












金融领域为自然语言处理(NLP)模型带来了独特的挑战和机遇。当前,金融文本和数据的信息量和复杂性呈现爆炸式增长,一个强大、可靠的智慧金融系统可以满足多种不同用户群体的金融需要,例如辅助金融从业者完成行业分析、时事解读、金融计算、统计分析工作,为金融科技开发者完成情感分析、信息抽取任务,帮助学生解答金融问题等,从而有效地提高金融领域工作和学习的效率。
金融领域本身具有高度的专业性,语言模型一方面要处理复杂的金融语言,另一方面要保证知识储备的实时性和对金融文本内数据计算的准确性,故而过往的模型通常无法在该领域提供令人满意的服务。金融领域迫切需要准确、高效的人工智能解决方案来有效处理金融行业的各种任务。而最新出现的大语言模型(LLM)在语言交互及各类 NLP 任务展现出的出色能力,为智慧金融系统的进一步发展和普及提供了新的思路。
复旦大学数据智能与社会计算实验室(FudanDISC)发布金融领域的大语言模型 ——DISC-FinLLM。该模型是由面向不同金融场景的 4 个模组:金融咨询、金融文本分析、金融计算、金融知识检索问答构成的多专家智慧金融系统。这些模组在金融 NLP 任务、人类试题、资料分析和时事分析等四个评测中展现出明显优势,证明了 DISC-FinLLM 能为广泛的金融领域提供强有力的支持。课题组开源了模型参数,并且提供了翔实的技术报告和数据构建样例。
- 主页地址:https://fin.fudan-disc.com
- Github 地址:https://github.com/FudanDISC/DISC-FinLLM
- 技术报告:http://arxiv.org/abs/2310.15205
1. 样例展示

图1 金融咨询示例
用户可以通过金融咨询模组询问金融专业知识,提高学习效率,或是与模型展开金融主题的多轮对话,拓宽金融视野。

图2 金融文本分析示例
金融文本分析模组可以帮助金融科技领域中的开发者们高效完成各类 NLP 任务,如抽取金融文本中的投资关系、金融实体等信息,以及分析金融新闻、行业评论中的情绪倾向等。

