, 8760 个小时,一年的不可用时长就是 52.6 分钟,那么:
SLA 等于 3 个 9,就相当于一年不可用时长等于 526 分钟;
SLA 等于 5 个 9,就相当于一年不可用时长等于 5.26 分钟。
可以发现,用 SLA 等于 4 个9 作为参照物,少个 9 相当于小数点往后移一位,多个 9 相当于小数点往前移一位(我把系统可用性指标总结成一张表格)。
 图片
图片
案例分析
在评估系统的高可用性时,仅仅按时间指标度量是不够的。因为在互联网公司,低峰期和高峰期对业务的影响是不同的,这需要综合考虑。你可以采用以下方法来回答关于高可用性的问题:
- 度量方式的选择:首先介绍两种主要的度量方式,即"几个9"的概念和影响请求量占比的方式,解释它们的优缺点。
- 综合考虑:强调在实际业务中,综合考虑两种度量方式更有利于全面评估高可用性。举例说明在不同时间段停机对业务的不同影响。
- 科学性和实际性:说明使用请求量占比来评估高可用性更科学,因为它更直接地关联到业务损失。然后,结合实际业务场景,展示你的思考和决策,以体现你的实践经验和专业性。
- 闭环思路:提到"可评估"、"可监控"和"可保证"的思路,强调了综合性的方法,不仅仅依赖于理论概念,还需要实际的措施来确保高可用性。
案例解答
我们可以通过设计一个监控系统来保证系统服务SLA达到四个9,这个监控系统可以分为三个核心部分:基础设施监控报警、系统应用监控报警,以及存储服务监控报警。通过这个监控系统的设计,我们可以更好地了解哪些环节对整个系统的可用性产生影响,这将帮助我们在面试中更清晰地展示系统高可用性设计的理念。
基础设施监控
监控报警指标分为两种类型。
系统要素指标:主要有 CPU、内存,和磁盘。
网络要素指标:主要有带宽、网络 I/O、CDN、DNS、安全策略、和负载策略。
为什么我们要监控这些指标?因为它们是判断系统的基础环境是否为高可用的重要核心指标。
 图片
图片
监控工具有一些常见的选择,它们可以帮助你有效地监控系统的性能。这些工具包括:
- ZABBIX:这是一个开源的监控系统,非常流行且具有广泛的资料支持。它可以监控系统的各种关键指标,如CPU使用率、内存、磁盘、网络带宽等。
- Open-Falcon:由小米开源的监控系统,受到小米、滴滴、美团等公司内部的广泛应用。它也可以监控各种基础设施指标。
- Prometheus:这是另一个开源的监控系统,特别擅长支持Kubernetes(K8S)环境的监控。它也可以监控CPU、内存、磁盘、网络等指标。
这些工具提供了丰富的监控功能,可以帮助你监测系统的各个方面,从基础的CPU和内存使用到更高级的K8S监控。此外,你还可以结合运营商提供的监控平台,以覆盖整个基础设施监控的需求。
监控报警策略一般由时间维度、报警级别、阈值设定三部分组成。
 图片
图片
为了帮助你更好地理解监控报警策略,让我用一个例子来说明。假设我们正在监控一个系统的CPU、内存和磁盘使用情况,监测的时间间隔是每分钟,并且我们设置了一些占比的阈值。基于这些条件,我们可以制定以下监控报警策略:
 图片
图片
为了第一时间监测到指标的健康度,报警级别可以分为紧急、重要,以及一般。当 CPU、内存,以及磁盘使用率这三项指标的每分钟采集的指标达到 90% 使用率时,就触发“紧急报警”;达到 80% 触发“重要报警”;70% 触发“一般报警”。
系统应用监控
业务状态监控报警是关注系统自身状态的监控报警,与基础设施监控类似,它也由监控指标、监控工具和报警策略组成。不同之处在于,系统应用监控报警的核心监控指标主要包括以下6个关键指标:流量、耗时、错误、心跳、客户端数和连接数。用于实现这些监控指标的工具包括CAT、SkyWalking、Pinpoint、Zipkin等。
 图片
图片
存储服务监控
一般来讲,常用的第三方存储有 DB、ES、Redis、MQ 等。
在面试中,当回答关于监控和保障系统可用性的问题时,可以结合三个核心监控部分(基础设施监控、系统应用监控、存储服务监控)来阐述你的全局监控视角,强调你的设计思路。例如,你可以这样回答:
"为了确保系统的可用性和稳定性,我设计了一套综合性的监控体系,用于在生产环境中对系统进行全面监控。这包括基础设施、系统应用和存储服务的监控。具体的监控指标和细节可以根据实际业务场景进行定制,比如在游戏领域,我们更关注流量和客户端连接数等关键指标。这种综合性的监控系统有助于我们迅速发现潜在问题并及时采取措施来维护系统的高可用性。"
当面试官进一步追问如何应对线上告警时,你可以回答:
"当面对线上告警时,我会迅速响应,并根据告警的严重性采取相应的措施。首先,我会查看告警的详细信息,分析问题所在,以确定是否是假警报或真实问题。如果是真实问题,我将根据事先设定的报警策略来通知相关团队成员。然后,我们会在团队内部协作,采取紧急措施来解决问题,包括故障排查、系统恢复和监控指标调整等。一旦问题得到解决,我会进行事后分析,以确保我们可以从中吸取教训,以防止未来类似问题的发生。总之,我会尽最大努力确保系统的高可用性,同时确保及时有效地响应和处理告警情况。"
这种回答方式突出了你对全局监控和紧急事件处理的理解,以及你的责任感和应对危机的能力。
对于线上故障,要有应急响应机制,我总结以下几点供你参考:
 图片
图片
总结
- 系统高可用评估:在面试中,我们学习了如何评估系统的高可用性,强调了以停机时间对系统请求量的影响作为科学评估指标。
- 监控系统设计:了解了设计监控系统时的三个核心要点,包括基础设施监控、系统应用监控和存储服务监控。这有助于确保线上服务的稳定运行。
- 故障处理:强调了故障处理是进阶过程中不可或缺的经历,面试官也特别重视这个能力。对于不同类型的故障,建议形成一套体系化的知识框架来处理。
 图片
图片