作者 | 金色旭光
一、背景介绍
我是一名Python开发,就职于一家AI公司,负责开发迭代一个深度学习的模型训练平台。模型训练平台主要是给算法工程师训练模型,开发语言是Python,Web框架为Fastapi。模型训练使用Pytorch框架,封装成Docker运行。我负责除Pytorch之外平台功能开发,有一位算法工程师负责Pytorch开发,封装成容器提供给我。
目前这个训练平台是单机版,支持多显卡训练,也就是所谓的单机多卡的训练模式。随着公司业务的发展,模型训练需要的GPU越来越多。单台服务器支持显卡数量再多也会有一个上限,这时就需要能够使用多台GPU服务器上的多个显卡,也就是多机多卡的训练模式。
在这样的背景下,我需要将单机的训练平台升级为分布式的训练平台。只有我一杆枪,一个配合的算法工程师,一个前端,一个测试。经过将近两个月的开发,完成了这个任务。
开发过程遇到的非常多的问题,折磨了我一次又一次。好在最后基本都解决问题了。本篇就从需求说明、实现方案、踩坑经历等方面来介绍这一段特殊而难得的开发经历。
二、需求说明
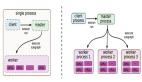
1.单机版架构
首先介绍一下单机版模型训练平台。模型训练简单来说就是用训练容器读取数据集,跑模型训练,最终生成一个模型文件。
 图片
图片
模型训练主要有两个步骤:
- 准备数据集
- 启动训练容器跑训练
单机版顾名思义数据集、训练容器、生成的模型等所有流程都在一台服务器上完成。
2.分布式版架构
分布式的训练平台是将训练任务分发到多个训练节点上,让多台服务器的GPU互相通信,算力统一起来使用。
 图片
图片
想要将这样一个单机架构的平台升级成分布式平台需要实现的功能有三个:
- 每个训练节点都要读取全量的数据集,需要将数据集复制到各个训练节点
- 多个训练节点要支持跨节点的模型训练
- 容器启动命令要能够下发到训练节点
其中第2个功能Pytorch模型训练框架已经支持了分布式的训练模式,并且当前系统做分布式也是基于这个能力才有可能开发完成。
DistributedDataParallel(DDP)是一个支持多机多卡、分布式训练的深度学习工程方法。Pytorch现已原生支持DDP,可以直接通过torch.distributed使用。
让Pytorch训练容器支持ddp是由算法工程师去完成的,对于我来说,只需要在训练节点1和2上执行不同的容器启动命令即可。
三、实现方案
针对实现功能1、3,技术方案设计如下:
1.数据集复制
因为数据集只能从主节点上传到平台,所以要想将数据集移动到训练节点有两个方案,分别是:NFS共享目录、文件同步 。
NFS
NFS不用过多介绍了,就是本地挂载一块远端机器的目录,将远端目录当做本地目录使用。
优点:NFS 的优点是内核直接支持,部署简单、运行稳定,协议简单。
缺点:通过网络读取数据集,IO速度会成为数据加载的瓶颈。
NFS的缺点是网络传输速度慢,我们的环境只有千兆带宽,在模型训练时通过千兆带宽分布式进程通信会让整体的训练速度慢一个等级。最优解是IB网,IB网是转为大规模数据中心设计的网络架构,带宽能达到50G,但是我们没有,客户大概率也用不上成本飙升的IB网。
文件同步
通过文件同步可以将数据集分发到训练节点。比较了常规文件同步使用的技术,最后选择了lsyncd这款工具。
rsync 是Linux系统上一款开源的快速的可实现全量及增量远程数据同步备份的优秀工具。lysncd 是lua语言封装了 inotify 和 rsync 工具,采用了 Linux 内核里的 inotify 事件触发机制,然后通过rsync同步差异,达到实时的效果。
优点:支持断点续传;同步数据集,能够满足模型训练需要的IO速度
缺点:同一份文件会复制出多份,存在冗余,增加存储的压力;文件同步是基于时间间隔或累计文件数据量,非严格意义的实时。
方案选择
因为NFS的缺点比较致命,而lsyncd的缺点通过逻辑可以克服。所以数据集的最终解决办法是使用lsyncd同步数据集,同时也需要将训练节点生成的模型等文件同步到主服务上,即双向同步(这里有坑,下文会说)
2.远程执行命令
单机版运行时直接在本机通过命令启动训练容器,命令类似:
nvidia-docker run--gpus '"device=0"' -name train_container_1 7055fe2b9719分布式训练需要选择一台服务器做主节点,多台服务器做训练节点,需要在不同的服务器上启动多条命令。所以就需要一个能远程执行命令的功能。
能够远程执行的技术选型还有:
- http 请求
- rpc 请求
- ssh 远程执行
- socket 网络
- 中间件发布订阅
