












一、Go:它是什么?
除非你一直生活在石头下,否则你可能已经听说过 Golang。Golang 或 Go 是 Google 在21世纪初开发的一种编程语言。其最有趣的特性之一是它通过使用 goroutines 来支持并发,这些 goroutines 就像轻量级的线程。Goroutines 比实际的线程要便宜得多,甚至每秒可以调度数百万的 goroutines。
但 Go 是如何实现这一令人难以置信的壮举的呢?它是如何提供这种能力的?让我们看看 Golang 调度器在背后是如何工作的。

二、前提条件
在我们深入探讨之前,有一些前提条件我必须谈论。如果你已经对它们非常熟悉,可以跳过它们。
1.系统调用
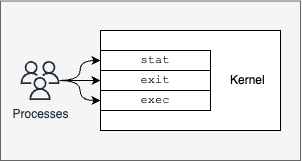
系统调用是向内核的接口。就像 web 服务为用户暴露一个 REST API 接口一样。
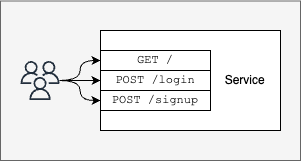
系统调用为 Linux 内核提供了一个接口。
为了更多地了解这些系统调用,让我们写一点代码!你可能首先问的问题是,选择哪种语言?
答案有点复杂,但让我们先了解如何在 C 语言中做,然后再花一些时间思考如何在其他语言中执行相同的操作。
现在,让我们尝试 stat 系统调用。该调用非常简单。它接受一个文件路径并返回有关该文件的大量信息。现在,我们将打印返回的几个值,即文件的所有者和文件的大小(以字节为单位)。
#include<stdio.h>
#include<sys/stat.h>
int main()
{
//pointer to stat struct
struct stat sfile;
//stat system call
stat("myfile", &sfile); //accessing some data returned from stat
printf("uid = %o\nfileszie = %lld\n", sfile.st_uid, sfile.st_size); return 0;
}输出是相当容易预测的,如下所示:
uid = 765
filesize = 11所有的语言在内部都调用相同的系统调用,因为你只能使用这些系统调用与内核进行交互。例如,看一些 NodeJS 代码这里,你可以看到它是如何声明文件路径的。他们围绕这些系统调用做了很多工作,为开发者提供了更简单的接口,但在底层,它们使用内核提供的相同的系统调用。
2.线程
我相信大多数人在生活中某个时候都听说过线程,但你真的知道它们是什么吗?它们是如何工作的?
我会尽快为你解释。
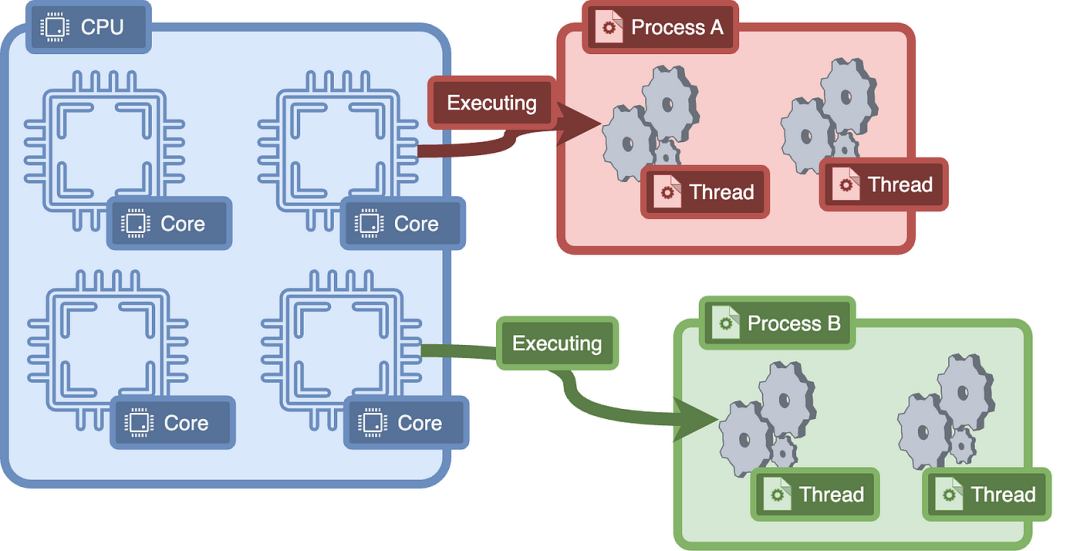
你可能已经读到过有多个核心的处理器。这些核心中的每一个都像一个可以独立工作的独立处理单元。
线程是基于这一点的抽象,我们可以在我们的程序中“创建”线程,并在每个线程上运行代码,然后由内核调度在单个核心上运行。
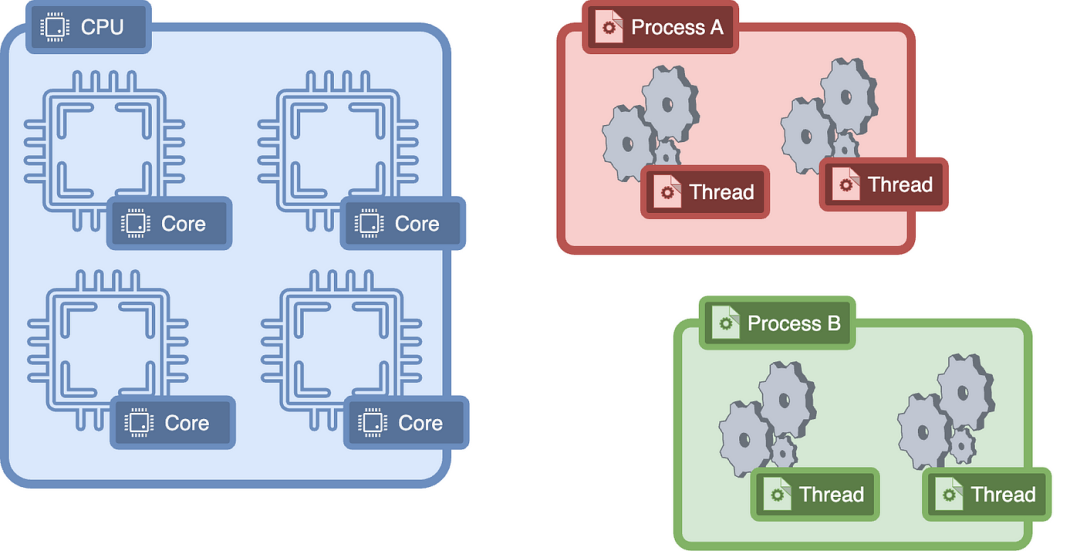
所以,在任何时候,单个核心都在运行一个执行线程。
我们如何创建线程?通过系统调用!