图3 金融计算示例
金融计算模组可以帮助用户完成各类金融领域中的计算任务,如增长率、利率、平均值、BS 公式等,提高金融领域的数据分析效率。

图4 金融检索知识问答示例
在金融知识检索问答模组中,模型将根据用户问题检索最新的新闻、研报、政策文件,紧跟时事热点和政策变动,给出符合国内外的形势发展变化的行业分析、时事分析、政策解读。
2. DISC-FinLLM 介绍
DISC-FinLLM 是基于我们构建的高质量金融数据集 DISC-Fin-SFT 在通用领域中文大模型 Baichuan-13B-Chat 上进行 LoRA 指令微调得到的金融大模型。值得注意的是,我们的训练数据和方法也可以被适配到任何基座大模型之上。
DISC-FinLLM 包含四个 LoRA 模组,它们分别用于实现不同的功能:
金融咨询:
该模组可以在中国金融语境下,与用户展开关于金融话题的多轮对话,或是为用户解释金融专业的相关知识,是由数据集中的金融咨询指令部分训练而来。
金融文本分析:
该模组可以帮助用户在金融文本上完成信息抽取、情感分析、文本分类、文本生成等 NLP 任务,是由数据集中的金融任务指令部分训练而来。
金融计算:
该模组可以帮助用户完成与数学计算相关的任务,除了利率、增长率等基本计算,它还支持统计分析和包括 Black-Scholes 期权定价模型、EDF 预期违约概率模型在内的金融模型计算。这一模组是由数据集中的金融计算指令部分训练而来。
金融知识检索问答:
该模组可以检索与用户问题相关的金融新闻、研报和相关政策文件,结合这些检索文档,为用户提供投资建议、时事分析、政策解读。它是由数据集中的检索增强指令部分训练而来。
模型的整体功能框架如图 5 所示。
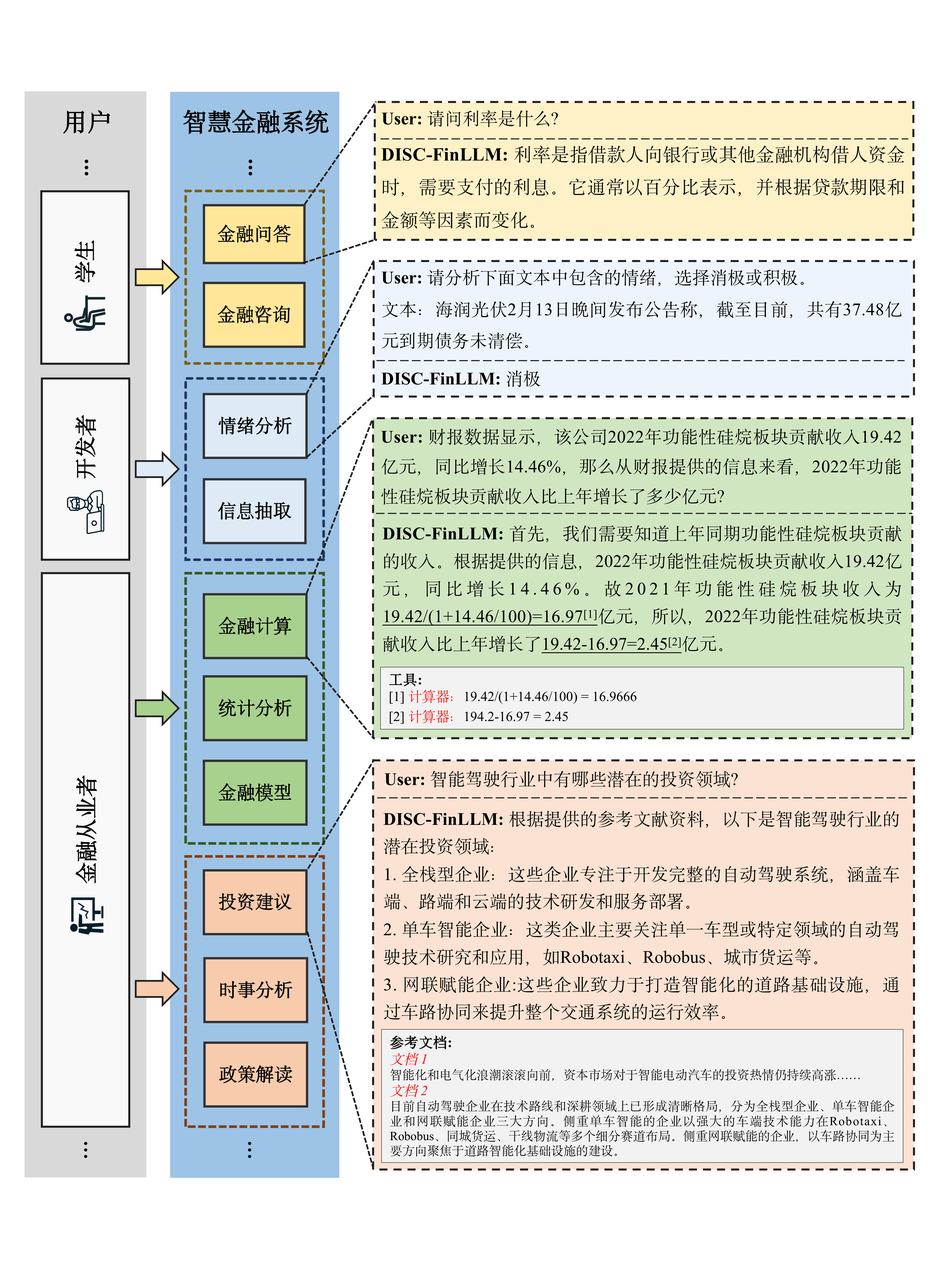
图5 模型在各种金融场景下服务于不同的用户群体
3. 方法:数据集 DISC-Fin-SFT 的构造

