














大家好,我卡颂。
在 2 年前的React Conf 2021[1],黄玄第一次介绍了React Forget,这是个「可以生成等效于 useMemo、React.memo」的编译器(可以简单理解为,有了它,开发者不需要考虑React项目的性能优化了)。
由于React独特的架构(全局更新),「React 性能优化」一直让开发者头疼,这里主要有两个问题:
- 很多开发者不知道如何正确使用性能优化API,甚至有人认为FC(函数组件)中所有函数都应该包裹在useCallback中
- 即使写出性能优秀的项目,随着需求迭代,新增的代码很可能破坏之前的优化效果
所以,React Forget的愿景一经宣传,就受到社区极大的关注。从React Conf 2021油管播放量来看,React Forget演讲占了所有 19 个演讲总播放量的 1/4(当然,也可能是因为黄玄长得帅)。

现在2年过去了,我们很少听到React Forget的进展,黄玄也离开「React 团队」了。这让我们不禁要问,React Forget凉了么?
本文会聊聊React Forget当前的进展、接下来的发展方向,以及他的工作原理。
React Forget 凉了么?
首先要明确的是,React Forget并没有凉,相反,他正在稳定迭代。
根据React团队成员「Mofei Zhang」在React Advanced London 2023[2]的演讲指出,「React 团队」出品的所有产品,都会经历 5 个阶段:
- 理念验证
- 产品实现
- Meta内部挑选业务线,小范围使用
- 推广到Meta其他业务线
- 发布开源版本
当前React Forget正处在阶段 3,已经在下述两个产品的生产环境投入使用:
- quest store[3],Meta旗下VR产品的应用商店,基于React Native开发。
- instagram[4],web项目,基于React DOM开发。
效果如何呢?以quest store举例。下图是quest store的产品详情页(由React Native实现):
quest store产品详情页
可以看到,这是个左右布局的项目,点击左侧Tab右边会有相应变化。
下图是使用React Forget前,通过React Profiler测量的「点击左侧 Tab 触发更新」后的更新火炬图,其中:
- 每个小块代表一个组件。
- 绿色小块代表「触发本次更新后,会 render 的组件」。
- 灰色小块代表「触发本次更新后,不会 render 的组件」(命中性能优化)。

显然,当触发更新后,灰色小块越多,项目性能越好。
当项目经过React Forget编译优化后,执行同样操作的更新火炬图如下(其中红框内是优化的部分。也就是说,经过优化后,触发同样的操作,红框内的组件都不会render了):

这个优化效果有多好呢?数值如下:
- 「切换 Tab 操作」的响应速度提高 150%
- 页面加载速度提高 4-12%
这里需要指出的是,经由React Forget生成的优化代码等效于useMemo、React.memo这样的「缓存 API」,而这些API主要是减少rerender过程中render的组件数量。
虽然「页面加载」主要是首屏渲染(mount),此时这些缓存API发挥不了作用。但要完成页面加载,很多组件是需要rerender的。举个例子,对于列表的渲染,包括两个步骤:
- 首屏渲染(mount),渲染空列表
- 获取到数据后,渲染(rerender)包含数据的列表
所以,React Forget通过提高rerender速度,提高了页面加载速度。
有同学可能会质疑 —— 是这个项目本身做的优化太少了,才显得优化效果好吧?
首先,我们可以从优化前的火炬图的灰色部分(下图绿框内)看出,项目是经过性能优化的(否则应该都是绿色小块):