那为什么不直接使用核心呢?为什么我们不直接写new Core()而是通过new Thread()创建线程?因为在操作系统中可能有多个程序正在运行,每个程序可能都想并行执行代码。由于核心数量有限,每个程序都必须知道有多少可用的核心,如果一个程序占用了所有的核心,它基本上可以完全阻塞操作系统。操作系统可能还需要执行比任何单个程序更重要或优先级更高的工作,所以需要一层抽象。
3.Goroutines
正如我上面解释的,goroutines类似于轻量级的线程,它们可以并发运行并且可以在单独的线程中运行。
在继续之前,没有真正需要了解Golang,但我认为至少在继续之前,看一下一个非常简单的goroutine的实现是有意义的。
package main
import (
"fmt"
"sync"
"time"
)
func printForever(s string) {
// This is an infinite loop that prints the string s forever
for {
fmt.Println(s)
time.Sleep(time.Millisecond)
}
}
func main() {
var wg sync.WaitGroup
// A waitgroup is just a way to wait for goroutines to finish
wg.Add(2)
// Any function executed with the "go" keyword will run as a goroutine
go printForever("HELLO")
go printForever("WORLD")
// This line of code blocks until both goroutines are finished
wg.Wait()
}输出,你可能猜到了,是连续打印的单词“HELLO”和“WORLD”。
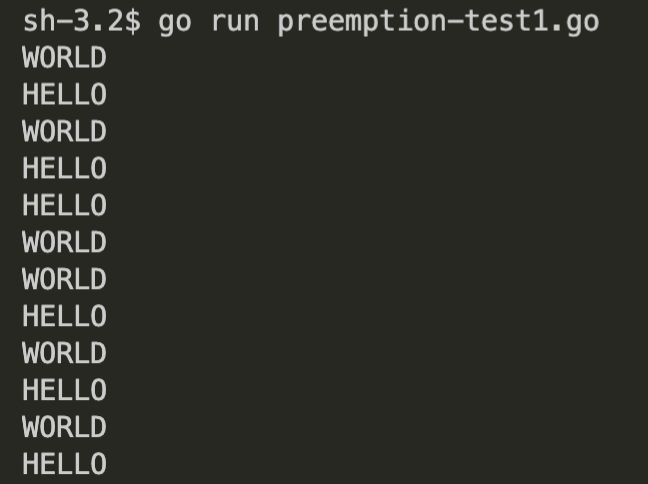
既然用go关键字标记的两个函数调用都是并行运行的。
你的直觉可能会让你认为这些 goroutines 只是并行运行在 CPU 上的单独线程,并由操作系统管理,但这不是真的。尽管现在每次调用都可以是单个线程,但我们很快会发现这并不实际。
三、设计我们自己的调度器
让我们讨论 Go 调度器,就好像我们正在创建自己的调度器一样。我知道这个任务可能看起来很艰巨,但本质上,我们有一些工作单元,比如说一些函数,我们需要将它们调度到有限的线程上。
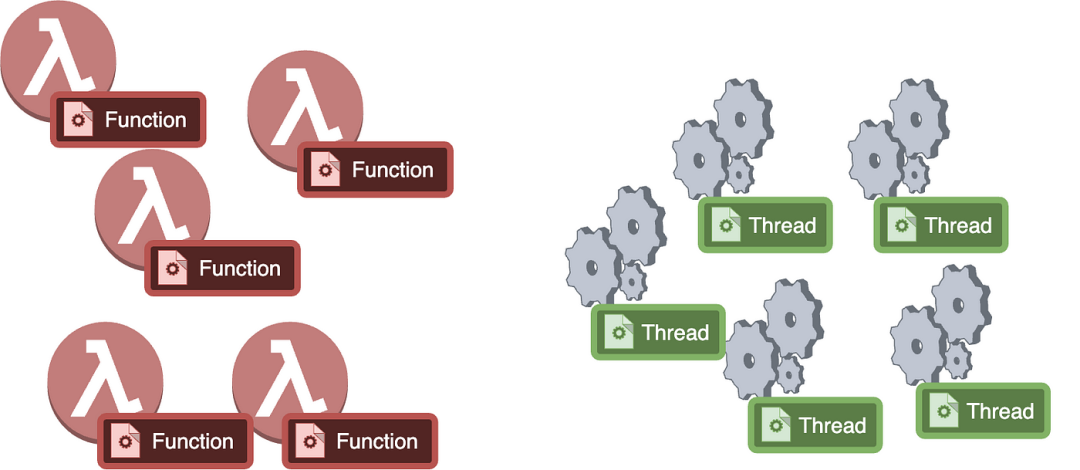
所以,为了更正式地描述这一点,函数是单一的工作单位。它是执行某些处理的代码行的序列。现在,让我们不要用像 async/await 这样的东西来混淆自己,我们说一个函数只包含非常基本的代码。也许像这样,
int add(int a, int b) {
int sum = a + b;
cout << "Calculated the sum: " << sum;
return sum;
