一、溯源——vivo存储服务介绍
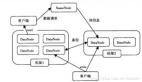
1.产品矩阵
 图片
图片
当前我们的团队主要负责两大板块内容,一是存储和数据库产品矩阵,二是周边工具及接收类服务。
这两部分内容的区别主要是,周边工具和接入类服务几乎是无状态的,用户对这类服务提出可用性的需求,比如我们平时接触到的SLA;而存储及数据库产品等引擎,主要面向对象存储、文件存储、表格存储等专门的服务业务,包括可用性和可靠性的指标。
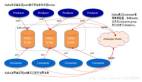
2.存储框架
云存储领域的黄金数字是11个9,接下来就以存储服务为切入点,向大家介绍11个9能否量化?如何量化?
 图片
图片
如上图所示,存储框架的核心思路是以自研的存储引擎为核心,辅以阿里、腾讯等公有云的存储,获得统一的存储底座,在上方形成对应存储的统一网关,进而提供一套混合云的存储系统。然后,存储系统进行协议转换、衍生产品开发,为业务提供存储服务和衍生的生态服务。
比如,我们会利用自己的SDK和AWS S3 SDK,提供原生的对应重组产品,向前封装文件的存储网关,兼容posix协议,为用户提供文件的存储产品。除此之外,还会封装企业网盘,进行专项服务,为用户提供相应的衍生产品。
3.运营数据
当前,基于跨机房的纠删码相关优化,对可靠性提出了挑战。如下图所示,我们线上的集群容量达到400亿(此数据尚未包括Hadoop的数据容量),存储数量已超1,000亿。
 图片
图片
二、归因:存储可靠性原因分析
1.数据丢失影响因素
 图片
图片
数据丢失的五大原因包括:软件故障、数据损坏、恶意窃取、人为失误、硬件故障,其中硬件故障的占比较高。
2.软件故障和数据损坏
 图片
图片
软件故障的主要原因是软件设计不规范、测试不完善及运维发布的操作爆炸半径太高。
这些问题的通用解决方案是:
- 设计标准规范化,比如,AWS引入了TLA+、Plusal等形式化规范语言来设计系统;
- 要达到测试自动化;
- 做好版本向前版本兼容、版本回滚、读写分离等操作。
数据损坏的行业通用解决方案相对成熟,因为在处理传输与存储的过程中,都有一定概率遇到数据损坏的问题。
解决方案:
- 通过HTTPS协议,保证传输的安全;
- 然后通过MD5校验,记录交易数据的完整性;
- 最后通过定期的scrubbing处理机制,快速扫描是否具有静默错误。
3.恶意窃取和人为失误
 图片
图片
人为失误主要包括两类问题,第一类是运维人员操作失误,第二类是用户自己的误杀或误覆盖。
- 针对运维的解决方案:运维自动化、运维白屏化、遵循POLP的最小权限原则。
- 针对用户的解决方案:自动存储方面,可以利用多版本的特性,保证用户可以找回误删的这种数据;文件方面,提供回收站功能可以达到相同效果。
恶意窃取主要是内外部人员相关窃取或删除数据,其解决方案包括:
- 进行权限控制和生命周期管控;
- 可以锁定对象粒度为只读模式;
- 针对删除操作,可以提供这种多因素的、健全的双因子论证,管控删除操作。
4.硬件故障
硬件故障是需要重点关注的存储可靠性原因,因为它占比较高,样本量比较大,所以有一定概率进行量化。
1)原因
- 硬盘故障:最常见最重要的,驱动器、磁头、温度、机械臂故障
- 主机故障:服务器各部件故障导致服务器无法启动
- 机柜故障:由于电源、温度、网络等原因导致整机柜服务器停机
- 机房故障:整个机房由于自然灾害或供电原因瘫痪
- AZ故障:同一地理区域独立电力和网络的机房故障
- Region故障:不同地理区域的一个Region故障
2)硬件故障的解决方案
- 数据冗余技术【RAID5/6、副本、纠删码】
- 多AZ数据冗余部署【vivo 3 AZ 部署】
- 跨区域复制功能【功能具备,vivo还没多地域机房】
- 故障预测+故障发现+故障修复
如果我们只按照传统方式,增加K,减少M,修复带宽就会非常高。并且,多AZ之间的修复带宽本身成本较高,所以给可靠性带来了很大压力。因此,我们设计了一个低冗余度、支持多AZ部署、且修复带宽较少的纠删码优化方案。
 图片
图片
上方右图来自2021年亚马逊AWS S3关于可靠性保障的演讲,这幅图提供了两个重要的信息。
- 第一个信息:11个9是通过可靠性模型量化得到的,它与磁盘的故障率、故障发现的时间和消费时长是强相关的。
- 第二个信息:可靠性评估模型,用于指导线上环境的修复策略,以及指导跨AZ纠删码技术存储系统的设计。
三、建模:存储可靠性量化模型
1.11个9的由来
11个9是亚马逊在2006年提出的可靠性标准,所有云存储提供商都像军备竞赛一样,声称自己能提供多少个9,但行业内几乎没有任何一家云厂商能提供权威的量化模型。
这11个9如何量化?
