笔者的个人思考
- 为什么不直接用DINO, 而是用2D-UNet先做了一次蒸馏, 直接用DINO会有什么问题呢?
- 中间world model部分是transformer based的, 能否直接复用现有的LLM+adapter的方式;
- 这种方法理论上能否开车, 文章里只有一个video decoder输出video,文章中说现在还没有实时运行, 但是如果不考虑实时性, 加一个action decoder来输出自车动作,理论上应该能够开车,但这样自回归的输出也应该有action部分;
- world model部分编码的是2d的信息, 如果把3d的信息也加上是不是会更通用一些;
- 看文章发现是有好几个训练步骤的, 比如先训练 Image Tokenizer, 再训练World Model, 最后再训练Video Decoder部分,整个过程不能够端到端的一起训练么, 应该是可以的, 估计训起来比较费劲,可能不收敛。
- 假设输入不止有前视, 还有左前和右前, 如何做到不同相机视角下生成的视频具有一致性。
出发点是什么
自动驾驶有望给交通带来革命性的改善,但是 构建能够安全地应对非结构化复杂性的现实世界的场景的系统 仍然充满挑战。一个关键问题在于有效地 预测各种可能出现的潜在情况以及 车辆随着周围世界的演化而采取的动作。为了应对这一挑战,作者引入了 GAIA-1, 一个生成式的世界模型,它能够同时输入视频、文本和动作来生成 真实的驾驶场景,并且同时能够提供对自车行为和场景特征的细粒度控制。该方法将世界建模视为序列建模问题,通过把输入转化为离散的tokens, 预测序列中的下一个token。该模型有很多新兴特性, 包括学习高级结构和场景动态、情境意识、 概括和理解几何信息。GAIA-1 学习到的表征的强大能力可以捕获对未来事件的期望,再加上生成真实样本的能力,为自动驾驶领域的创新提供了新的可能性。
GAIA_1简介
预测未来事件对自动驾驶系统来说基本且重要。精准地预测未来使自动驾驶车辆能够预测和规划其动作,从而增强安全性和效率。为了实现这一目标,开发一个强大的世界模型势在必行。已经有工作在这方面做了很大努力, 比如. 然而,当前的方法有很大的局限性。世界模型已成功 应用于仿真环境下的控制任务和现实世界的机器人任务。这些方法一方面需要大规模的标注数据, 另一方面模型 对仿真数据的研究无法完全捕捉现实场景的复杂性。此外, 由于其低维表示,这些模型难以生成高度真实的 未来事件的样例, 而这些能力对于真实世界中的自动驾驶任务来说非常重要。
与此同时,图像生成和视频生成领域也取得了重大进步,主要是利用自监督学习从大量现实世界数据中学习生成非常真实的数据 视频样本。然而,这一领域仍然存在一个重大挑战:学习捕获预期未来事件的表示。虽然这样的生成模型 擅长生成视觉上令人信服的内容,但在学习动态世界的演化表示方面效果不太好,而这对于准确的预测未来和稳健的决策至关重要。
这项工作提出了 GAIA-1,它同时保持了世界模型和视频生成的优势. 它结合了视频生成的可扩展性和现实性以及世界模型的学习世界演变的能力。
GAIA-1 的工作原理如下。首先,模型分为两部分:世界模型和video diffusion decoder。世界模型负责理解场景中的high-level的部分及场景的动态演化信息, 而video diffusion decoder 则负责 将潜在表征转化回具有真实细节的高质量视频。
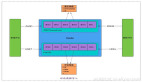
整个网络结构如下