}它应该在线程上运行,这些线程在内部在处理器的核心上进行多路复用。核心是有限的,但线程可以是无限的。管理这些线程并在有限的CPU核心上运行它们是操作系统调度器的工作,所以我们不需要关心核心。我们可以简单地将线程视为实现并行性的单位。
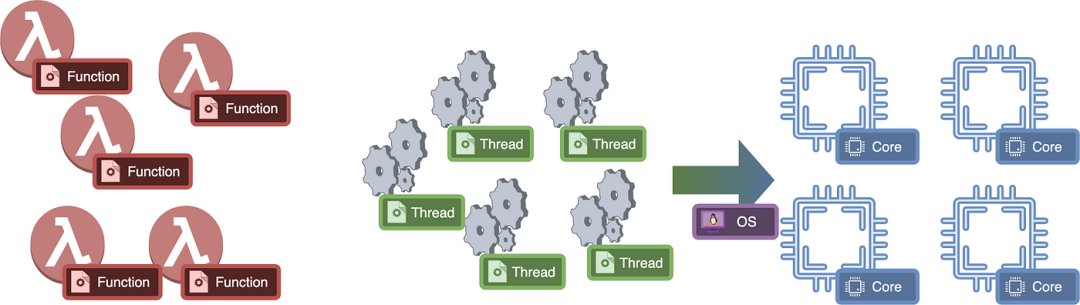
我们确实有一套系统调用,我们可以运行它们在操作系统上创建线程。系统调用往往是昂贵的,所以我们需要确保我们不经常创建/删除线程。
我们调度器的工作很简单,将这些函数或 goroutines 运行在线程上。我们的调度器可以在任何时候被赋予新的函数/goroutines,它将必须在线程上调度它们。
在下一部分,让我们继续明确所有的需求。
需求
让我们列出我们调度器中想要的一些优先事项,这与 Golang 所设置的优先级相似,这些将影响我们在设计调度器时所做的设计决策。
(1) 轻量级 goroutines
我们希望我们的 goroutines 非常轻量级。我们希望能够处理每秒调度的数百万 goroutines。这意味着我们想要做的所有事情,如创建一个 goroutine 或在线程上切换一个 goroutine 必须非常快。
(2) 处理系统调用和 I/O
系统调用可能难以处理,但我们仍然希望为我们的函数提供能够进行系统调用和执行 I/O 操作的能力。这意味着某个函数可以打开并读取一个文件,例如。系统调用有点棘手,因为一旦开始了系统调用,我们就看不到它何时结束或需要多长时间。在某种意义上,我们不能再控制或透明地看到函数了。当我们开始设计我们的调度器时,这个问题会出现。
(3) 并行
我们当然希望同时运行多个 goroutines。记住,我们不需要担心核心,我们只需考虑如何将这些函数多路复用到线程上。
(4) 公平
我们希望一个系统确保运行在其中的 goroutines 是公平的。这意味着一个 goroutine 不应该阻塞其他 goroutines 很长时间。公平可能有点难以客观定义,但其思路是每个 goroutine 都应该在线程上获得公平的执行时间。这似乎是合乎逻辑的,因为没有定义某种优先级系统的要求,没有理由给予任何这些函数优先权。
(5) 避免过度订阅
重要的是要控制任何程序将使用的线程数。当确保我们不会无谓地获取操作系统级别的线程并阻塞机器上运行的其他进程时,这可能会很有用。因此,我们应该尝试限制我们使用的线程数量。如果我们超出这个限制,我们将过度订阅,为了对系统上运行的其他进程公平,我们会认为这是一件很糟糕的事情,并尽量避免它。
四、第1部分:调度 Goroutines
1.1:1 映射
一个非常简单的系统是我们为每个 goroutine 创建一个线程。这意味着我们在 goroutines 和线程之间有一个1:1的映射。
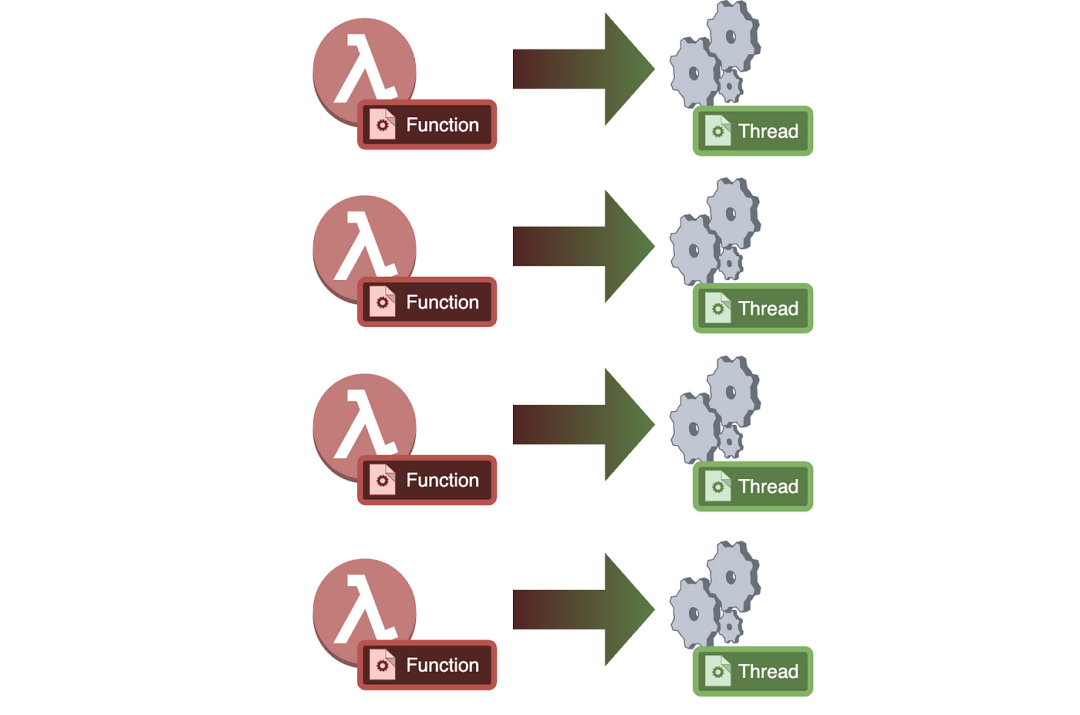
因此,每当用户尝试创建一个 goroutine,我们的调度器创建一个线程,该线程开始执行 goroutine。
这导致了很多问题:
