













GPT-4、Llama等基础模型(FM)相继诞生,已成为当前生成式AI的引擎。
尽管这些FM的社会影响力不断增大,但透明度反而下降。
GPT-4官宣后,OpenAI公布的技术报告中,并未提及关键信息。包括谷歌PaLM,以及其他闭源模型也是如此。

每个人心中不禁有许多疑问:
模型如何训练?如何部署?训练数据从哪来?
构建这些AI系统背后,数据标注反馈的人是谁?他们薪水是多少?
除了以上问题等等,其透明度无论是对公司,还是对社会,都十分重要。
这不,斯坦福、MIT、普林斯顿团队提出了一个「基础模型透明度指数」,并对当前十个主流模型的透明度进行了评级。

地址:https://crfm.stanford.edu/fmti/
结果显示,10个模型中最透明的是Llama 2,得分为54%。GPT-4、PaLM 2都排在后面。
研究者承认,透明度确实是一个宽泛的概念。
斯坦福对于模型评分基于100个指标,这些指标涉及模型是如何构建、如何工作以及人们如何使用它们等等。
没想到的是,这个评分系统却引众多研究者炮轰,HuggingFace的联合创始人、LeCun都在其列。
斯坦福AI模型的公开排名,可能与模型的能力相反。而要求私人公司公开商业机密的想法太幼稚。
HuggingFace联创表示,这并非曼哈顿计划,初创公司选择不公开是为了盈利,完全可以理解。
并且,只要它们不以虚假的「安全理由」推动监管,限制那些想要开源的公司就行。
具体看看,这份报告是如何对模型透明度进行评估的。
生成式AI模型,急需透明度!
现在,基础模型的社会影响不断上升,但透明度却在下降。
如果这种趋势持续下去,基础模型可能会变得像社交媒体平台和其他以前的技术一样不透明,从而重蹈他们的覆辙。

从具体角度来讲,生成式AI是一把双刃剑,其既可以提高生产力,也可以用来伤害他人,有些人通过创建未经同意的深度伪造图片和视频,用于私有目的。
开发商确实有禁止此类用途的政策。例如,OpenAI的政策禁止一长串用途,包括使用其模型为他人生成未经授权的法律、财务或医疗建议。

但这些政策如果执行不到位,就无法产生实际的影响,而且由于平台在执行方面缺乏透明度,我们不知道它们是否有效。
老练的坏人可能会使用开源工具生成伤害他人的内容,因此政策永远不可能是一个全面的解决方案。
基础模型透明度指数
「2023年基础模型的透明度指数」由斯坦福大学基础模型研究中心(CRFM)和以人为中心的人工智能研究所(HAI)、麻省理工学院媒体实验室、普林斯顿大学信息技术中心的8名人工智能研究人员创建。

论文地址:https://arxiv.org/pdf/2310.12941.pdf
该团队的共同目的是提高基础模型的透明度。
评估的指标除了技术方面(数据、计算和模型训练过程的详细信息)之外,还包括训练基础模型的社会方面(对劳动力、环境和实际使用的使用政策的影响)。
此外,还需要评估其他指标,例如,开发人员是否披露执行数据劳动的工人的工资、用于开发模型的计算资源以及他们如何执行其使用政策。