 图片
图片
亚马逊的官方文档提供了两种定义:
- 第一个定义是,存储一千万个对象预期平均每1万年发生一个对象丢失。这个定义很好理解,但它实际上并不好量化;
- 第二个定义是,平均每年对象的丢失率预计为0.000000001%。这个定义具体到每年的对象丢失率,进入到统计学概率的层面,为量化提供可能。
回顾那张AWS演讲里的图,它引入了两个比较重要的参考指标:硬件的平均故障时间、故障的平均修复时长,对应到年平均指标的层面上,就是年平均故障率和年平均修复率。
2.可靠性模型影响因素
接下来,介绍建立模型的具体影响因素。如下图所示,如果第一个磁盘爆炸,后面磁盘的数据需要对它进行修复,这个过程可能涉及到修复带宽,所以修复带宽的大小一定会对可靠性产生影响。这个磁盘本身的数据量、系统节点数目也影响了修复时间,这三个指标实际上影响了修复率的值。
 图片
图片
副本的数量、磁盘故障率对可靠性也是有影响的,这比较好理解,如何理解数据分布系数对可靠性的影响?
如上图左下角所示,备份有两种数据分布方式。在第一种备份的数据分布状况下,如果第一个磁盘挂了,只能依靠第二个磁盘进行修复,即只有一个盘进行修复,所以速度较慢。
第二种备份将数据分块打散,其他三个磁盘都存储一部分数据。第一个磁盘挂掉后,就有多个磁盘并行修复,速度会更快。
这是不是说明第二种备份方式就是最好的?也不一定。因为第一种备份虽然修复速度慢,但正好修复了挂掉的数据。用第二种备份方式,修复的数据可能不是挂掉的数据,实际存在数据丢失情况,因此,数据分布系数对可靠性也有影响。
3.MTTDL可靠性模型
 图片
图片
以下介绍几个重要的存储可靠性量化模型。第一个是MTTDL(平均系统数据丢失时间),它和磁盘的MTTF的区别在于,MTTDL用于衡量系统平均数据丢失时间。
MTTDL模型在1994年被提出,1.0版本基于Markov链推导而来,上图列出了一个简化版的计算公式。相对于1.0版本,最近几年出现的MTTDL的2.0版本,引入了刚才讲到的数据分布系数。
MTTDL有几个缺点:第一个缺点是,它基于Markov链的方式;第二个缺点是,基于当前整个系统的故障平均时间,它是服从指数分布的。
另外,前期的MTTDL模型没有考虑扇区错误,所以近期的MTTDL优化版本屏蔽了Markov链的劣势,不使用这种方式建模;将指数分布优化成,故障率可以动态调整的Weibull分布;考虑独立扇区、相关性扇区的错误;考虑修复时长等NORMAL指标。
MTTDL模型对不同系统设计的可靠性进行优劣评估,起到了非常大的作用。
4.EAFDL可靠性模型
 图片
图片
MTTDL的定义是,平均系统的丢失数据的时长。它有两个特点:第一,MTTDL越高,丢数据频率越低;第二,它只关注丢失的频率,不关注每次丢失数据的数量。
EAFDL的定义是,预期每年数据的丢失比例。EAFDL的定义更接近11个9的定义,因为11个9的定义是平均每年对象的丢失率,所以EAFDL会比MTTDL会更贴近11个9的计算。
EAFDL的计算公式如上图,它在MTTDL的基础上,引入了丢失的平均数据量,它在mtdl的基础之上,引入了丢失平均数据量在用户总数的占比。
但在真实的场景下,EAFDL模型不一定会比MTTDL模型更好。
例如,Facebook曾经公开了一篇论文,讲到在大规模idc部署的情况之下,他们更倾向于控制丢失的频率,而非丢失事件的数据量。因为每次因为丢失事件都会产生固定成本,而固定成本的影响较大。所以真实情况下,EAFDL模型不能完全替代MTTDL模型。
如果侧重丢失的频率,那么在平时系统设计时,可以不断提高MTTDL。如果大家设计的MTTDL都差不多,下一步才会考虑是否应该让EAFDL最小化。