- 我们的 goroutines 不再轻量级,创建一个线程需要一个系统调用,这可能需要任意的时间。而且,一个线程有它自己的堆栈、寄存器和其他变量。如果你想运行几十个线程,这是可以的,但当你想每秒运行数百万 goroutines 时,这是不切实际的。
- 如果我们为每个 goroutine 创建一个线程,而我们的用户可以创建他们想要的任何数量的 goroutines,那么我们就过度订阅了操作系统资源。我们希望能够控制我们使用的操作系统线程的数量。
2.M:N 映射
这里的逻辑步骤是使用 M:N 映射。这意味着M个 goroutines 需要映射到N个线程。因此,用户可以创建他们想要的任意数量的 goroutines,但我们对一组有限的线程有控制权,并且我们将他们的 goroutines 调度到一个线程上一段时间。我们也可以暂停/恢复线程上运行的 goroutines。
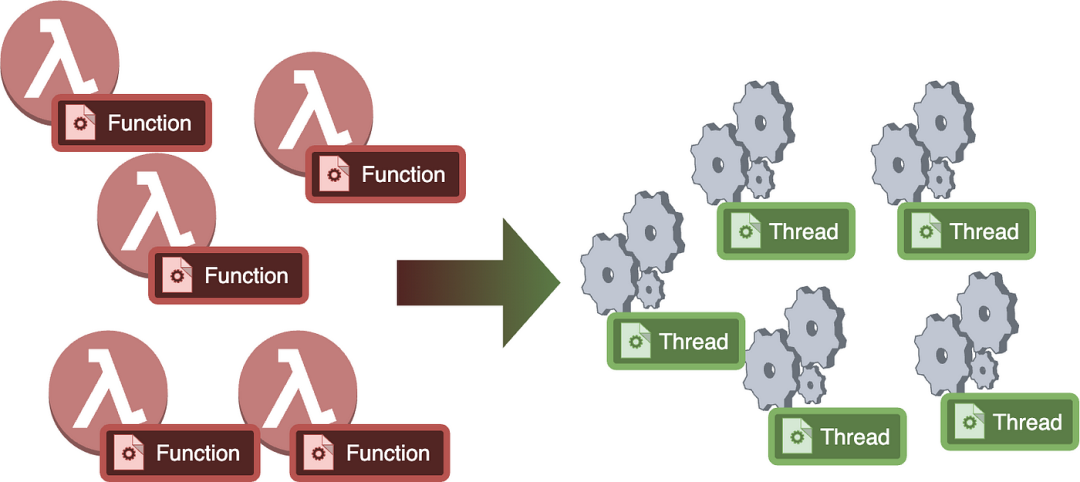
这样做有点复杂,因为我们现在需要了解如何将一个 goroutine/function 映射到一个线程上。我们可能只在每个线程上运行一个函数很短的时间,所以我们需要做一些繁重的工作以确保我们得到正确的逻辑。
一个好的比喻可能是餐馆。餐厅通常会有不同数量的侍者和厨师。侍者的数量取决于餐厅的客人或桌子的数量,而厨师的数量取决于订单的数量和烹饪所需的时间。
在这个比喻中,我们可以把函数想象成侍者,线程想象成厨师。
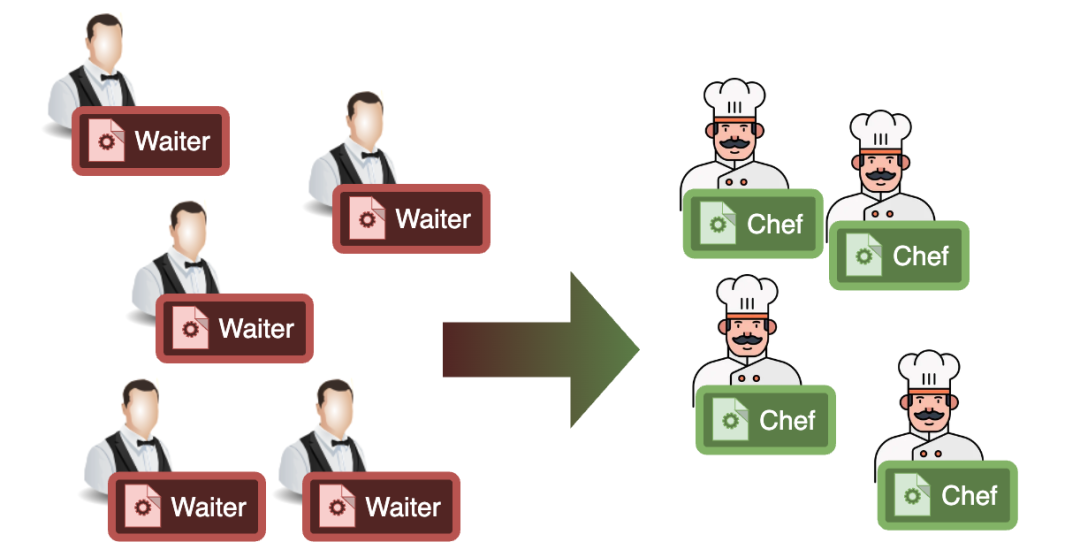
为每个侍者提供一个厨师并不真正有意义,因为也许一个厨师可以很快地烹饪食物,也许餐厅在高峰时间有很多客人,但在慢时,也许需要更少的侍者。所以为了正确管理这家餐厅,你需要某种系统来将M个侍者分配给N个厨师。这正是我们必须在调度器中做的事情!
为了进一步延续这个比喻,也许一个简单的系统是有一个订单队列,每个订单都有一个数字,厨师们一个接一个地选择数字。这也将是我们调度器的起点!
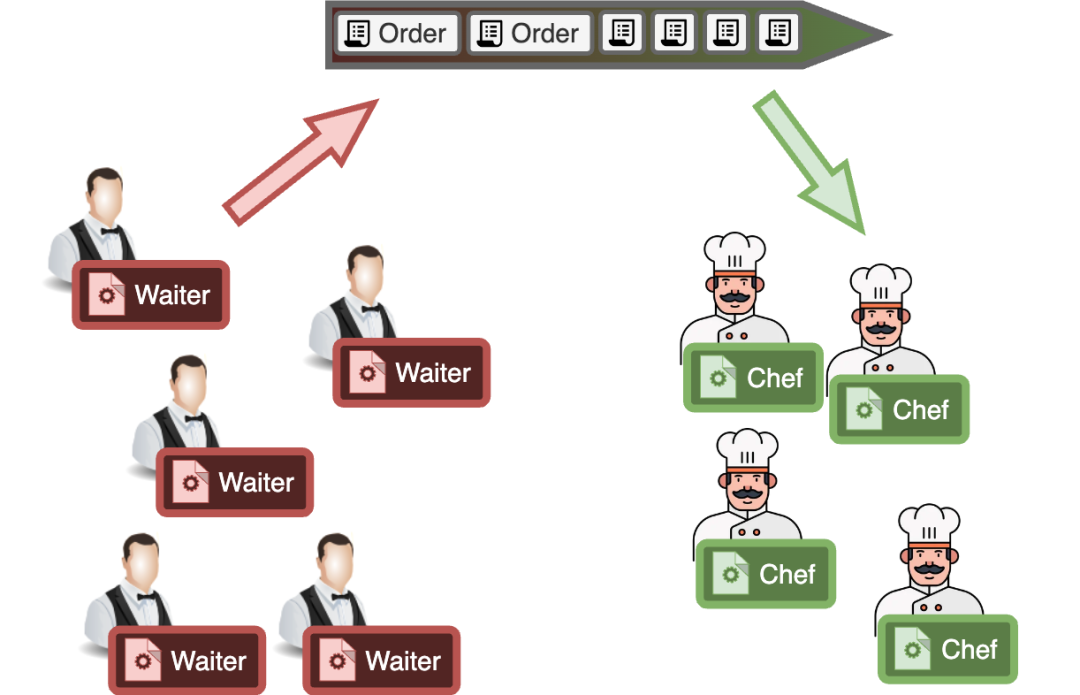
3.一个基本的系统 — 全局运行队列
让我们首先设计一个基本的系统,并对其进行迭代。
我们设置一个全局的先入先出的运行队列,其中包含需要运行的一组 goroutines。每个线程从这个队列中选择一个 goroutine 并执行它。当它执行完一个 goroutine 后,它再次选择一个新的 goroutine 并继续反复进行相同的过程。
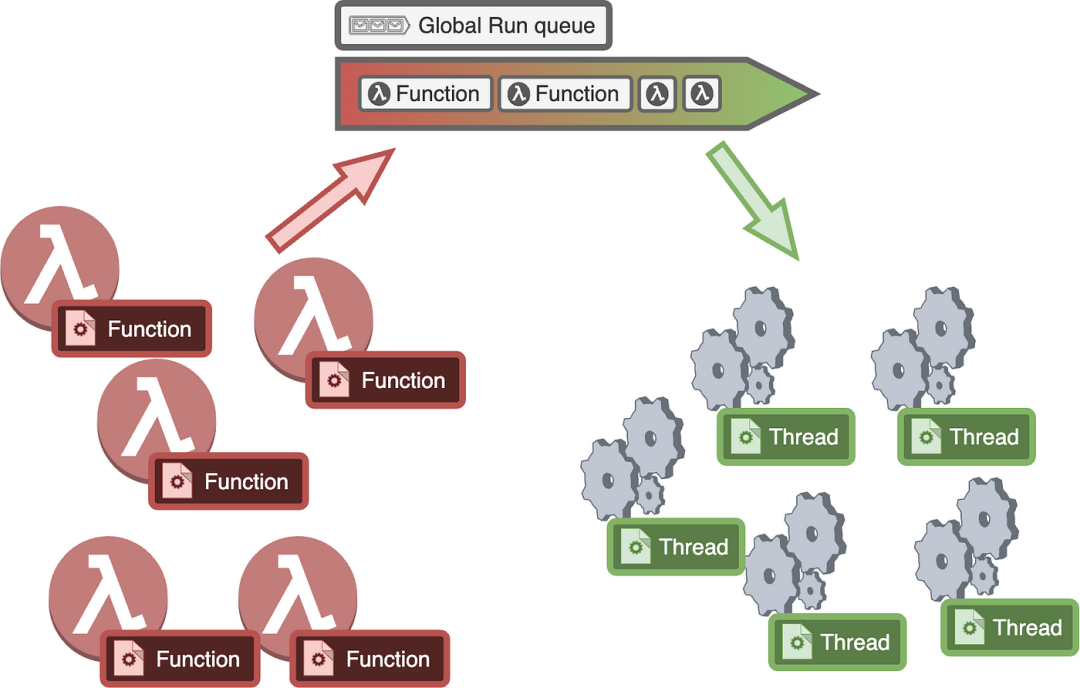
为了更好地理解,让我们编写一些基本的伪代码,描述每个线程将执行的内容。
void runThread() {
while (true) {
// Check if there is an empty goroutine
bool isEmpty = globalRunQueue.empty();
// If not empty
if (!isEmpty) {
goroutine g = globalRunQueue.getNextGoroutine();
g();
}
}
}重要的是要记住,每一个线程都在并行地运行相同的代码。