对于世界模型,使用视频帧的矢量化表示来离散化每一帧 ,将它们转换为token序列。基于此就把预测未来转化为预测序列中的下一个token。这种方法已被广泛应用于训练LLM,并且得到了认可, 这种方法主要是通过扩展模型大小和数据来有效提高模型性能。它可以通过自回归的方式在世界模型的latent space内生成样本。
第二个部分是一个多任务video diffusion decoder,它能够执行高分辨率视频渲染以及时间上采样, 根据world model自回归产生的信息生成平滑的视频。类似于LLM,video diffusion model表明训练规模(模型大小和数据量)和整体表现之间存在明显的相关性,这使得 GAIA-1 的两个组件都适合有效的Scaling。
GAIA-1 是一个多模态的模型,允许使用视频、文本和动作作为提示来生成多样化且真实的驾驶场景,如下图 1 所示:

通过在大量真实的城市驾驶数据上训练, GAIA-1 学习了理解和区分一些重要概念,例如静态和动态元素,包括汽车、公共汽车、行人、骑自行车的人、道路布局、建筑物,甚至交通灯。此外,它还可以通过输入动作或者文本提示来细粒度地控制自车行为及场景特征。
GAIA-1展示了体现现实世界生成规则的能力。还有诸如学习高级结构、概括、创造力和情境意识等新兴的特性。这些表明该模型能够理解并再现世界的规则和行为。而且,GAIA-1 展示了对 3D 几何的理解,例如,通过有效地捕捉 由减速带等道路不平整引起的俯仰和侧倾间的相互作用。预测的视频也展示了其他智能体的行为, 这表明模型有能力理解道路使用者的决策。令人惊讶的是,它还能够产生训练集之外的数据的能力。例如,在道路边界之外行驶。
GAIA-1 学习到的表征预测未来事件的能力,以及对自车行为和场景元素两者的控制是一项令人兴奋的进步,一方面为进一步提升智能化效果铺平了道路, 另一方面也可以为加速训练和验证提供合成的数据。世界 像GAIA-1 之类的世界模型是预测接下来可能发生的事情的能力的基础,这对于自动驾驶的决策至关重要。
GAIA_1的模型设计
GAIA-1 可训练组件的模型架构。总体架构如上面图2所示。
编码视频、文本和动作
GAIA-1 可以输入三种不同的模式的内容(视频、文本、动作),这些输入信息被编码到共享的 d 维空间,这个空间是world model的输入空间, 注意不是输出空间, world model的输出空间的维度和下面的 的维度是一样的。
Image tokens
视频中的每桢图像都可以表示为离散tokens。比如可以使用一个pre-trained image tokenizer,这个模型记为. 输入 T桢图像序列 ,通过 将其离散化为 n = 576 个离散tokens, 即,其中每个 ,这里的 和图像离散化的方式有关系, 对应于 , H和W表示输入图像的高度和宽度,而D表示下采样因子。然后通过 一个 embedding layer 将映射到为 维空间中。
Text tokens
在每个时间 t,文本输入使用 pre-trained 的 T5-large 模型进行编码,得到每个 个文本tokens。再通过一个线性层同样映射到 维空间, 产生文本的表示。
action tokens
对于动作, 这里考虑 标量值(表示速度和曲率), 这里的曲率指的应该是方向盘的转角, 即 steering的意思。和之前类似, 每个scalar也通过线性层分别映射到 维空间,得到动作表示,
对于时间t,输入tokens按:文本 - 图像 - 动作 的顺序进行交错排列。因此,世界模型的最终输入是 。对于位置编码, 这里采用了, 个可学习的 temporal embedding, 以及 个 spatial embeddings, embeddings 的维度都是 。
Image Tokenizer
即上面提到的 。当使用序列模型对离散输入数据进行建模时,需要权衡序列长度和词汇量。序列长度是指离散tokens的数量, 词汇量大小代表每个token有多少种可能性。对于语言有两种明显的选择:字符和 单词。当使用字符级标记时,输入数据具有较长的序列长度,并且单个token所含词汇表较少,但传达的含义很少。使用单词级的 token时,输入数据的序列长度较短,每个token包含很多语义,但是 词汇量非常大。大多数语言模型 使用字节对编码 (或等效)作为字符级和单词级标记化之间的权衡。
对于视频,我们希望减少输入的序列长度,同时可能使 词汇量更大,但同时希望tokens 比原始像素在语义上更有意义。这里是用离散图像自动编码器来做的。在此过程中实现两个目标,
- 压缩原始像素的信息,使序列建模问题易于处理。因为图像包含大量冗余和噪声信息。我们希望减少 描述输入数据所需的序列长度。
- 引导压缩后的信息具有有意义的表示, 比如语义信息, 而不是大量没有用的信号, 这些信号会降慢世界模型的学习过程。
目标1的实现
下采样因子用 。每个大小为 的图像 由描述, 词汇量大小为 。
目标2的实现
本文用预训练的DINO 模型 抽取的特征来作为回归的target, 相当于是用DINO作为蒸馏的teacher,DINO是一个自监督的模型,它包含有丰富的语义信息, 如图3所示 DINO-distilled 得到的tokens看起来语义信息比较丰富.

