大模型微调有“免费的午餐”了,只要一行代码就能让性能提升至少10%。
在7B参数量的Llama 2上甚至出现了性能翻倍的结果,Mistral也有四分之一的增长。
虽然这种方法用在监督微调阶段,但RLHF模型也能从中受益。
来自马里兰州大学、纽约大学等机构的研究人员提出了名为NEFT(une)的微调方式。
这是一种新的正则化技术,可以用于提高微调监督(SFT)模型的性能。
这种方法已经被HuggingFace收录进了TRL库,只要import再加一行代码就能调用。
NEFT不仅操作简便,而且没有显著的成本增加,作者称看起来是个“免费的午餐”。

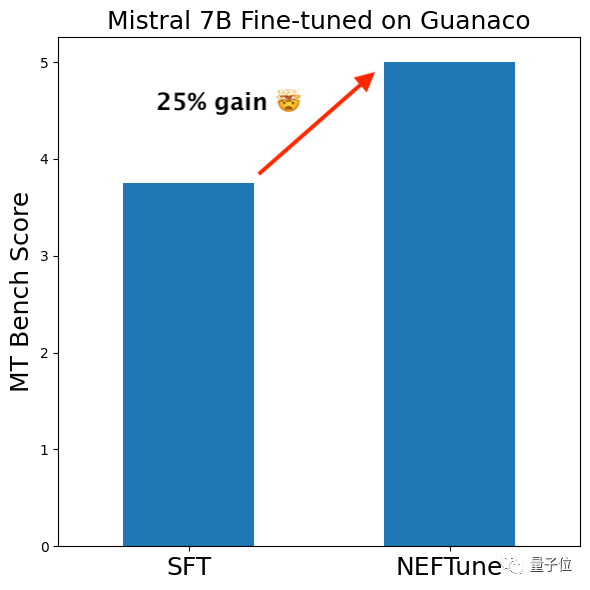
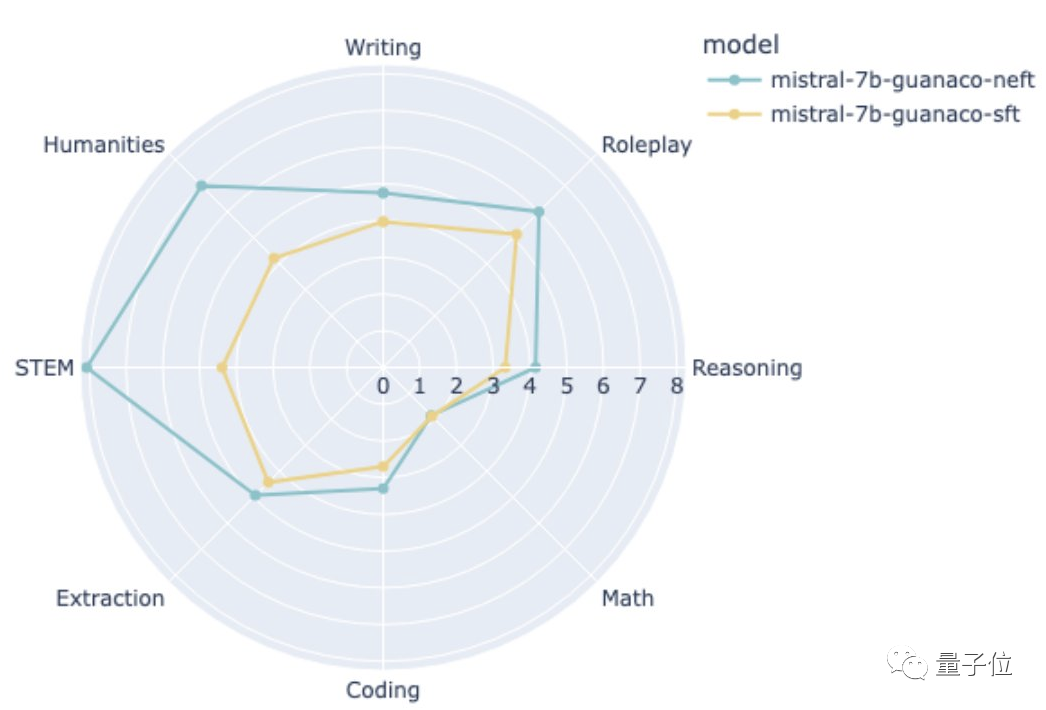
有网友试着用这种方法微调了基于Guanaco(一种羊驼家族模型)的Mistral-7B,结果性能提升明显。
那么,NEFTune是如何用一行代码给一众大模型“打鸡血”的呢?