这个系统中的一个问题是,每个线程都在访问相同的共享变量,即globalRunQueue。所以,一个线程,比如说 ThreadA,检查队列是否为空,但在它能够从队列中获取 goroutine 之前,另一个线程访问了队列并选择了 goroutine。
我们需要一种方法来确保任何时候只有一个线程可以访问运行队列。
4.互斥锁
解决这个问题的一种方法是引入一个互斥锁。互斥锁只是一个锁,每个线程在访问队列之前都必须获取它。只有线程拥有互斥锁时,它才能执行操作。完成后,它可以释放互斥锁,供其他线程获取。
把它想象成一个锁,确保只有一个线程可以访问全局运行队列。
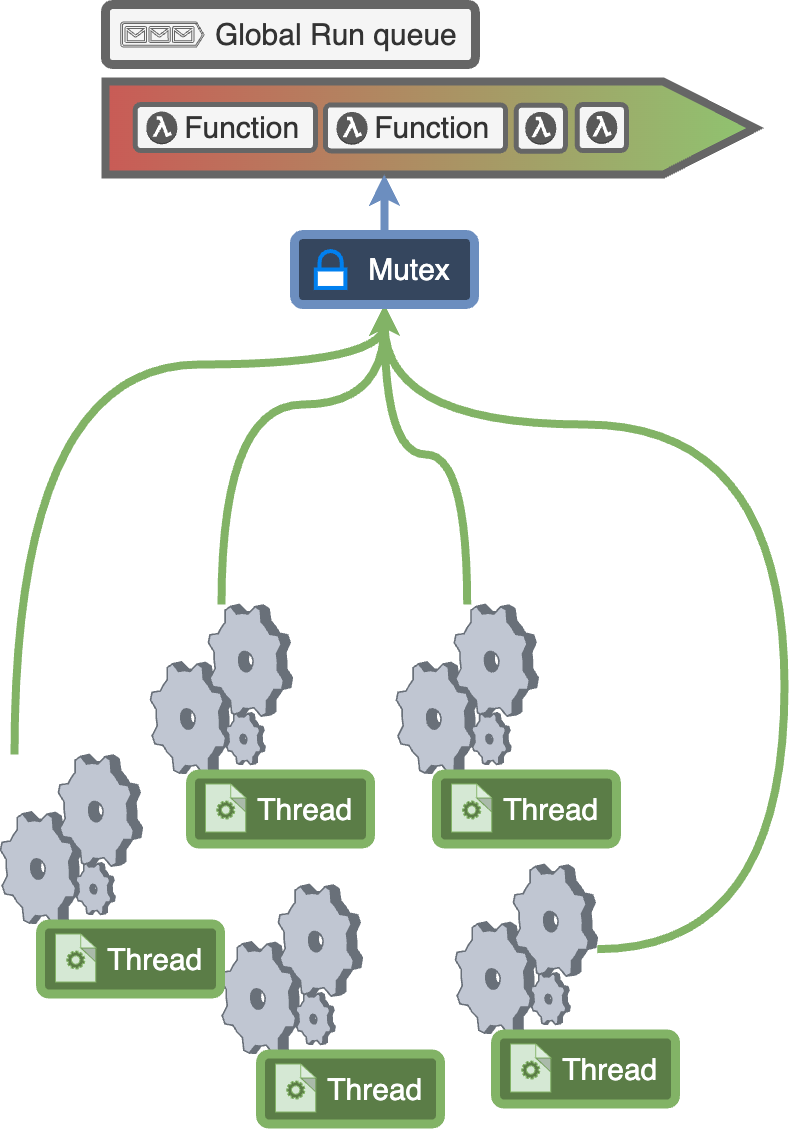
继续我们的伪代码:
void runThread() {
while (true) {
// First acquire the mutex
// This call would block execution until the mutex is free
mutex m = globalRunQueue.getMutex();
// Check if there is an empty goroutine
bool isEmpty = globalRunQueue.empty();
// If not empty
if (!isEmpty) {
goroutine g = globalRunQueue.getNextGoroutine();
g();
}
// Release the mutex
m.release();
}
}现在,下一个问题是每个线程都必须等待获取一个互斥锁来对运行队列执行任何操作。在未来,我们也可能增加暂停 goroutines、恢复 goroutines 等功能。如果所有操作都需要互斥锁,那么它可能成为我们系统的瓶颈。
5.全局和本地运行队列
为了解决单一互斥锁的问题,我们为每个线程提供了它自己的本地运行队列。
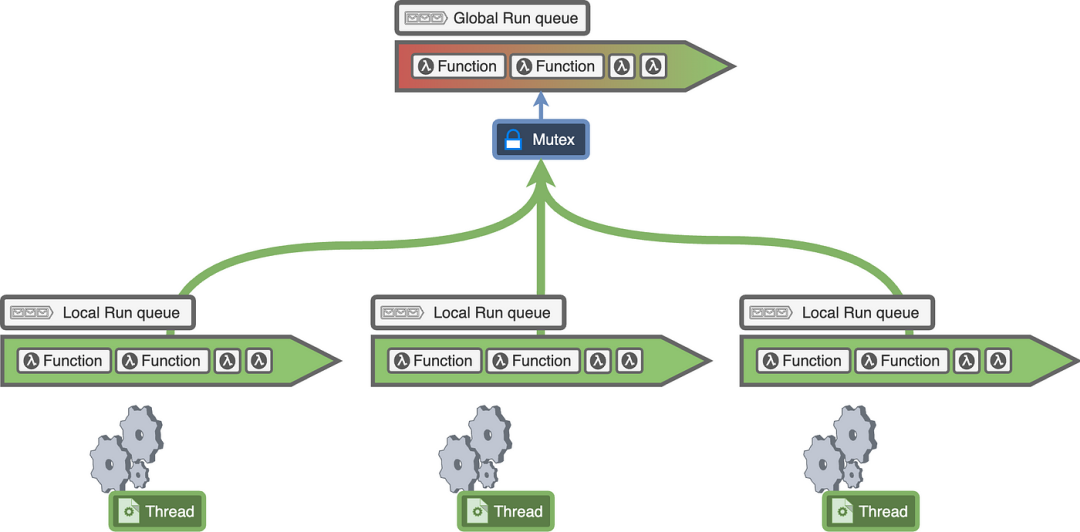
每个 goroutine 在创建时开始在全局运行队列中执行,但在某个时候由不同的系统分配给一个本地运行队列。每个线程大多与它自己的本地运行队列进行交互,选择一个 goroutine 并执行它。这样,我们把大部分工作转移到了每个线程的本地运行队列。由于本地运行队列只被一个线程访问,所以它甚至不需要互斥锁。
我们现在不再需要互斥锁,我们的代码变得更简单了。
void runThread() {
while (true) {
// Check if there is an empty goroutine
bool isEmpty = this.localRunQueue.empty();
// If not empty
if (!isEmpty) {
goroutine g = this.localRunQueue.getNextGoroutine();
g();
}
}