如果侧重丢失的数量,在系统测试时,可以不断让EAFDL最小化,同时让MTTDL最大化。
四、实践:存储可靠性评估实践
1.vivo可靠性建模思路
 图片
图片
我们的建模思路对上述模型进行取舍,取的是什么?我们将MTTDL的频率维度、EAFDL的丢失量维度和数据分布系数,纳入到建模思路。
舍的是什么?我们屏蔽了MTTDL的指数分布、扇区错误的建模,舍去了Markov链的建模。
2.vivo可靠型模型
 图片
图片
上图是整体建模的参数引入,和之前的参数是类似的。
区别在于,平时磁盘硬件厂商对外报AFR参数有两个指标:一个是MTBF,一个是AFR,我们将AFR引入到建模。同时,我们也参照了一家云端厂商Backblaze的公开模型介绍,他们利用泊松分布,模拟年度硬盘故障数量的分布。基于这两个角色,我们制作了副本和纠删码的可靠性模型。
 图片
图片
建模同时,我们也使用了EAFDL的模型,并引入了丢失的数据量在整个用户数据量的占比。
上图右下角的表格,是我们基于副本模式进行的实验数据。实验目的主要是,充分验证不同建模参数对可靠性的影响,进而得出结论。部分结论可以从原理层面推断,比如,AFR越小,可靠性越高;存储利用率低,可靠性越高;修复带宽越高,可靠性越高;副本和检验位数越高,可靠性越高。
但是,机器数量越多,它的可靠性不一定越高;数据分布因子越大,可靠性会降低,需要我们在整个系统中进行权衡。
3.可靠性评估平台化建设
 图片
图片
评估平台的建设基于两个原则:第一,需要评估新老方案的可靠性优劣;第二,需要近实时地评估线上系统可靠性的风险。
五、思考:存储可靠性评估思考
1.方向思考
 图片
图片
我们有两个呼吁:
- 共享数据:现在各大提供分布式存储的厂商之所以没公开相关可靠性计算模型,是因为统计样本数据不足。如果全行业能够分享各自的部分统计数据,样本量足够大,就有希望建设最真实的评估模型。
- 统一标准:云存储领域相关的牵头企业,基于公司内部的海量样本数据,能够分享一个比较权威的考勤评估模型,为业界提供指引。
IliasIliadis的论文非常有价值,他从2000年左右开始,在CTRQ发表众多关于云存储系统的可靠性模型研究。大家如果感兴趣,可以搜索看看。
2.未来规划
未来,我们可能会引入扇区错误因素,重新建模。
当前没有引入扇区错误,是因为目前业界提供的均值指标,权威性还有待考证。扇区错误是磁盘里比较常见的错误,不一定是独立的,可能具有相关性。所以后续等相应指标的真实性足够后,我们会考虑进行重新监管。
- 软件故障:自动化测试框架
- 数据损坏:自适应Data-scrubbing
- 恶意窃取:MFA-Delete特性
- 人为失误:运维自动化率进一步提升、遵循POLP
- 硬件故障:进一步提升故障预测+故障检测+故障修复能力,进一步设计纠删码方案使得可靠性+成本兼顾
Q&A
Q1:您觉得提升可靠性的工作中,近期哪一部分改进的影响最大?
A1:近期我们建立了可靠性模型,为什么要建模?因为我们目前在进行纠删码的相关优化,如果纠删码的冗余度偏低,就无法保证可靠性,所以我们建立了一套模型去评估。
当然这个模型本身的量级不一定能达到11个9,但相对于线上这套系统,它可以看出好还是坏。建立这个模型,方便我们后续算法优化时进行参考。如果你的算法比较极端,比如下降的量级比较大,可能就要推翻算法,重新设计。
作者介绍
龚兵,vivo云存储研发负责人。工作10余年,先后就职于华为、腾讯、百度,现在vivo担任云存储研发负责人,研究方向:对象存储、文件存储、NOSQL存储等分布式存储领域。