蒸馏的student即离散的 autoencoder部分用的是全卷积的2D U-Net. 编码器通过在可学习嵌入表中查找最近邻对图像feature进行量化,产生图像tokens 。离散编码器 最终 GAIA-1 模型的一部分, 需要训练, 而Decoder是仅用来训练 的。需要注意的是Decoder是基于单桢图像进行训练的, 因此它不具有时间一致性, 出于这个原因, 也会训练一个video decoder, 这部分在后面介绍.
Image autoencoder的训练loss如下:
- 图像重建损失。图像重建损失有两部分, 分别是 感知损失 和 GAN 损失 。
- 量化损失。为了更新嵌入向量,我们使用嵌入损失和 文献中的commitment loss, 并且对 embedding 做了 linear projection 以及 l2 normalization, 实验表明这些有助于增加词汇量的使用。
- Inductive bias loss。autoencoder量化的图像特征与DINO提取的图像特征用cosine similarity loss 度量来监督, 这种方法在特征监督中常用.
世界模型
世界模型的输入是序列 ,是transformer based自回归网络结构。训练的目标是基于过去的所有tokens(图像, 文本, 动作)预测接下来的 image token.
loss 函数为
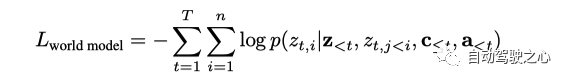
为了在推理的时候, 能够同时输入文本或动作作为提示, 在训练的时候会随机把输入的文本或者动作tokens给dropout掉.
为了进一步减少世界模型输入的序列长度,对输入的视频作了进一步采样, 从原来的25HZ变为6.25HZ。这能让世界模型能够在更长的时间内进行推理。为了以全帧速率恢复视频预测,在video decoder部分用了temporal super-resolution。
视频解码器
随着图像生成和视频生成的最新进展,在GAIA-1的decoder部分, 使用了 denoising video diffusion models。一个自然的想法是把每一桢的 frame tokens 解码到像素空间, 但是这样得到的不同桢对应的pixel, 在时间上不具有一致性。这里的处理方法是, 把问题建模为 在扩散过程中对一系列帧进行去噪,模型可以访问到整个时间段内的信息,这样做明显提高了输出视频的时间一致性。
这里用的是3D U-Net网络结构, 它里面包括分解空间层和时间注意力层。这里要注意训练和推理时的输入不一样, 训练时的输入是 用 pre-trained image tokenizer 得到的image tokens; 推理的时候因为没有观测, 输入的是由 World Model 预测的 image tokens.
我们在图像和视频生成任务上联合训练单个模型。用视频训练 会让解码器学习在时间上保持一致,用图像训练对于单桢图像质量至关重要,因为它学习的是从从图像tokens中提取信息。要注意在图像训练时没有用时间层。
为了训练视频扩散解码器执行多个推理任务,可以通过masking 掉某些frames 或者是 某些 image tokens。这里针对所有的任务, 训练了单个视频扩散模型, 任务包括图像生成、视频生成、 自回归解码和视频插值, 每个任务均等采样。例如, 在自回归生成任务中,用之前生成的过去帧作为输入 用要预测的帧的图像tokens作为target。自回归的任务中包含正向和反向, 有关每个任务的示例,请参见下图 4。