但是,一个精心优化过性能的React项目,就像扑克搭的城堡,任何风吹草动都能让优化效果付之东流:
举个例子,假设项目中有个很耗性能的组件ExpensiveCpn:
<ExpensiveCpn data={data}/>你将ExpensiveCpn用React.memo包裹,将data用useMemo包裹,使得ExpensiveCpn非必要不render。
但是,团队其他成员接到需求,要给ExpensiveCpn增加个新props:
<ExpensiveCpn data={data} items={items}/>由于新加的items props没有用useMemo包裹,使得你的优化失去效果(在复杂项目中,这种情况很常见)。
这就造成个悖论 —— 越是访问量大、迭代频繁、性能敏感的React项目,越难维持优秀的性能。
从这个角度看,React Forget意义重大。
为什么迭代这么慢?
既然React Forget这么重要,为什么这两年都没啥消息呢?因为JS作为动态语言语法太灵活,这极大增加了编译器的开发难度。
根据从Chrome跳槽到「React 团队」的工程师「Sathya Gunasekaran」在React India 2023[5]演讲中表示:在React Forget中实现Alias Analysis(别名分析)的难度,比在Chrome V8中还高。
好在React作为一种DSL,相比纯JS实现的项目多了很多约束,使得静态分析成为可能,比如:
React组件类似于纯函数,这意味着相同的输入(props)会获得相同的输出(JSX返回值)。
这使得每个组件都是一个可以独立静态分析的模块(不需要考虑组件之间互相影响)。同时,React Forget也能并行分析多个组件。
FC(函数组件)的大规模使用。
Class Component中所有属性、方法都绑定在this中,比如:
- this.state
- this.setState
开发者也能在this上挂载属性,这种灵活性为静态分析带来很大难度。
随着Hooks普及,新的React项目基本都基于FC实现,排除了this的影响。
Hooks。
「在 FC 中,以 use 开头的函数都是 hook」,这条规定为静态分析提供了线索,比如:
- 考虑副作用时,需要分析useEffect等
- 考虑状态时,需要分析useState等
Immutable state(不可变状态)。
状态不可变,意味着编译器不需要考虑下面这种情况:
function App() {
const [num, update] = useState(0);
num = 2;
// ...
}工作原理
需要明确一点,React Forget可以生成等效于useMemo、React.memo的代码,并不意味着编译后的代码会出现上述API,而是会出现「效果等效于上述 API」的辅助代码。
举个例子,考虑下面的代码。VideoTab组件会根据filter过滤出videos数组中「符合条件的 video」,并渲染头组件(Heading)与列表组件(VideoList):
function VideoTab({heading, videos, filter}) {
const filterdList = [];
for (const video of videos) {
if (applyFilter(video, filter)) {
filterdList.push(video);
}
}
if (filterdList.length === 0) {
return <NoVideos />;
}
return (
<>
<Heading
heading={heading}
count={filterdList.length}
/>
<VideoList videos={filterdList} />
</>
)
}其中VideoList组件已经被React.memo包裹:
const VideoList = React.memo(/* 省略 */)当前,虽然VideoList组件不依赖heading props,但是heading props变化也会导致VideoTab组件render(因为每次render时都会生成新的filterdList)。为了优化他,可以用useMemo包裹filterdList:
const filterdList = useMemo(() => {
/* 省略 */
}, [videos, filter])只有当videos props或filter props变化时filterdList才会变化,就排除了heading props变化对VideoList组件的影响。
上述优化是开发者手动性能优化时会写出的代码。
如果交给React Forget,他会生成类似如下代码。其中:
- 缓存被保存在名为useMemoCache的原生hook中。
- if else起到了等效useMemo的作用。
function VideoTab({heading, videos, filter}) {
const $ = useMemoCache(12);
let filterdList;
// 下面的if else起到了useMemo的效果