}我们需要明白的是,我们仍然有一个带有互斥锁的全局运行队列,但我们可以大大减少对全局运行队列的调用,因为一个单独的线程主要是从其自己的本地运行队列中取出 goroutines。它可能偶尔从全局运行队列中获取,比如当其自己的本地运行队列为空时,但那是一个罕见的情况(如果你感兴趣,这里是找到一个正在运行的 goroutine 执行的代码,你可以清楚地看到,如果它在本地运行队列中找不到一个 goroutine,它将会轮询全局运行队列)。
6.工作窃取
我们可以为我们的系统添加的另一个有趣的特性是“工作窃取”的概念。每当线程的本地运行队列为空时,它可以尝试从其他本地运行队列中窃取工作。这也有助于平衡 goroutines 的负载。
void runThread() {
while (true) {
// Check if there is an empty goroutine
bool isEmpty = this.localRunQueue.empty();
// If not empty
if (!isEmpty) {
goroutine g = this.localRunQueue.getNextGoroutine();
g();
}
else {
// Steal work from other local run queues
for (int i = 0; i < localRunQueueCount; i += 1) {
// Check if there is an empty goroutine in this local run queue
bool isEmpty = localRunQueues[i].empty();
// If not, steal the next goroutine, and run it
goroutine g = localRunQueues[i].getNextGoroutine();
g();
}
}
}
}在这个系统中,即使一个线程执行一个 goroutine 需要很长时间,它的本地运行队列中的其他 goroutines 也不会被饿死。最终,另一个线程会“窃取”这些 goroutines 并执行它们。
7.处理系统调用
如我之前所提到的,系统调用可能有点难以处理,因为它们可能需要相当长的时间。当一个 goroutine 执行一个系统调用,比如从一个文件中读取数据,它可能需要很长时间才能返回。我们甚至不知道它是否会返回,或者操作系统在幕后到底在做什么。
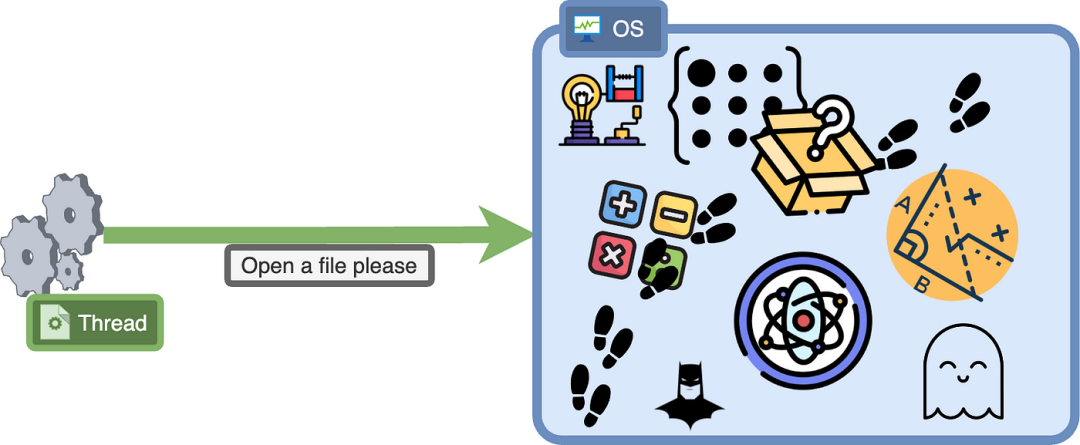
在操作系统返回之前,该线程不会被赋予任何新的工作,基本上是处于睡眠状态。我们可能会遇到一个情况,即分配给我们程序的所有线程都只是等待系统调用完成。
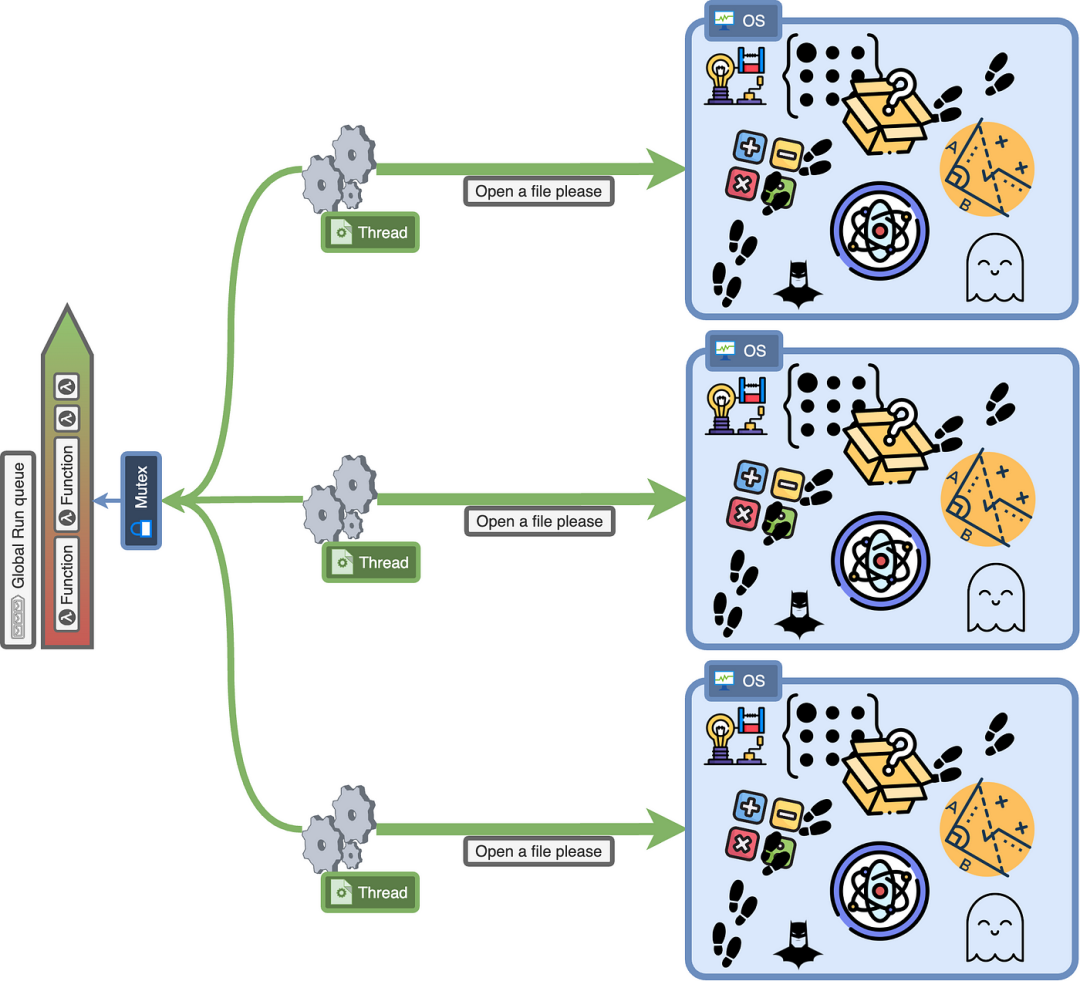
我们如何解决这个问题呢?在进行系统调用之前,我们创建一个新的线程。由于我们是在编写语言,以及编写打开文件的函数,我们可以在打开文件之前简单地添加一行来创建一个新线程。新线程创建后,当前线程进入睡眠状态,直到系统调用完成。
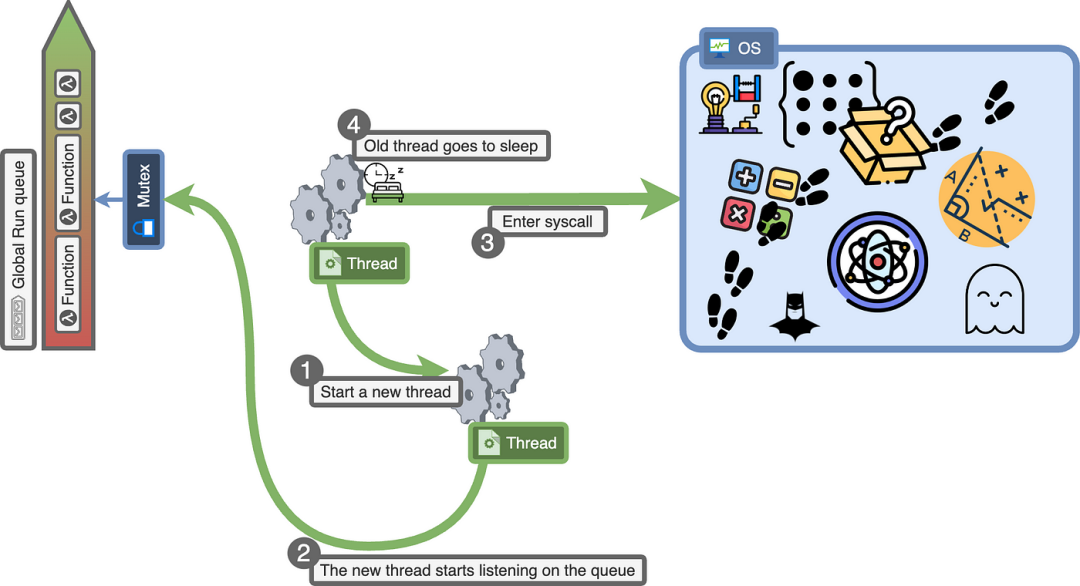
从技术上讲,这并不是过度订阅,因为当前线程正在休眠,因此不会占用操作系统的资源。
但这意味着我们可能有很多我们不使用的休眠线程。
