Ceph提供了块、对象和文件等多种存储形式,实现了统一存储。前文说过,Ceph的对象存储基于RADOS集群。Ceph的文件系统也是基于RADOS集群的,也就是说Cephfs对用户侧呈现的是文件系统,而在其内部则是基于对象来存储的。
CephFS是分布式文件系统,这个分布式从两个方面理解,一个方面是底层存储数据依赖的是RADOS集群;另外一个方面是其架构是CS(客户端-服务端)架构,文件系统的使用是在客户端,客户端与服务端通过网络通信进行数据交互,类似NFS。
 图片
图片
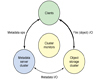
如图所示客户端通过网络的方式连接到Ceph集群,Ceph集群的文件系统映射到客户端,呈现为一个本地的目录树。从用户的角度来看,这个映射是透明的。
当然,对于CephFS集群来说,数据并非以目录树的形式存储的。在CephFS中,数据是以对象的形式存储的,文件的访问最终也会转换为(RADOS)对象的访问。
CephFS集群的安装与使用
CephFS的安装总体比较简单,我们假设现在已经有一个Ceph集群了。基于已有的Ceph集群,通过两个主要步骤就可以提供文件系统服务,一个是启动MDS服务,该服务是文件系统的元数据管理服务;另外一个是创建存储数据的存储池资源。
对于CephFS,需要创建2个存储池来存储数据,一个存储池用于存储元数据,另外一个存储池用于存储数据。创建存储池的步骤如下:
就这么简单,然后就可以使用该文件系统了。以内核态文件系统为例,其挂载方法与其它文件系统很类似。
如果一切正常,那么在客户端就可以使用该分布式文件中的数据了。
CephFS客户端架构
CephFS的客户端有多种实现方式,一种是在Linux内核中客户端实现,还有一种是基于fuse(参考用户态文件系统框架FUSE的介绍及示例)的实现。虽然是两种不同的实现方式,但是没有本质的区别。
客户端对集群的访问分为两个主要的流程,一个是通过MDS访问集群文件系统的元数据,另一个流程是客户端对数据的访问(读写),这个是客户端直接与RADOS集群的交互。
 图片
图片
了解了关于CephFS整体的架构和访问流程,接下来我们介绍一下我们介绍一下客户端的整体架构及关键流程。由于基于FUSE的实现封装了很多细节,整体逻辑还是比较简单的,因此我们暂时不介绍该实现。我们先介绍一下基于内核的CephFS客户端的实现。
CephFS是基于VFS实现的,因此其整体架构与其它Linux文件系统非常像。如图所示,CephFS的位置与Ext4和NFS的关系如图所示。
 图片
图片
CephFS的差异点在于CephFS是基于网络将数据存储在RADOS集群,而不像Ext4一样将数据存储在磁盘上。
 图片
图片
如果按照CephFS的逻辑架构来划分,CephFS可以分为如图所示的几层。其中最上面是接口层,这一层是注册到VFS的函数指针。用户态的读写函数最终会调用到该层的对应函数API。而该层的函数会优先(根据配置情况而定)与缓存交换。
 图片
图片
页缓存是所有文件系统公用的,并非CephFS独享。我们暂且将页缓存归为CephFS客户端的一层。以写数据为例,请求可能将数据写入缓存后就返回了。而缓存数据的刷写并非实时同步的,而是根据适当的时机通过数据读写层的接口将数据发送出去。
然后是数据读写层,数据读写层实现的是对请求数据与后端交互的逻辑。对于传统文件系统来说是对磁盘的读写,对于CephFS来说是通过网络对集群的读写。
消息层位于最下面,消息层主要完成网络数据收发的功能。该模块在Linux内核的网络模块中,不仅仅CephFS使用该模块,块存储RBD也使用该模块网络收发的功能。
CephFS集群架构
传统文件系统是通过磁盘数据块来组织文件系统的,数据分为元数据和数据两种类型。其中元数据是管理数据的数据,比如某个文件数据的位置信息或者文件的大小和创建时间等。而数据则是指文件的实际数据,或者目录中的文件或者子目录信息。
CephFS有些差异,因为其底层是RADOS对象集群,其提供的是一个对象的集合。前面我们创建文件系统的时候也看到了,其实是创建了两个对象存储池。因此,CephFS的数据和元数据其实都是以对象的形式存在的。我们看一下上面实例中创建的文件系统,其实已经有很多对象了(1.0000000为根目录的元数据对象)。
 图片
图片
在客户端的文件系统有一个树型的结构,CephFS组织数据的逻辑形式也是树型结构。为了容纳数据,每个文件系统必然需要一个根目录,CephFS也是有一个根目录的,这个根目录在前面创建文件系统的时候创建。根目录的inode ID是1,这个在前面提示过。
文件存储在目录当中,在CephFS中是以元数据的方式存储的。在CephFS中,目录中的文件是以omap的形式存储的。也就是每个目录会以其inode ID作为名称在元数据存储池创建一个对象,而目录中的文件(子目录)等数据则是以该对象omap的形式存在的,而非对象数据的形式。
 图片
图片
例如,我们在前面创建的文件系统中的根目录创建5个空文件,分别是testa、testb、testc ...等,此时我们可以在根目录的对象中获取omap的所有Key信息。
 图片
图片
这里面的omap是以KV的形式存在的,其中Value对应的为inode信息,如下是testa对应的inode信息,这些信息包括该文件关键的元数据信息,例如inode ID和创建时间等等。
 图片
图片
在Ceph文件系统中,文件的元数据存储在MDS集群中,而数据则是直接与OSD集群交互。以默认配置为了,文件被拆分为4MB大小的对象存储。由于原则确定,当客户端通过MDS创建文件后,客户端可以直接根据请求在文件中逻辑位置确定数据所对应的对象名称。
文件数据对应的对象名称为文件的inode ID与逻辑偏移的的组合,这样可以根据该对象名称实现数据的读写。
 图片
图片
以testa为例,我们在其中写入16MB的数据,此时可以产生4个对象。通过stat查看testa的inode ID为1099511627776(0x10000000000)。查看一下数据存储池中对象列表如下:
 图片
图片
可以看到与该文件相关的对象列表,其前半部分为inode ID,后半部分是文件以4MB为单位的逻辑偏移。
在具体实现层面,Ceph通过如下几个数据结构来表示文件系统中的文件和目录等信息。这些数据结构的关系如图所示。
 图片
图片
可以看到这里主要有三个数据结构来维护文件的目录树关系,分别是CInode、CDentry和CDir。下面我们介绍一下这些数据结构的作用。
CInode数据结构
CInode包含了文件的元数据,这个跟Linux内核的inode类似,每个文件都有一个CInode数据结构对应。该数据结构包含文件大小和拥有者等信息。
CDentry数据结构
CDentry是一个粘合层,它建立了inode与文件名或者目录名之间的关系。一个CDentry可以链接到最多一个CInode。但是一个CInode可以被多个CDentry链接。这是因为链接的存在,同一个文件的多个链接必然名称是不同的,因此需要多个CDentry数据结构。
CDir数据结构
CDir用于目录属性的inode,它用来在目录下建立与CDentry的链接。如果某个目录有分支,那么一个CInode是可以有多个CDir的。
上述类的关系如图所示,其中CDir中存在着一个与CDentry的一对多的关系,表示目录中的文件或者子目录关系。CInode与CDentry则是文件的元数据信息与文件名称的对应关系。
 图片
图片
上述数据结构是内存中的数据结构,除了需要持久化到对象的数据结构,这部分内容本文暂时不做介绍。
今天我们大致的介绍了一下CephFS的整体架构,使用和集群端的架构。