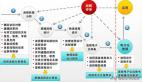
一、分享背景
1、关于此次分享
(1) 关于炎凰数据

炎凰数据是一家专注于打造自主知识产权的大数据处理平台的公司。
(2) 关于鸿鹄

鸿鹄是炎凰数据为广大开发者(研发人员、数据分析师、数据科学家等)提供的免费社区版一站式异构数据分析平台,包含了异构数据的采集、导入、存储、计算分析、可视化和告警等一系列服务。平台采用云原生架构和特有的读时建模引擎,支持标准的SOL语言,让用户可以灵活地管理海量多源异构数据,快速地分析数据特征,助力用户轻松实现数据驱动业务,诚邀大家一起参与,免费体验,共同助力新产品的功能优化、新技术的发现探索。
(3) 分享目的
Nginx是个常用的系统,其运维管理是普遍的需求。本文从实际案例出发,介绍如何利用日志动态分析平台(炎凰 数据的鸿鹄产品)完成Nginx运维管理的场景落地,涵盖从数据导入、数据解析、数据建模,到数据可视化的全过程,以及告警及第三方系统集成等等。通过实际案例分享,展示一个新型的日志动态分析平台如何通过一站式的方案解决日志运维管理中的挑战,帮助用户敏捷且高效地完成运维管理工作。
(4) 期望收获
- 端到端快速高效搭建简单Nginx运维管理的实操案例
- 使用一体化日志分析工具平台的最佳实践
- 手把手的异构数据解析和关联分析的实战经验
2、实践场景:Nginx运维管理
(1) 数据源
来自Nginx的access log (包含所有客户端请求信息),属于日志类型数据。
- 时序文本型。
- 具备一定格式而非结构化。
- 格式非固定,具有predefined combined format,也具有各种extended format,依赖于具体配置而变化。
来自Prometheus的CPU监控数据,属于监控类型数据。
- 时序型(按时间采样)。
- 结构化数据 (关系型数据库表结构,包含明确字段定义)。
来自CMDB的映射数据,属于静态数据。
- 非时序型
- 结构化数据 (IT资产与业务资产的关系数据,包含:FQDN,IP,Service等的相关映射关系)
(2) 场景特点
- 对log这类动态非结构化数据的解析。
- 多源异构数据的关联分析:Nginx + Prometheus + CMDB。
- 运维管理场景下,需求灵活多变且会持续迭代。
二、实践案例
1、场景实现准备
应用
应用是平台提供的一种实现不同场景的方式,让用户将创作的仪表板、告警等资源有序地组织起来,打造完整的解决方案。
如下图所示,利用鸿鹄平台,创建了一个名叫“Nginx运营管理”的应用,之后所有的操作,以及所有分析资源本身都会包含在所创建的这个应用当中。

因此,实现某一通用场景的最佳实践就是创建“应用”,进而通过打包等方式实现“共享”。
数据源
数据集是一个一组事件的集合,用来存储事件的容器。每一个查询,都需要描述清楚从哪个数据集开始进行查询。导入数据的时候,都需要明确指出事件存储在哪个数据集中。
如下图所示,完成应用的创建后,下一步需要新建数据集。

数据源类型
数据源类型用于对具有统一类型属性的数据进行集合处理。平台中的数据源类型包含一系列的属性,定义了对数据的各类解析处理规则,例如数据索引阶段的抽取模式、查询阶段的抽取模式、字段分隔符等。平台内置了多种开箱即用的数据源类型,包含ncinx accesslog,apache access log,syslog等。数据源类型对应字段_datatype,是一个字符串,用来标记事件原始数据的格式等元信息。
在实际使用的过程中,推荐用户优先定义数据源类型,用来限定该数据的适用范围;必要时还需自定义一些字段加工规则,用来和数据源类型进行一一对应。

2、数据处理流程
(1) 数据导入
鸿鹄系统支持各类数据源的自动化导入操作,通过数据采集器或数据连接器,将数据从不同的数据源拉取并汇总到鸿鹄系统中。同时数据的格式也是多种多样的,包括文件类型、数据库类型、Kafka类型等。
- 日志数据导入
注:此演示为手动导入过程,实际生产中多为自动化导入,关于自动化导入的实现,请参考使用手册中的“数据导入”章节设定数据源类型。

完成数据上传后,在预览界面选择自定义的数据源类型。利用鸿鹄系统实现对时间字段的自动化提取,并通过预览数据的方式确认时间字段提取的正确性。
- 设定目标数据集

将数据存放在目标数据集中,如上图所示,支持通过数据源主机来区分不同的数据来源,以达到数据源区分的目的,避免混乱。
- 数据导入验证

- CPU监控数据
- 设定数据源类型

由于CPU数据为csv文件,因此采用内置的csv数据源类型就可以进行导入(平台支持csv类型文件的时间字段自动识别功能)。
- 设定目标数据集

同样地,通过数据源主机以及数据源的方式,对数据来源进行区分。
- 资产关系映射数据
资产映射数据是相对“静态”、不带时间属性的数据,表达从A到B的映射关系。对于这类数据,鸿鹄系统支持用户通过构建“查找表”来记录这种映射关系,实现资产映射的管理。
- 构建“查找表”