再次说,这并不是过度订阅,但它为我们带来了一个不同的问题。由于我们为每个线程提供资源(本地运行队列),如果我们有很多线程,我们将为每个线程分配内存。
此外,我们尚未深入探讨的系统的其他部分也可能会出现一些问题,例如将 goroutines 分配给本地运行队列的系统可能会将一个 goroutine 分配给一个当前被系统调用阻塞的线程。
此外,工作窃取也可能变得有点繁琐。如果我们有很多线程,工作窃取将需要检查很多本地运行队列。
8.处理器
为了解决这个问题,我们增加了另一层抽象,称为处理器。
每个线程都会获取一个处理器,该处理器包含执行 Go 代码所需的变量。所以我们将本地运行队列以及我们可能拥有的任何其他变量(如缓存等)移动到处理器中。
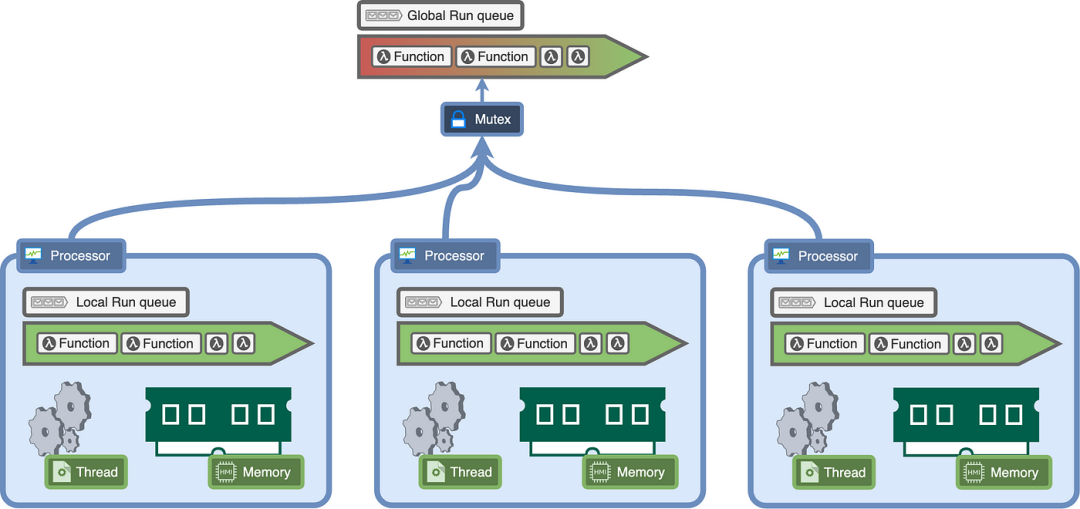
当一个线程在系统调用上被阻塞时,它将释放处理器,另一个线程将获取它并从中断的地方继续。
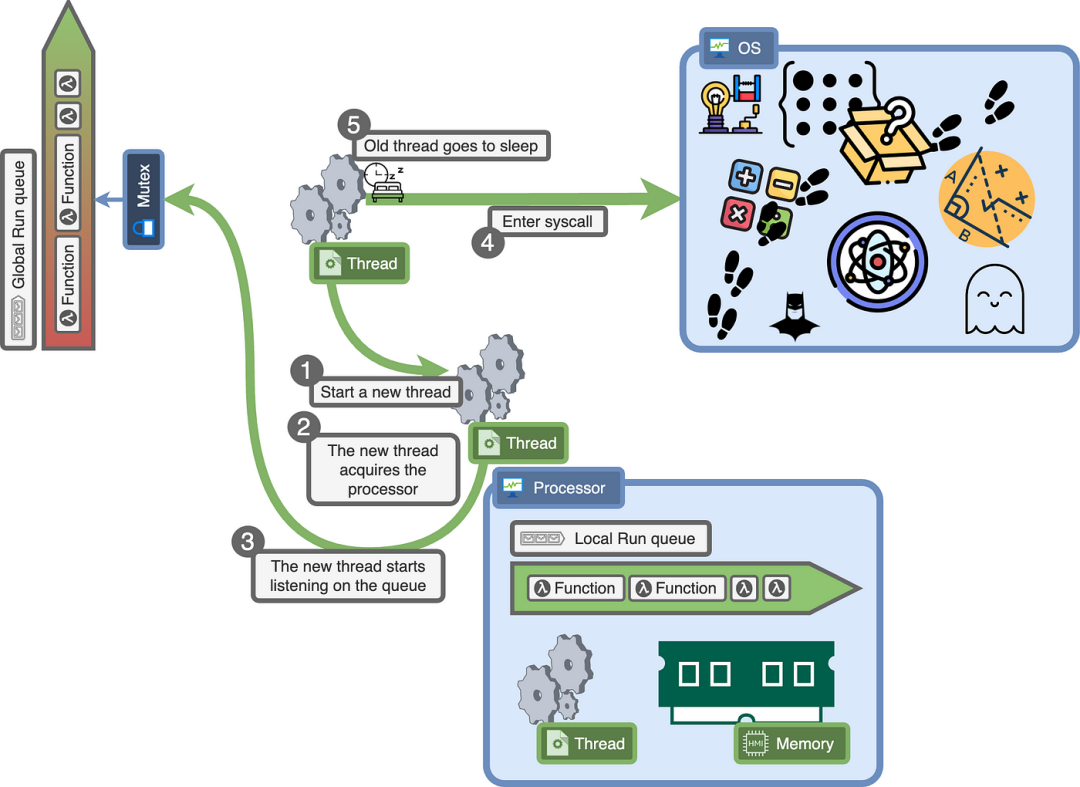
这并不显著地改变了我们的伪代码,除了我们现在在使用本地运行队列时使用了一个处理器。
void runThread() {
while (true) {
// Check if there is an empty goroutine
bool isEmpty = this.processor.localRunQueue.empty();
// If not empty
if (!isEmpty) {
goroutine g = this.processor.localRunQueue.getNextGoroutine();
g();
}
else {
// Steal work from other local run queues
for (int i = 0; i < localRunQueueCount; i += 1) {
// Check if there is an empty goroutine in this local run queue
bool isEmpty = localRunQueues[i].empty();
// If not, steal the next goroutine, and run it
goroutine g = localRunQueues[i].getNextGoroutine();
g();
}
}
}
}五、第2部分:公平性
1.抢占
为了确保没有单一的 goroutine 长时间占用一个线程,我们可以添加一个非常简单的机制,如果一个 goroutine 的执行时间超过了一定的时间段,比如说10ms,那么它会被预先暂停。然后我们将它加到运行队列的尾部。
2.全局运行队列饥饿
有一种可能性是,goroutines 不断地在全局运行队列中被填充,而每个处理器都继续在其自己的本地运行队列上工作。这可能导致全局运行队列中的 goroutines 基本上饿死。
这个问题的简单解决方案是什么呢?让我们偶尔检查全局运行队列,而不是本地运行队列。
其实在代码中理解这一点非常容易。
void runThread() {