图6 DISC-Fin-SFT数据集的构造过程
DISC-Fin-SFT 数据集总共包含约 25 万条数据,分为四个子数据集,它们分别是金融咨询指令、金融任务指令、金融计算指令、检索增强指令。图 6 展示了数据集的整体构造过程,每个子数据集各有不同的构造方法和提示词(prompt)。表 1 展示了每个部分的构造的数据量和数据长度信息,其中输入和输出长度指的是输入和输出的文本经过分词后的平均词数。
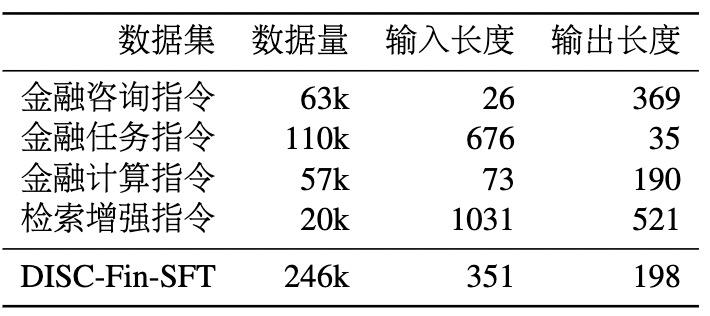
表1 DISC-Fin-SFT数据统计
3.1 金融咨询指令
金融咨询指令数据来源于三部分:
FiQA
这是一个英文的金融问答数据集,其中答案部分的质量参差不齐。因此我们将 FiQA 中的所有问题翻译成中文后,使用 ChatGPT 重新生成问题的答案,来提高这一数据集的质量,提示词如图 7 所示,上下文可根据需要选填。

图7 用于构造金融问答指令的零样本提示模板
金融名词解释
我们在网上收集了 200 多个金融领域的专业术语(如:杠杆收购),然后使用图 8 中的提示词,令 ChatGPT 为这些专业词汇生成相应的问答对,用以训练模型对金融用语的理解。

图8 用于构造金融名词问答的小样本提示模板
经管之家论坛上的公开发帖
我们采用自聊天提示(Self-chat Prompting)方法,按照图 9 中的提示词,引导 ChatGPT 围绕帖子主题生成多轮的问答。

图9 用于构造多轮对话指令的零样本提示模板
在以上过程中,我们精心设计的提示词使得 ChatGPT 可以生成符合中国国情、立场、态度和语言风格的问答,这确保 DISC-FinLLM 能够提供符合中国金融语境的咨询服务。
3.2 金融任务指令
金融任务指令数据分为两个部分:
金融 NLP 数据集
该部分是通过手动提示(Manually Prompting)方法,从已有的金融 NLP 数据集改编而来的,图 10 就是一个改编的例子。我们搜集了十余个开源的 NLP 中文数据集,任务上可以分为情绪分析、信息抽取、文本生成、文本分类和翻译等几类。具体的 NLP 数据集信息参看表 2。

图10 用于构造NLP任务指令的零样本和小样本提示模板
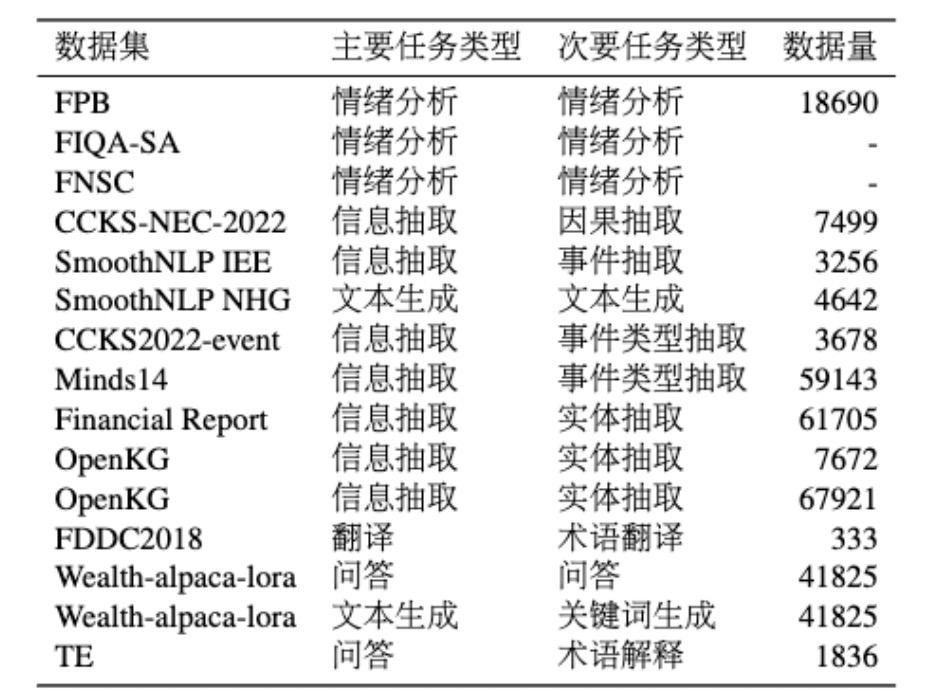
表2 金融NLP数据集统计
金融无标签文本数据集
这是一个金融文本的阅读理解数据集。首先,我们从东方财富网收集了共 87k 个文章,包括金融新闻和研报摘要。然后,基于这些无标签文本中的段落,我们通过图 11 的提示词生成(段落、问题、答案)三元组。最后,将三元组套入不同的指令模板,得到 “输入 - 输出” 指令对。