向模型中加入噪声
NEFTune的全称是Noisy Embedding Fine Tuning,即“带噪声的嵌入式微调”。
开发者认为,过拟合现象是限制大模型性能的一大因素,因此采用在训练阶段向嵌入层中加入噪声的方式来避免过拟合的出现,从而提高性能。

具体而言,训练数据库中的文本首先会被token化,并转化为嵌入向量。
然后,系统会随机生成一个噪声向量,并用缩放器将噪声调节成所设置的强度。
经过缩放后的噪声会加入到嵌入向量中,作为模型的输入,然后开始训练。
每次迭代训练时,都会生成新的噪声并加入到嵌入层中。
from torch.nn import functional as F
def NEFTune(model, noise_alpha=5)
def noised_embed(orig_embed, noise_alpha):
def new_func(x):
if model.training:
embed_init = orig_embed(x)
dims = torch.tensor(embed_init.size(1) * embed_init.size(2))
mag_norm = noise_alpha/torch.sqrt(dims)
return embed_init + torch.zeros_like(embed_init).uniform_(-mag_norm, mag_norm)
else:
return orig_embed(x)
return new_func
model.base_model.model.model.embed_tokens.forward = noised_embed(model.base_model.model.model.embed_tokens, noise_alpha)
return model这段代码中,NEFTune函数中的形参noise_alpha就是噪声强度(系数),mag_norm则为实际过程中的噪声范围。
而NEFT只有在训练过程中才会向模型中加入噪声,推理阶段无此过程,代码中的if语句起到的就是这个作用。
训练模式下,new_func函数的返回值即为加入噪声后的嵌入层。
贴出这段代码是为了讲解需要,如果只是想调用NEFT,可以不必使用上面的完整代码,直接从TRL库中调用就可以了。
下面的代码是微调OPT-350M模型的一个示例:
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("imdb", split="train")
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()而数据集方面,开发者一共使用了Alpaca、ShareGPT等四种不同数据集进行了微调。
作者介绍,选择这些数据的原因包括它们比较著名、曾成为SOTA等等。
此外出于硬件性能考虑,实验过程中所选择的都是单轮对话数据集。
那么,用NEFT方法调校过后的大模型,表现到底怎么样呢?
性能最高提升1倍
研究团队主要测试了模型调校前后生成的文本质量和对话能力。
其中文本质量主要基于AplacaEval数据集,使用ChatGPT和GPT-4评估。
用作参照的模型是Text-Davinci-003,训练后的模型胜过TD3的比例即为评价指标。
为了节约资源,研究团队先用ChatGPT判断是自己来评价还是调用GPT-4,部分情况下还会人工评判。