这些指标基于并综合了过去旨在提高人工智能系统透明度的干预措施,例如模型卡、数据表、评估实践以及基础模型如何协调更广泛的供应链。
透明度报告的统计与发现
定义指标
在透明度报告中,定义了100个指标,全面表征基础模型开发人员的透明度。可将指标分为三大领域:
1. 上游:上游指标指定了构建基础模型所涉及的成分和流程,例如用于构建基础模型的计算资源、数据和劳动力。
2. 模型:模型指标指定基础模型的属性和功能,例如模型的架构、功能和风险。
3. 下游:下游指标指定基础模型的分发和使用方式,例如模型对用户的影响、模型的任何更新以及管理其使用的策略。
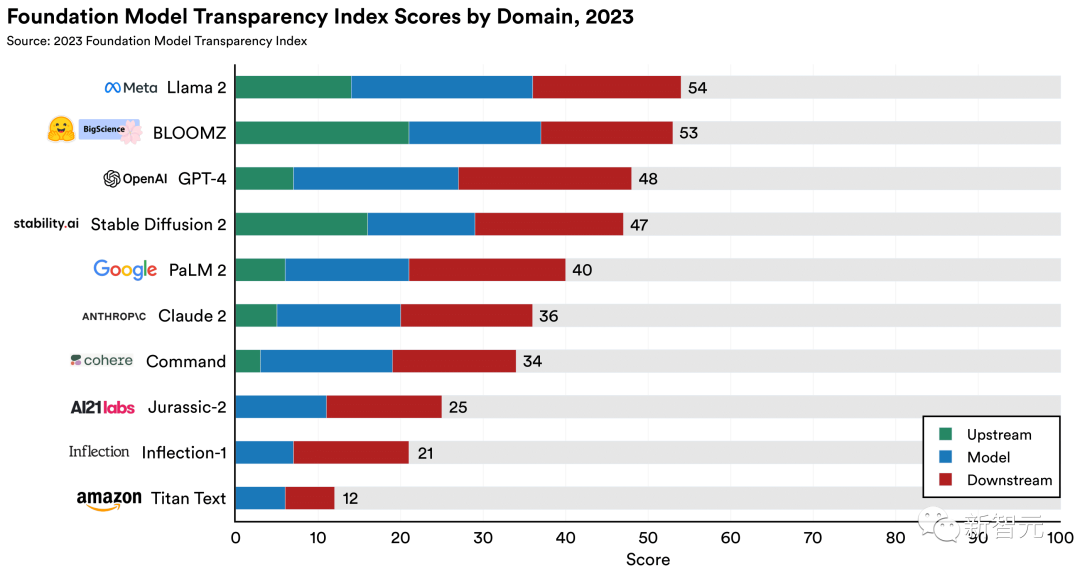
10个基础模型提供商的分数(按领域细分)
根据该指数的100项指标评估10个主要基础模型开发商及其旗舰模型,并全面找到需要改进的领域。
主要发现
通过计算,10个模型的平均分仅37分(满分100分),即使是最高得分的模型也勉强超过50分。
没有一家主要的基础模型开发商能够提供足够的透明度,这揭示了人工智能行业根本上缺乏透明度。

然而,有一个模型满足了其中82项指标,这表明如果其他开发人员能够实施他们已经采用的实践,那么有改进的空间。
开源基础模型需要引领潮流,在三个开源基础模型(Llama 2、BLOOMZ、Stable Diffusion 2)中的两个获得了两个最高分,两者都允许下载模型权重。
Stability AI是第三个开源基础模型开发公司,排名第4,仅次于OpenAI。
其他发现
在对模型进行评分后,研究团队主动联系了相关公司,寻求他们的回应和反驳。
下图显示了在解决开发者的反驳后,每个模型的最终得分情况还,并将指标分组为子域。其中子域提供了更精细、更直观的分析。
1. 数据、劳动力和计算是开发人员的盲点。
开发人员对于构建基础模型所需的资源最不透明。这是由于数据、劳动力和计算子领域的低性能造成的。所有开发人员的分数总计仅占数据、劳动力和计算可用总分的 20%、17% 和 17%。
2. 开发人员对于用户数据保护及其模型的基本功能更加透明。

开发者在与用户数据保护(67%)、基础模型开发方式的基本细节(63%)、模型的功能(62%)和局限性(60%)相关的指标上得分很高。
这反映了开发人员在如何处理用户数据及其产品基本功能方面的一定程度的基线透明度。
3. 即使在开发人员最透明的子域中也存在改进的空间。
只有少数开发人员透明地展示其模型的局限性或让第三方评估模型的功能。
虽然每个开发人员都描述了其模型的输入和输出模式,但只有三个开发人员公开了模型组件,并且只有两个开发人员公开了模型大小。
开源或闭源模型
当今人工智能领域最具争议的政策争论之一是人工智能模型应该开源还是闭源。
虽然人工智能的发布策略不是二元的,但为了分析,将权重可广泛下载的模型标记为开放。
下面列表中的3个开发人员(Meta、Hugging Face和Stability AI)开发了开源基础模型(分别为Llama 2、BLOOMZ和Stable Diffusion2),其模型权重可以下载。
其他7名开发人员构建了闭源的基础模型,模型权重不可公开下载,并且必须通过API访问模型。