上图中,构建了fqdn、ip、service这3个查找表。新建查找表的具体界面如下图所示。
- FQDN <-> 系统 映射表

- IP <-> 系统 映射表

- URL节点<-> Web服务模块 映射表

(2) 数据解析
完成了数据的导入,下一步是解析数据,提取数据字段,为建模做准备。对于本例中的数据格式,由于其是非结构化数据,故采用正则表达式的方式来提取字段。在鸿鹄系统中,正则解析方式有两种实现方式:互动划词,和手动编辑。
- 方式1:互动划词 (“数据管理” -> “字段加工” -> “新建规则应用”)

上图可以看出,蓝色方框内彩色部分是手动划分的词;完成划词后,会提示输入字段名称(右下角红色圆圈);确定字段名称后,鸿鹄系统将自动生成正则并提取字段,并提供预览界面,实现可视化互动。
- 方式2:手动编辑
如果遇到较为复杂的正则表达,样例数据不能满足已有的正则匹配,则可以进行一些手动的编辑。一般首先利用互动划词生成自动化正则表达式,然后使用手动编辑的方式进行调整。

(3) 数据建模
完成字段的解析,下一步就是对数据进行建模,根据Nginx运营管理场景的需求来实现逻辑,包括两种方式:
- 利用视图构建虚拟模型

视图,是由SQL语句组成的查询定义的虚拟表,是一个逻辑上抽象的虚拟表,用来存储查询逻辑。实际应用中,可以利用视图进行过滤、分桶等操作。
- 利用物化视图构建物理模型

物化视图是一种特殊的物理表,"物化"(Materialized)了查询的结果。和普通视图仅保存SQL定义不同,物化视图会存储SQL预计算结果的数据集,适用于数据聚合加速等场景。
在实际应用中,建议通过视图来构建物化视图,这样会让概念逻辑更加清晰,具有结构化的意义,修改或者调整的成本更低。
此外,建议用户为各资源定义合理的命名规范(如vw,mat等),以区分视图和物化视图。
(4) 数据可视化
完成了模型的构建,下一步即可创建图表,以实现可视化。在鸿鹄系统中,可以通过仪表板构建多个图表。以HTTP网络流量统计为例,实现过程如下:
- 图表构建
第1步:数据探索 -> 生成期望的分析结果数据。

首先基于实现的场景来进行数据探索,如上图所示,通过SQL实现该场景下的一些计算逻辑,生成分析结果数据;进而将其添加到可视化的UI板中,生成可视化图表。
第2步:根据分析结果数据直接创建可视化图表,按需更改钻取交互的配置图表构建。

第3步:调整可视化图表的属性,达到预期展现效果。

完成图表创建后,通过调整可视化的仪表板的各类属性,即可达到用户预期的展现效果;该模块支持用户自定义,以及eCharts等更高级的功能。

- 仪表板构建——Nginx运营管理
类似上述的过程,创建多个图表,最终构建成一个仪表板。以“Nginx运营管理”这一实际使用场景为例:

其中,所有图表均由“日期”下拉框决定时间范围和“系统名称”,下拉框决定观察对象。具体图表包括:
- HTTP网络流量统计 (MB)
- 页面访问量PV
- 页面访问量PV vs. CPU使⽤率
- HTTP请求方法分布
- HTTP请求状态码分布 (图表4中钻取的时间段)
- 访问来源分布
- 访问来源客户端类型分布
- Top10访问来源模块统计
- Top10热门页面访问统计
- 页面访问失败统计
- 异常操作记录
以上这11种图表涵盖了大多数通用的应用场景。其中,图表④和图表⑤之间形成联动。

(5) 扩展话题
完成了仪表板的构建,下面分享一些扩展话题。
- 告警开发
基于查询字段以及建模的视图\物化视图,可以进行告警开发。例如前文所述,可基于仪表板中的异常操作记录进行告警开发,以确保异常记录的时效性。
- 创建“告警”

如上图所示,利用自定义触发条件设定阈值,进而形成告警记录;再通过邮件、webhook等方式将告警结果通知给相关人员。
- “告警”执行历史

通过告警记录查询,达到良好的管理目的。
- 第三方集成
前文所述,是鸿鹄自研的仪表板上完成的开发。此外,鸿鹄系统还可以集成到第三方可视化组件(例如Grafana等)中。
- 可视化部分 -> Grafana
鸿鹄系统集成Grafana,其核心思想是将复杂的计算逻辑放到鸿鹄系统来处理,将Grafana作为可视化工具来呈现结果。这里简单分享一个在Grafana中集成鸿鹄系统的操作步骤,更详细的操作流程可以参照相关操作文档。
在Grafana中添加鸿鹄插件。