图11 根据无标签金融文本构造任务指令的提示模板
3.3 金融计算指令
在金融计算中,表达式计算器、方程求解器、概率表、计数器四种工具可以帮助模型完成大多数的计算任务。四种工具的定义如表 3 所示,它们各有不同的调用命令、输入和输出。例如,计算器的命令是 [Calculator (expression)→result]。在这一部分,构建金融计算指令的目的就是训练模型在合适的时候调用这些工具解决数学问题。

表3 计算工具的定义
我们首先构建了一个种子任务库,其中的种子任务由三部分组成:根据金融考试人工改写的计算题、带有研报上下文的数据计算题、BELLE 数据集中校园数学部分的通用数学题。特别地,根据 Toolformer 的方法,这些问题的答案中插入着上述四个工具的调用命令,它们代表着调用工具的方法和时机。随后,为了增加数据的数量和多样性,我们通过小样本思维链提示(Few-shot Chain-of-Thought Prompting)方法,让 ChatGPT 在图 12 中提示词的引导下,根据种子任务生成超过 5 万个新问答对,其中的答案也带有插件命令。

图12 用于构造金融计算指令的提示模板
3.4 检索增强指令
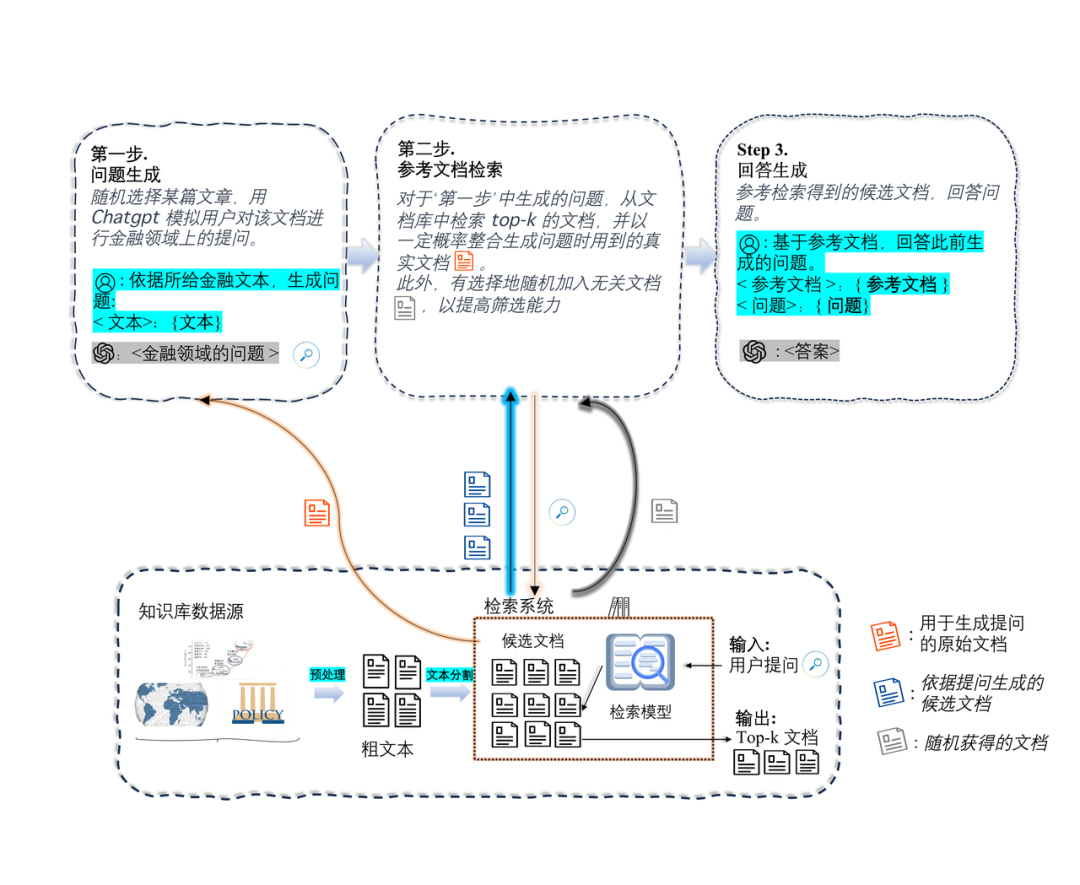
图13 检索增强指令的构造过程
如图 13 所示,检索增强指令的构造分为三步。第一步,我们根据新闻和研报等金融文本构造金融分析问题。第二步,我们在知识库中检索与问题有关的若干文档,并随机加入一些无关文档,以训练模型对有效信息的甄别能力,这些参考文档源于我们构建金融知识库,包含 18k 研报和 69k 金融新闻。第三步,我们将问题和参考资料结合在一起,生成问题的答案。在这个过程中,问题和答案是由 ChatGPT 通过检索链提示(Chain-of-Retrieval Prompting)方法生成的。
最终我们构建了一个包含 20k 条检索增强指令的数据集,其中的指令涵盖了金融领域中主要的分析形式,包括行业分析、政策分析、投资建议、公司战略规划等。
4. 实验
4.1 多专家训练框架
针对金融领域的不同功能,我们采用了多专家微调的训练策略。我们在特定的子数据集上训练模型的各个模组,使它们彼此互不干扰,独立完成不同任务。为此,我们使用 DDP 技术的 Low-rank adaption(LoRA)方法高效地进行参数微调。