结果在不同的训练数据集中,Llama 2调整后都有至少10%的性能提升,在Alpaca数据集上更是直接翻倍。
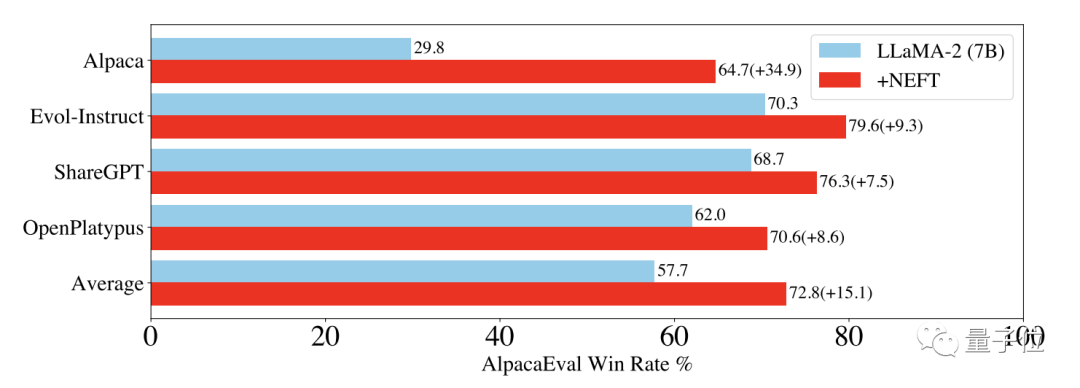
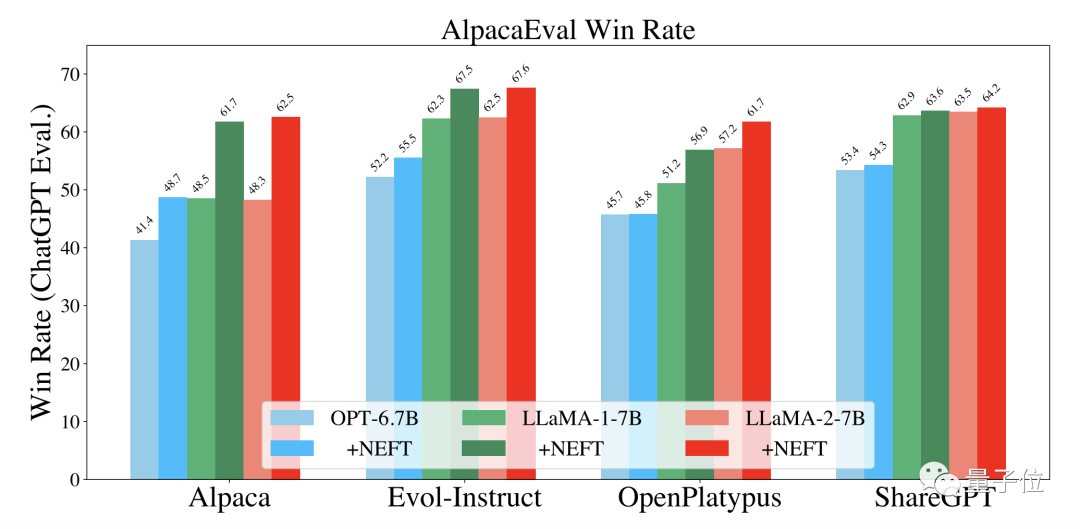
推广到OPT和Llama 1,NEFT方法同样可以带来一定的性能提升。
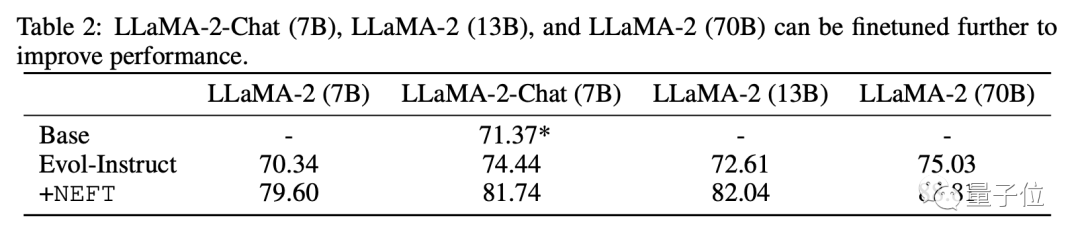
而用于评估模型聊天能力的,则是OpenLLM Leadorboard中的任务。
结果发现,NEFT调整后模型的聊天能力同样相比Evol-Instruct有进一步提升。
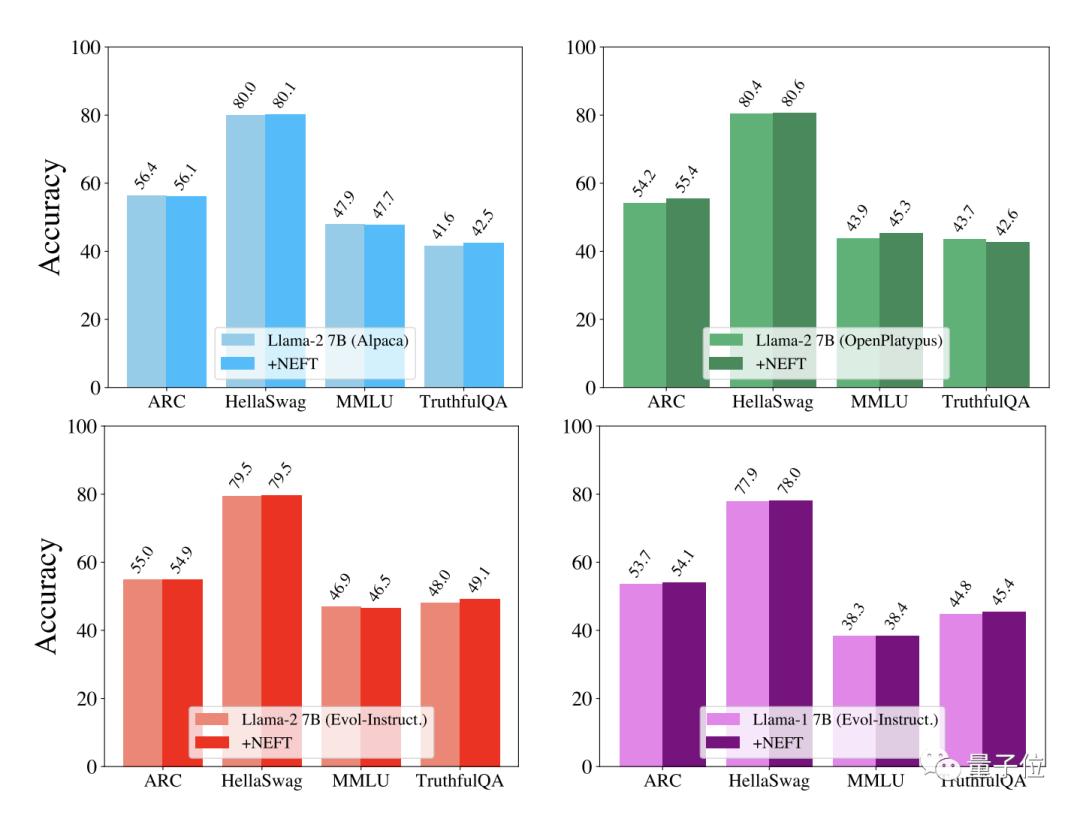
在成本没有显著增加的情况下,提高文本质量和聊天能力,是否会导致其他能力的下降,作者对此也进行了评估。
结果显示,NEFT方法在不同的数据集和模型上,对模型的其他能力均没有显著影响。
实验过程中,作者还发现,模型生成的文本和并不是照搬训练数据,提示了模型具有一定泛化能力。
为了证实这一点,作者对模型损失进行了评估,结果发现测试数据集损失低于训练数据,证实了这一观点。
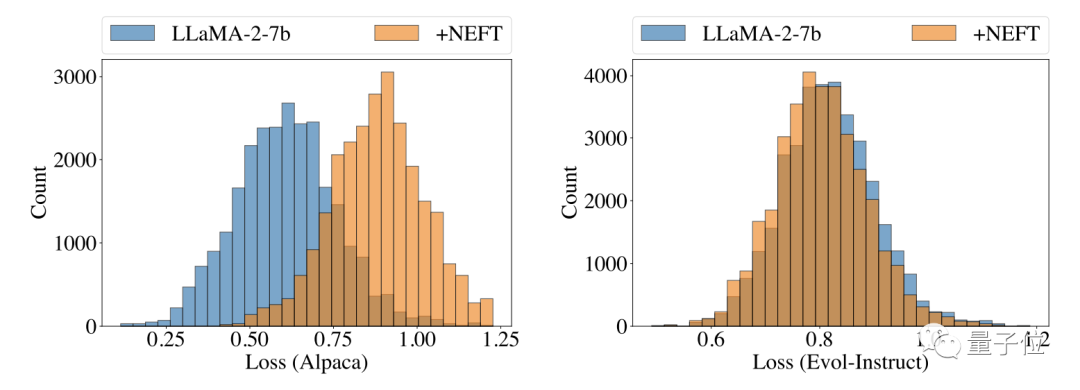
此外作者发现,经NEFT调整之后,模型生成的文本不仅质量提高,长度也有所增加,而且增加的并非重复内容。
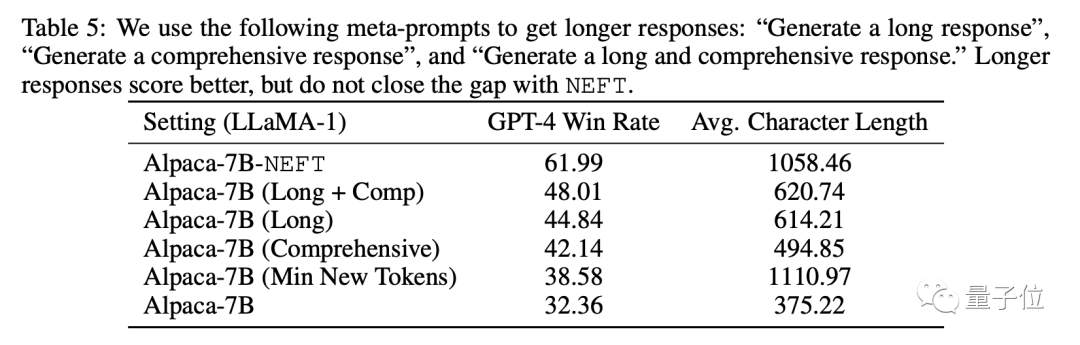
为了确认文本质量的提高是加入噪声的作用而不是由文本长度的增加所导致,研究人员又进行了消融实验。
结果显示,只是强制模型生成更长的文本无法达到NEFT的效果。
论文地址:https://arxiv.org/abs/2310.05914