// A simple variable to keep track of the number of goroutines
// we are running
int schedTick = 0;
while (true) {
// Occasionally poll the global run queue instead of the local run queue
// 61 is the actual number they use to decide to poll the global run queue!
// https://github.com/golang/go/blob/master/src/runtime/proc.go#L2753
if (schedTick % 61 == 0) {
// Polling the global run queue
goroutine g = pollGlobalRunQueue()
if (g != nil) {
g();
}
}
// Check if there is an empty goroutine
bool isEmpty = this.processor.localRunQueue.empty();
// If not empty
if (!isEmpty) {
goroutine g = this.processor.localRunQueue.getNextGoroutine();
g();
// Increment the schedTick variable
schedTick ++;
}
else {
// Steal work from other local run queues
for (int i = 0; i < localRunQueueCount; i += 1) {
// Check if there is an empty goroutine in this local run queue
bool isEmpty = localRunQueues[i].empty();
// If not, steal the next goroutine, and run it
goroutine g = localRunQueues[i].getNextGoroutine();
g();
}
}
}
}六、结论
这是我尝试简要描述 Golang 并发是如何工作的。我可能做了一些简化,但这大致是并发模型的方向。欢迎查看 Go 源代码中的 findRunnable 函数的实际代码这里,现在你应该能够理解它的大部分内容。
我们确实跳过了一些概念,比如网络轮询器,但这篇文章已经变得非常长,我不想在这样一个预计10-15分钟的阅读中塞入太多的信息。
我选择这个主题的原因是,我一直认为并发和并行这样的概念更偏理论而不是实际,我发现自己难以理解它内部是如何工作的。在我看来,重要的是要认识到,归根结底,这些看似非常困难且像魔法一样的底层概念只不过是代码片段,理解它们以及导致它们的决策不应该比理解任何其他代码更难。






