图14 DISC-FinLLM的多专家微调框架
具体来说,我们以 Baichuan-13B 为基座模型,通过数据集的四个部分,分别训练 4 个 LoRA 专家模组,如图 14 所示。部署时,用户只需更换在当前基座上的 LoRA 参数就可以切换功能。因此用户能够根据使用需求激活 / 停用模型的不同模组,而无需重新加载整个模型。4 个 LoRA 专家模组分别如下:
- 金融顾问:该模型用于多轮对话。由于我们的金融咨询指令数据十分丰富,该模型可以在中国的金融语境下做出高质量的回答,为用户解答金融领域的专业问题,提供优质的咨询服务。
- 文件分析师:该模型主要用于处理金融自然语言处理领域内的各种任务,包括但不限于金融文本中的信息抽取、情绪分析等。
- 财务会计师:DISC-FinLLM 支持四种工具,即表达式计算器、方程求解器、计数器和概率表。这些工具支持我们的模型完成金融领域的大多数的计算任务,如金融数学建模、统计分析等。当模型需要使用工具时,它可以生成工具调用命令,然后中断解码,并将工具调用结果添加到生成的文本中。这样,DISC-FinLLM 就可以借助工具提供的准确计算结果,回答金融中的计算问题。
- 时事分析师:我们在第四个 LoRA 中引入检索插件。DISC-FinLLM 主要参考了三类金融文本:新闻、报告和政策。当用户问及时事、行业趋势或金融政策等常见金融话题时,我们的模型可以检索相关文件,并像金融专家一样展开分析并提供建议。
4.2 评测
我们建立了一个全面的评估框架,从各个角度严格评估我们的模型。该评估框架包括四个不同的组成部分,即:金融 NLP 任务、人类试题、资料分析和时事分析。这一评估框架全面地证明了我们模型能力和训练数据的有效性。
4.2.1 金融 NLP 任务评测
我们使用 FinCUGE 评估基准测试模型处理金融 NLP 任务的能力。我们评估了其中的六项任务,包括情感分析、关系抽取、文本摘要、文本分类、事件抽取和其他任务,它们分别对应着 FinFE、FinQA、FinCQA、FinNA、FinRE 和 FinESE 六个数据集。我们通过提示模板将这个数据集改造为小样本(few-shot)形式,然后使用常用的准确度(Accuracy)、F1 和 Rouge 指标评价模型的表现,来衡量模型在金融领域中理解文本和生成相关回答的能力。

表4 BBT-FIN基准上的实验结果
表 4 中展示的是,使用我们的金融任务指令数据微调不同基线模型前后的评测结果。从 Baichuan-13B-Chat、ChatGLM1 和 ChatGLM2 模型上不难看出,微调后模型的平均成绩比未经训练的基座模型高 2~9 分不等,表现显然更加出色。特别地,我们的数据集没有涵盖评估集中包含的某些 NLP 任务,这更说明我们构建的数据可以有效增强模型金融领域任务中的表现,即使是面对没有训练过的任务的时候。
4.2.2 人类试题评测
我们使用了 FIN-Eval 基准评估模型在回答真人生成问题上的能力,这个基准涵盖了金融、经济、会计、证书等学科的高质量多项选择题。我们以准确度为指标,来衡量模型的表现。