开源模型(Meta的Llama-2、Hugging Face的BLOOMZ和Stability AI的 Stable Diffusion 2)处于领先地位
开源模型处于领先地位。
三个开源模型中的两个(Meta 的 Llama 2 和 Hugging Face 的 BLOOMZ)得分大于或等于最佳闭源模型, Stability AI的Stable Diffusion 2紧随OpenAI的GPT-4之后。
这种差异很大程度上是由于闭源的开发人员在上游问题上缺乏透明度造成的,例如用于构建模型的数据、劳动力和计算,如下图。
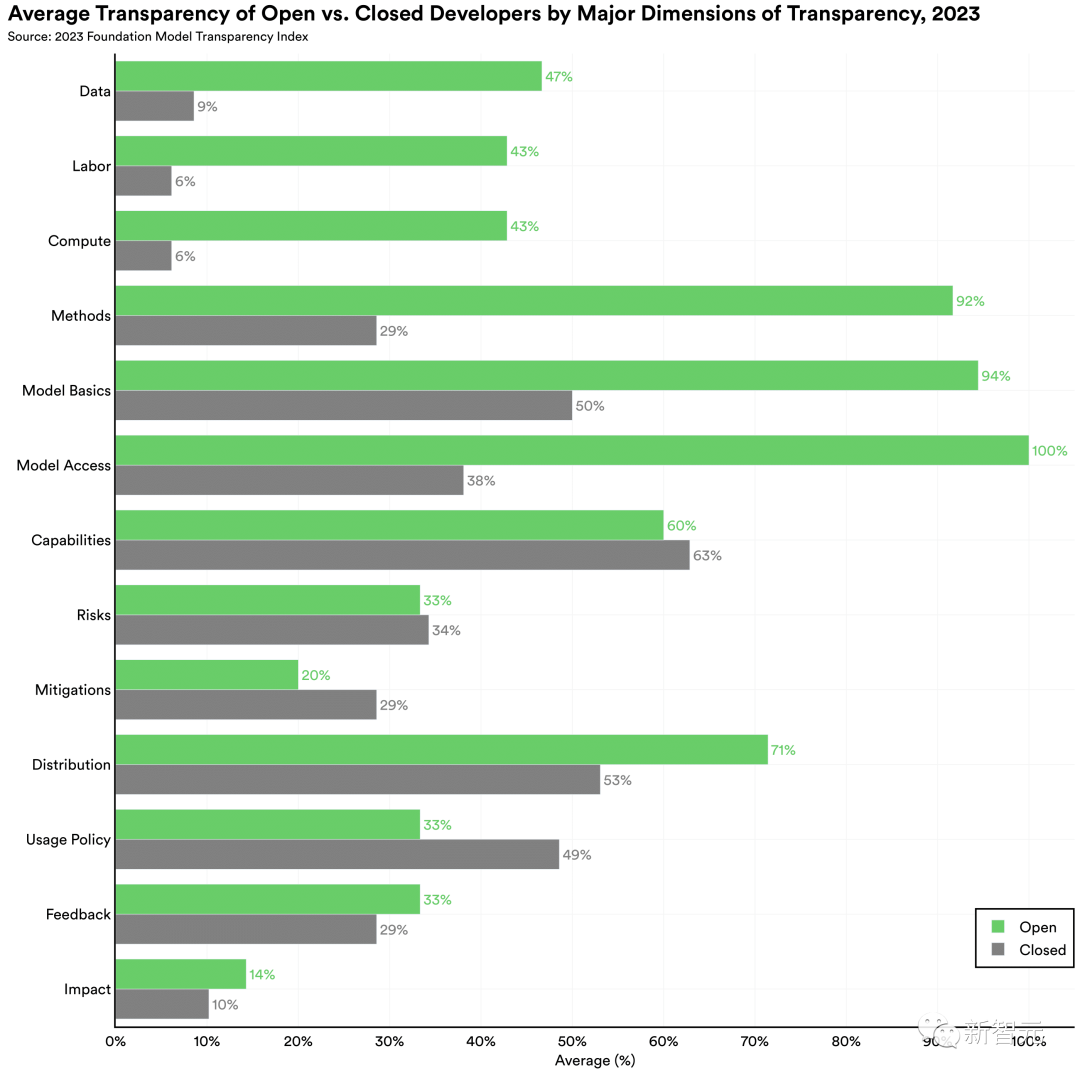
开源模型和闭源模型之间的差异是由上游指标驱动的,例如用于开发模型的数据、劳动力和计算的详细信息
就总体得分而言,开源基础模型开发者处于领先地位。开源模型和闭源模型开发人员之间的差异在构建模型所需资源(例如数据和计算)的指标上尤其明显。近年来,许多闭源模型的开发人员对训练模型的方法变得越来越保密。
如果想进一步了解方法与分析的结论,可以参考以下链接。
对于这些工作,有些网友还是对此表示认同。
有的人认为,推进模型透明度这项工作很有意义:这真的很酷,向前迈出了一大步!

还有网友表示这项工作太了不起了,并向作者提问如何看待最高比例只有54%的这个事实。
作者回应道,总体得分低得令人有些沮丧,但是有一个模型满足了82/100项,这意味着当前的限制还是可行的。


