经过对比,最终选择rpc来实现这个功能,理由如下:
- rpc 可以同步响应
- rpc 基于IP地址调用,符合当前整体架构
- rpc 服务端方便记录调用的日志
- 没有中间件,组件少,技术简单
Python 中rpc相关的库有很多,如:
- python自带的库 xmlRPC
- google开源可跨语言的 grpc
- 第三方库 zerorpc
- 第三方库 jsonrpclib
经过比较选择zerorpc,原因是灵活、轻量级、高性能。zerorpc的demo如下:
服务端:
import zerorpc
class HelloRPC(object):
def hello(self, name):
return "Hello, %s" % name
s = zerorpc.Server(HelloRPC())
s.bind("tcp://0.0.0.0:4242")
s.run()客户端:
import zerorpc
c = zerorpc.Client()
c.connect("tcp://127.0.0.1:4242")
print(c.hello("RPC"))四、开发过程记录
编码时间大概5个星期左右,时间是蛮久,只怪咱只有一个人。进度流水账如下:
1.部署lsyncd同步工具,让数据集能够从主节点同步到训练节点
2.开发rpc的服务端和客户端,训练命令下发到选中的节点
3.通过rpc获取训练节点GPU信息,让页面支持选择不同机器的GPU
4.调试远程训练单机单卡,调通数据集分发和训练命令下发
5.和算法工程师确定多机多卡训练容器的启动命令
6.调试多机多卡训练,发现ddp启动会阻塞,解决问题花费一个星期
7.发现rpc有问题,替换zerorpc为grpc
8.数据集同步和执行训练命令之间有先后依赖关系,解决同步问题
9.模型训练、推理、验证三个主要功能完成
经过5个星期的开发,最终完成了模型训练的基本功能,包括模型训练、模型验证、模型推理。由于架构的变化应该可能潜在一些未发现的bug。对于bug来说,发现它是测试同事的工作,而是我的任务就是送它去见测试同事。所以,就转测了。
五、遇到的问题
经过三轮的测试,在修复了很多bug之后,最终完成了分布式功能版本的开发。
在这两个月中,我遇到了非常多问题,我登记在册的问题是13个,实际上还有一些未上榜的,主要原因是从单节点到分布式涉及到存储、通信等变化让系统复杂。
限于篇幅挑选几个讲讲,给后续使用相关技术的人一个避坑的提醒。
1.zerorpc 服务端不支持多线程并发请求
调研zerorpc时,我关注的点包括是否满足功能要求、代码复杂性、模块的活跃度、github代码提交时间等。从我关注点出发,zerorpc是比较完美符合我要求的,但是完成相关功能开发之后才发现zerorpc竟然不支持并发请求。真是厕所里跳高——过分。
现象:多个客户端请求达到服务端,请求会变成串行执行
原因:zerorpc是基于协程库gevent实现的并发,而我们的技术栈不是协程,这就导致zerorpc不支持并发操作。
解决办法:rpc服务端肯定需要支持并发请求,将zerorpc换成了grpc。
之所以开始没有选择grpc,是因为grpc使用略复杂,需要先写proto文件,编译,再分别实现客户端和服务端。但实事证明虽然繁琐了一些,grpc还是值得信赖的。
2.数据集筛选报错
数据集是决定模型质量的一个重要因素,所以对数据集会有合并、过滤、筛选等操作,每次操作都会生成一份新的数据集文件。
现象:测试发现筛选数据集时偶尔会报错,大概筛选10次以上就会出现。
原因:非必现的问题是最头疼的问题。这个问题我排查了3天,最后发现是lsyncd双向同步的问题,也就是我在技术选型中提到的坑。
数据集筛选会生成一个新的文件夹,这个文件夹由主节点一边生成一边同步给训练节点,而训练节点在同步时间到来时也会给反向同步给主节点,这就会导致覆盖掉主节点原本文件夹的目录,从而破坏了原数据集。
解决办法:根据规则关闭到从节点到主节点的同步,避免反向同步。
这个问题想要解决除非更换lsyncd工具,否则没有完美的方法。可以尝试使用git大文件同步方案来替换lsyncd,当然最好的方案还是基于IB网的NFS,既能满足速度要求,又能避免冗余。
3.主节点异常退出,从节点不能退出
Pytorch实现多机多卡的分布式训练时会启动一个主节点和多个从节点。
现象:在多机多卡训练时,主节点异常退出时,从节点不能正常退出。主节点可能是因为读取数据集失败或者GPU显存不够等原因退出,从节点会一直阻塞,并且显示占用GPU显存。
原因:在基于Pytorch的分布式中,使用nccl作为后端通信机制时,是没有超时功能的。如果主服务阻塞,那么从服务会一直等待。