表5 FIN-Eval基准上的实验结果
我们对四个 LoRA 微调模型,和使用 DISC-Fin-SFT 全体数据微调的模型都进行了测试,比较模型包括 ChatGPT、GPT-4、Baichuan、ChatGLM2、FinGPT-v3 等。表 5 展示了各个模型在人类试题评测中的结果。相比之下,我们模型的平均结果仅次于 ChatGPT 和 GPT-4。与未经训练的 Baichuan-13B-Chat 模型相比较看,DISC-Fin-SFT 中的每一类指令,都有助于提高模型在人类试题评测上能力。从 FinGPT 的测评结果看,我们也比其他的金融大模型表现要好。从消融实验看,在 Baichuan-13B-Chat 模型上使用全部数据集微调后,获得的评测结果显著下降,这体现了对每个任务使用特定数据的 LoRA 微调的必要性。
4.2.3 资料分析评测
我们手动构造了一个由 100 个财经计算题组成的数据集,用于评估模型在计算任务中的能力。这些测评问题改编自中国行政职业能力测验中的材料分析计算题,包括计算同比增长率和产值比例等。我们根据模型给出计算公式和计算结果的正确率来评估模型的表现。
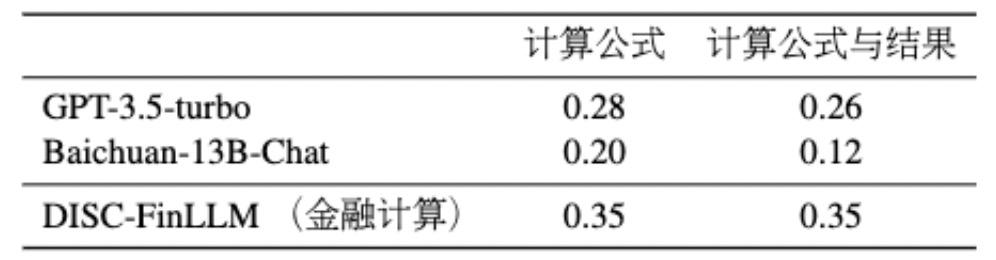
表6 计算插件的评估结果
表 6 展示了我们模型在计算任务方面取得的显著改进。与基线模型相比,我们的模型中添加了计算插件,显著提高了性能,评测结果超过 ChatGPT 0.09 分,突出了我们的方法在解决金融计算问题上的有效性。
4.2.4 时事分析评测
此方法基于 GPT-3.5 模型作出评估。我们构建了一个金融问题数据集,其中的问题需要模型使用最新信息来获得准确答案。然后我们在谷歌等搜索引擎中手动搜索与每个问题相关的多个参考文段。该数据集旨在评估出模型在回答金融问题时检索信息的相关性和准确性,我们用四个指标评价模型的表现:
1. 准确性:提供的建议或分析是准确的,没有事实错误(假设参考文本是正确的),结论不是随意给出的。
2. 实用性:模型可以结合参考文本,对金融领域的问题提供清楚、实用的分析。
3. 语言质量:模型可以正确理解问题,并在金融领域产生简洁、专业的答案。
4. 思考性:模型根据参考文献,由自己的思考分析得出结论,而不是简单地抄袭原文。

表7 检索插件的评估结果
表 7 表明我们模型的评测结果在所有指标上都明显更高,证明了检索增强指令数据训练为模型带来了明显的优势。
5. 总结
我们基于多专家微调框架构建了一个强大的中文智慧金融系统 ——DISC-FinLLM。我们根据四种特定任务的指令数据微调我们的模型,分别训练了四个面向不同金融场景的专家模组:金融咨询、金融文本分析、金融计算、金融知识检索问答,以提高其在金融 NLP 任务、人类试题、计算任务和检索任务中的性能。同时,我们的评估结果证明了我们模型在金融领域的可靠性。DISC-FinLLM 为大语言模型在金融咨询、投资分析和风险评估上的应用开辟了可能性,将为更为广泛的用户群体带来高效、可靠的金融服务支持。




