if ($[0] !== videos || $[1] !== filter) {
filterdList = [];
for (const video of videos) {
if (applyFilter(video, filter)) {
filterdList.push(video);
}
}
$[0] = videos;
$[1] = filter;
$[2] = filterdList;
} else {
filterdList = $[2];
}
// ...省略
}为什么不直接生成useMemo代码呢?主要有两个原因:
对于一个FC,大部分原生Hook的数据会保存在一条单向链表中(这也是「不能在条件语句中写 Hooks」的原因),会占用更多内存。
在React Forget生成的代码中,缓存保存在useMemoCache中,通过观察useMemoCache 的源码[6]可以发现,在useMemoCache内部,并不依赖单向链表保存数据。
这也意味着useMemoCache可以不遵守「不能在条件语句中写 Hooks」这条规定。
useMemo内部需要对依赖项进行浅比较。
相比于浅比较,React Forget生成的if语句能直接被「JS 引擎」优化,更高效。
虽然React Forget的工作原理看似简单,但考虑到大量的边界情况,实际实现起来会很复杂。
举个例子,考虑下面的代码:
function Parent({a, b}) {
const x = [];
x.push(a);
return <Child x={x} />;
}要优化上述代码很简单,优化结果如下(这里用「性能优化 API」演示优化效果,方便理解意思):
function Parent({a, b}) {
const x = useMemo(() => {
const x = [];
x.push(a);
return x;
}, [a])
return <Child x={x} />;
}现在,我们新增两行代码:
function Parent({a, b}) {
const x = [];
x.push(a);
// 下面两行是新增代码
const y = x;
y.push(b);
return <Child x={x} />;
}按照优化逻辑,下面是优化后的代码:
function Parent({a, b}) {
const x = useMemo(() => {
const x = [];
x.push(a);
return x;
}, [a])
const y = useMemo(() => {
const y = x;
y.push(b);
return y;
}, [x, b])
return <Child x={x} />;
}现在问题来了,优化前后的代码逻辑相同么?你可以仔细观察下。
答案是 —— 不相同。
优化后,在首次render时,x、y都会指向数组[a, b],如下图:
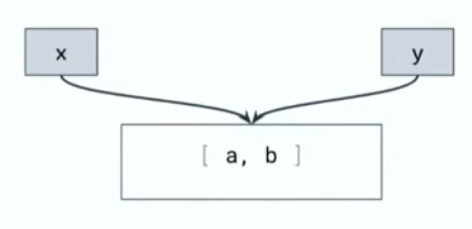
假设b发生变化,触发新的更新,由于x依赖a,所以x不变,仍为[a, b]。
而y依赖了b,所以y变化,render后x、y的指向如下:
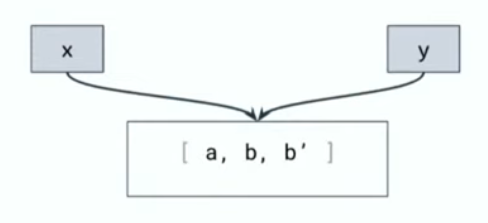
按照优化前的逻辑,结果应该如下:
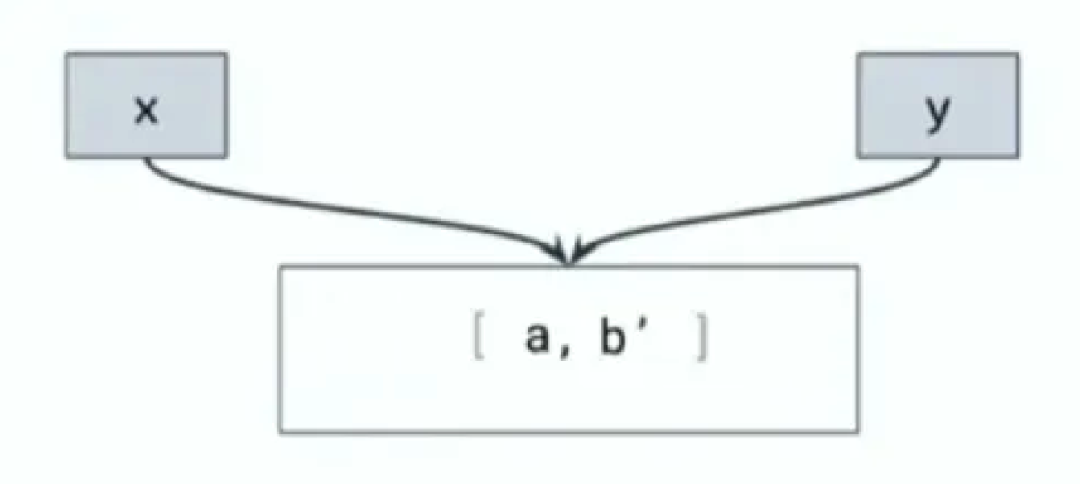
类似这样的边界情况还很多。为了保证编译后的逻辑和编译前相同,「React 团队」为React Forget写了 500 多个用例。
总结
React Forget当前仍处在Meta内部少数业务线的验证阶段,接下来会在公司内部更多业务线铺开。当完成上述流程后,会向社区开放。
你觉得React Forget前景怎么样?欢迎评论区讨论。
这里插个好玩的事儿,在React Advanced London演讲现场有观众提问:既然React Forget是用来缓存数据的,为啥不叫React Remember?
我以为演讲者会说:项目初衷是为了让开发者忘记(forget)写性能优化API。
结果他说:因为团队有个惯例 —— 用F words命名项目,Remember显然不是F开头的。
WTF?????
参考资料
[1]React Conf 2021:https://www.youtube.com/watch?v=lGEMwh32soc。
[2]React Advanced London 2023:https://www.youtube.com/watch?v=hn_L56ypX1A。
[3]quest store:https://www.meta.com/experiences/。
[4]instagram:instagram.com。
[5]React India 2023:https://www.youtube.com/watch?v=JuedZFbhyL0&t=1522s。
[6]useMemoCache 的源码:https://github.com/facebook/react/blob/main/packages/react-reconciler/src/ReactFiberHooks.js#L1112-L1169。

















