Kafka 介绍
Kafka 是一个开源的分布式流式平台,它可以处理大量的实时数据,并提供高吞吐量,低延迟,高可靠性和高可扩展性。Kafka 的核心组件包括生产者(Producer),消费者(Consumer),主题(Topic),分区(Partition),副本(Replica),日志(Log),偏移量(Offset)和代理(Broker)。Kafka 的主要特点有:
- 数据磁盘持久化:Kafka 将消息直接写入到磁盘,而不依赖于内存缓存,从而提高了数据的持久性和容错性。
- 零拷贝:Kafka 利用操作系统的零拷贝特性,减少了数据在内核空间和用户空间之间的复制,降低了 CPU 和内存的开销。
- 数据批量发送:Kafka 支持生产者和消费者批量发送和接收数据,减少了网络请求的次数和开销。
- 数据压缩:Kafka 支持多种压缩算法,如 gzip,snappy,lz4 等,可以有效地减少数据的大小和传输时间。
- 主题划分为多个分区:Kafka 将一个主题划分为多个分区,每个分区是一个有序的消息队列,分区之间可以并行地读写数据,提高了系统的并发能力。
- 分区副本机制:Kafka 为每个分区设置多个副本,分布在不同的代理节点上,保证了数据的冗余和一致性。其中一个副本被选为领导者(Leader),负责处理该分区的读写请求,其他副本为追随者(Follower),负责从领导者同步数据,并在领导者失效时进行故障转移。
Kafka 最初是为分布式系统中海量日志处理而设计的。它可以通过持久化功能将消息保存到磁盘直到过期,并让消费者按照自己的节奏提取消息。与它的前辈不同(RabbitMQ、ActiveMQ),Kafka 不仅仅是一个消息队列,它还是一个开源的分布式流处理平台。
Kafka 的应用场景
Kafka 作为一款热门的消息队列中间件,具备高效可靠的消息异步传递机制,主要用于不同系统间的数据交流和传递。下面给大家介绍一下 Kafka 在分布式系统中的 7 个常用应用场景。
- 日志处理与分析
- 推荐数据流
- 系统监控与报警
- CDC(数据变更捕获)
- 系统迁移
- 事件溯源
- 消息队列
1. 日志处理与分析
日志收集是 Kafka 最初的设计目标之一,也是最常见的应用场景之一。可以用 Kafka 收集各种服务的日志,如 web 服务器、服务器日志、数据库服务器等,通过 Kafka 以统一接口服务的方式开放给各种消费者,例如 Flink、Hadoop、Hbase、ElasticSearch 等。这样可以实现分布式系统中海量日志数据的处理与分析。
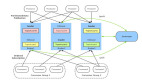
下图是一张典型的 ELK(Elastic-Logstash-Kibana)分布式日志采集架构。
- 购物车服务将日志数据写在 log 文件中。
- Logstash 读取日志文件发送到 Kafka 的日志主题中。
- ElasticSearch 订阅日志主题,建立日志索引,保存日志数据。
- 开发者通过 Kibana 连接到 ElasticSeach 即可查询其日志索引内容。

2. 推荐数据流
流式处理是 Kafka 在大数据领域的重要应用场景之一。可以用 Kafka 作为流式处理平台的数据源或数据输出,与 Spark Streaming、Storm、Flink 等框架进行集成,实现对实时数据的处理和分析,如过滤、转换、聚合、窗口、连接等。
淘宝、京东这样的线上商城网站会通过用户过去的一些行为(点击、浏览、购买等)来和相似的用户计算用户相似度,以此来给用户推荐可能感兴趣的商品。
下图展示了常见推荐系统的工作流程。
- 将用户的点击流数据发送到 Kafka 中。
- Flink 读取 Kafka 中的流数据实时写入数据湖中其进行聚合处理。
- 机器学习使用来自数据湖的聚合数据进行训练,算法工程师也会对推荐模型进行调整。
这样推荐系统就能够持续改进对每个用户的推荐相关性。

3. 系统监控与报警
Kafka 常用于传输监控指标数据。例如,大一点的分布式系统中有数百台服务器的 CPU 利用率、内存使用情况、磁盘使用率、流量使用等指标可以发布到 Kafka。然后,监控应用程序可以使用这些指标来进行实时可视化、警报和异常检测。
下图展示了常见监控报警系统的工作流程。
- 采集器(agent)读取购物车指标发送到 Kafka 中。
- Flink 读取 Kafka 中的指标数据进行聚合处理。
- 实时监控系统和报警系统读取聚合数据作展示以及报警处理。

4. CDC(数据变更捕获)
CDC(数据变更捕获)用来将数据库中的发生的更改以流的形式传输到其他系统以进行复制或者缓存以及索引更新等。
Kafka 中有一个连接器组件可以支持 CDC 功能,它需要和具体的数据源结合起来使用。数据源可以分成两种:源数据源( data source ,也叫作“源系统”)和目标数据源( Data Sink ,也叫作“目标系统”)。Kafka 连接器和源系统一起使用时,它会将源系统的数据导人到 Kafka 集群。Kafka 连接器和目标系统一起使用时,它会将 Kafka 集群的数据导人到目标系统。
下图展示了常见 CDC 系统的工作流程。
- 源数据源将事务日志发送到 Kafka。
- Kafka 的连接器将事务日志写入目标数据源。
- 目标数据源包含 ElasticSearch、Redis、备份数据源等。

5. 系统迁移
Kafka 可以用来作为老系统升级到新系统过程中的消息传递中间件(Kafka),以此来降低迁移风险。
例如,在一个老系统中,有购物车 V1、订单 V1、支付 V1 三个服务,现在我们需要将订单 V1 服务升级到订单 V2 服务。
下图展示了老系统迁移到新系统的工作流程。
- 先将老的订单 V1 服务进行改造接入 Kafka,并将输出结果写入 ORDER 主题。
- 新的订单 V2 服务接入 Kafka 并将输出结果写入 ORDERNEW 主题。
- 对账服务订阅 ORDER 和 ORDERNEW 两个主题并进行比较。如果它们的输出结构相同,则新服务通过测试。

6. 事件溯源
事件溯源是 Kafka 在微服务架构中的重要应用场景之一。可以用 Kafka 记录微服务间的事件,如订单创建、支付完成、发货通知等。这些事件可以被其他微服务订阅和消费,实现业务逻辑的协调和同步。
简单来说事件溯源就是将这些事件通过持久化存储在 Kafka 内部。如果发生任何故障、回滚或需要重放消息,我们都可以随时重新应用 Kafka 中的事件。
7. 消息队列
Kafka 最常见的应用场景就是作为消息队列。Kafka 提供了一个可靠且可扩展的消息队列,可以处理大量数据。
Kafka 可以实现不同系统间的解耦和异步通信,如订单系统、支付系统、库存系统等。在这个基础上 Kafka 还可以缓存消息,提高系统的可靠性和可用性,并且可以支持多种消费模式,如点对点或发布订阅。