配置鸿鹄链接信息。

构建 SQL 查询。

生成可视化展现。

- 第三方集成(封装数据接口)
鸿鹄系统还可以实现数据接口的封装功能,将复杂的SQL语句封装成查询工具。
创建“SQL表函数”。

在鸿鹄系统中,将复杂的查询计算逻辑“包装”成“SQL表函数”,如上图所示,该“SQL表函数”包括函数参数及参数类型,函数的输入和输出都是数据表格;用户自定义函数逻辑将表格A转化为表格B。
调用“SQL表函数”。
应用过程中可以直接调用包装好的“SQL表函数”,因此对于下游用户接口的使用非常便捷。这样,可以将复杂逻辑甚至是Grafana不支持的逻辑,借助接口工具得以实现;详见下图举例,优化前文中Grafana集成的步骤3(构建SQL查询):Grafana通过调用“SQL表函数”接口直接实现可视化操作,从而实现数据计算和数据可视化之间的解耦。

三、总结和回顾
1、实践产出
通过数据导入、数据解析、数据建模和数据可视化等操作,最终实现了Nginx运维的一个完整的场景应用,实现了该场景下的数据监控和分析。这就是一个典型的实践产出。
- 一个完整场景应用
完成Nginx运营管理场景分析和监控需求。
充分满足场景特点:
- 实现简单化的非结构化数据动态解析,无需编程语言开发,只需字段加工配置调整;
- 实现非结构化数据和结构化数据关联分析,无需显式类型转换便可以直接快速关联;
- 实现灵活应对多变的运维管理需求,无需端到端代码重构,仅需数据模型迭代
可共享,易迁移。

下图是该场景下的界面展示示例:

2、总结回顾
Nginx运营管理是个通用的、普遍的需求,不同团队会使用不同的工具去实现这个需求。炎凰数据使用鸿鹄平台完成了基础版的Nginx运营管理实现,使用到了鸿鹄的诸多基本功能,包括应用、数据集、数据源类型、查找表、字段加工、视图、物化视图、仪表板、告警、SQL表函数等。鸿鹄系统的更多功能也等待用户的挖掘。
此外,我们帮助大家总结了一些最佳实践,避免大家在使用的过程中“绕弯路”。
- 创建“应用”
- 自定义“数据源类型”
- 确认时间字段的抽取正确性
- 通过“数据源主机”和“数据源”区分数据来源
- 使用“查找表”
- 有效结合“互动划词”与“手动编辑”
- 利用视图:行过滤 and/or 列过滤 and/or 时间分桶
- 利用物化视图:聚合加速
- 基于视图构建物化视图
- 为各资源定义合理的命名规范,如:vw,mat等
- 参考生成各图表所需的数据样例文档章节,合理分配维度和度量
- 自定义图表
- 灵活利用自定义触发条件设定阈值
- 利用Webhook对接外部网关,例如即时通讯工具等
- 利用“SQL表函数”封装逻辑,构建数据接口
该平台旨在让用户从繁琐的事情中解放出来,提高工作的效率。
本次分享只是开始,更多更丰富的场景等您来挖掘!
四、Q&A
Q1:数据解析规则和数据源类型是一一对应的关系吗?
A1:在鸿鹄系统中,这样的绑定关系并不是一对一的关系,而是多对多的关系。同一套规则可以应用于不同的数据源,实现数据间规则的共享;同样,同一数据源也可绑定不同的规则,形成规则“pineline”。
Q2:告警配置中的限制秒是什么?
A2:限制秒是告警配置中的一个必填项。假设监控CPU使用率,当CPU使用率达到80%将会设定一级报警,而运维人员的处理则往往会需要一定的时间延迟;这样在运维人员处理之前就会重复报警,生成冗余报警信息,甚至曹诚告警风暴;因此,通过限制秒的方式,在限制秒的时间内避免重复报警;如果时间超过了限制秒,而报警仍未得到处理,则会再次报警。
Q3:默认告警有自带的短信等配置方式吗?
A3:自带方式是没有的,一般最佳实践是通过webhook的方式将告警信息post出去,和外部系统实现对接;如果采用短信方式,则需要进行短信网关等的设置,需要进行针对性的开发和对接,目前没有预定义的方式。
Q4:是不是将所有来源的数据都导入到同一数据集才能实现数据关联?
A4:本文所演示的案例中,是将3个数据源导入到同一数据集;但这样的操作不是必须的,鸿鹄系统支持对多源异构数据进行直接关联,并没有数据集的限制,用户可以根据实际的应用场景去构建数据集的分布,更好地实现数据管理的目的。
Q5:使用鸿鹄需要先掌握什么技能?上手会比较困难吗?
A5:鸿鹄系统主要需要SQL技能,使用基本的SQL语法就可以实现基于鸿鹄系统的开发;而对于一些高阶的场景,鸿鹄本身已经包装好了部分函数(包括python函数、java函数、C++函数等)供用户使用,大大降低了用户的开发门槛。