解决办法:设置一个环境变量,NCCL_ASYNC_ERROR_HANDLING=1,然后给ddp进程组设置超时时间
import torch.distributed as dist
dist.init_process_group(
…
backend="nccl",
timeout=timedelta(secnotallow=60)
)六、一种解决疑难问题的套路
遇到的这么多问题,如果全都是靠蛮力解决,那我头上的头发也保不住了。在这个过程中,我使用自己总结的一种解决疑难杂症的思路去分析问题,解决问题,我把它叫做解决疑难问题的套路。
解决疑难问题的套路包含了分析和解决,简单来说分为三步:问题的现象是什么?已知内容是什么?列出合理的猜测。
下面分别介绍每一步做什么。
1.问题的现象
想要解决一个问题首先要非常清楚问题是什么,所以第一步就是要搞清楚问题的现象是什么。以主节点异常退出,从节点不能退出为例,这个问题的现象就是当主节点训练容器exit之后,从节点继续运行,不会退出。
有时看到的还不一定是真正的现象,需要稍作分析判断,找出真正的现象,否则可能会南辕北辙。
2.已知的内容
在知道问题的现象之后,列出已经掌握肯定的、准确无误的线索。这些线索是解决问题的基础、灵感、出发点。比如可以是一些计算机基础知识,也可以是在这个场景下反复实验得到的结论。以主节点异常退出,从节点不能退出为例,已知的内容是主节点和训练节点之间网络肯定是互通的,排除网络不达的可能。
列出已知内容,能够收缩猜想的范围,排除疑点,减少可能性。
3.列出合理的猜测
在了解现象知道肯定的线索的之后,就能做出合理的猜测。最后一步就是汇总前面掌握的情况,从现象出发,根据已知的线索,列出可能产生问题的原因。以主节点异常退出,从节点不能退出为例,可能的原因包括:
(1)训练节点容器没有捕获到退出信号;
(2)NCCL主从进程没有断开,一直阻塞;
(3)NCCL主从进程断开,程序没有捕获异常。
最后逐一验证猜想,这个过程中可能解决问题,可能发现新的线索。如果不能解决问题,再来一轮,基于上一轮的掌握的新线索做出合理的猜想,验证所有的猜想。掌握的线索越来越多,问题的范围越来越小,最终一定抓住这个bug。
贴一个问题的解决过程,如下。

七、收获
经过这一段时间的开发,接触到很多新知识,收获也还不错。
1.学习模型训练框架Pytorch dpp
学习了Pytorch的实现,了解了模型训练过程,了解Pytorch ddp的原理,学习了一个进程等待的巧妙方法。
@contextmanager
def torch_distributed_zero_first(local_rank: int):
# Decorator to make all processes in distributed training wait for each local_master to do something
if local_rank not in [-1, 0]:
dist.barrier(device_ids=[local_rank])
yield
if local_rank == 0:
dist.barrier(device_ids=[0])
# 使用该装饰器下载资源
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locallydist.barrier 是PyTorch 的分布式通信库,会阻塞等待,所有注册进程都到齐了才会通过。
从语法上来说:使用上下文管理器加yield关键字实现一个装饰器;从功能上来说:让所有子进程等待,放过主进程做一些操作,等主进程操作完成才会放行所有进程。用于只有主进程才能操作的场景。
2.做复杂的技术方案
该技术方案是我做过最复杂的技术方案,有架构设计、技术选型、技术优劣对比、潜在问题、解决办法等。总结出一个写技术方案的模板:
(1)关键技术分析
(2)要实现的功能
(3)技术难点
(4)实现方案
(5)优劣对比
(6)最佳方案理由
(7)遗留问题解决办法
3.技术选型
技术选型是一个比较困难的工作,我在选择的rpc框架zerorpc和文件同步工具lsyncd一定程度上都存在问题。zerorpc不能并发、lsyncd存在双向同步的问题。
技术选项要从几个点出发:
(1)是否能够满足业务逻辑
(2)是否符合当前技术栈
(3)技术复杂性不能过高
(4)是否有明显的缺陷
像是zerorpc框架就有明显的缺陷,在查阅资料的时候也见过有些文章提到zerorpc是基于协程的并发,但当时并没有仔细思考,直到碰见并发请求才发现问题。
4.个人感受
一个人开发一个项目,我最大的感受就是太爽了。这种感觉就像自己在盖一个大别墅,图纸设计是我做,搬砖砌墙我能搞定,最后造出一个完全属于自己审美风格的别墅。