并且在训练的时候以概率 p = 0.15 随机mask掉输入的image token, 以摆脱对于观测image token的依赖进而提升泛化能力和时间一致性。
video decoder是根据 noise prediction objective 进行训练。更具体地说,采用v-parameterization的方法,因为它避免了不自然的 color shifts 并保持 长期一致性。
loss 函数为

训练数据
训练数据集包含在伦敦收集的 4,700 小时、25Hz 的驾驶数据,数据集中的时间跨度为2019 年至 2023 年。大约 4.2 亿张图像。不同经纬度及不同天气下的数据比例分布如下

训练过程
Image Tokenizer
参数量有0.3B, 输入图像的大小为 , 下采样因子 , 因此每个图像被encoded成为 个tokens, 词汇量size为 。离散自动编码器使用 AdamW进行优化,模型用32个80G的A100训练 4 天,总计20w steps, batch-size 大小为160.
世界模型
世界模型参数量为6.5B , 在长度为 T = 26、频率为 6.25 Hz 的视频序列上进行训练,对应4秒长的视频。文本被编码为 m = 32 个文本tokens,并且 动作为 tokens。因此,世界模型的总序列长度为

训练样本有三种:只用图像, 用图像及action, 用图像及文本数据. 该模型用64个80G的A100要训练15天, 总计10w steps, batch-size为128。这里使用了 FlashAttention v2 实现 transformer模块,因为它在内存利用率和 推理速度上面有很大提升。为了优化分布式训练,使用了 Deepspeed ZeRO-2 训练策略。
Video Decoder
视频解码器的参数量有2.6B, 在 长度T ′ = 7 , 分辨率为 的图像序列上进行训练, 但是采样频率有三种: 6.25 Hz、12.5 Hz 或 25 Hz 。各个训练任务(上面的图4)以等概率进行采样。该模型用32个80G的A100训练了 15, 总计30w steps , batch-size大小为 64。训练策略也是 Deepspeed ZeRO-2。
模型推理
World Model
采样
世界模型基于之前的图像token, 文本token和 动作 token 自回归预测下一个图像token。因为一个图像中有 个token, 所以要预测一个新的image frame, 需要n个forward, 在每一步中,必须从预测的 logits 中采样一个 token 以选择下一个 预测的token。选token的方法有多种, 这里观察到如果用argmax的话会生成陷入重复循环的 future,类似于语言模型 [44]。但是,如果简单地从 logits 中采样,则所选token可能来自不可靠的尾部概率分布(即分数低的那些),这会使模型脱离分布。如下图6所示
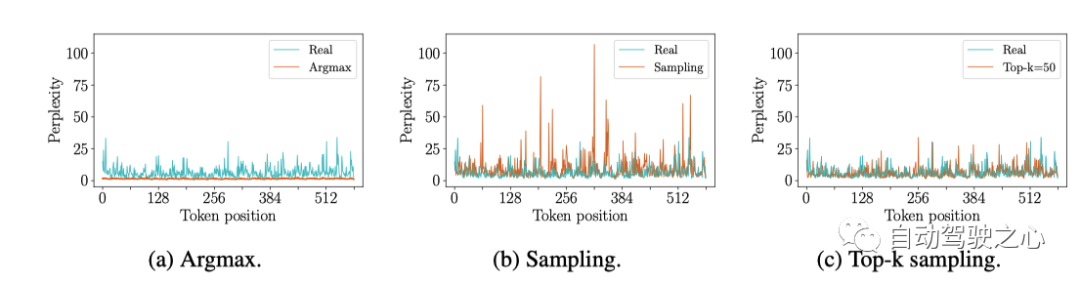
为了多样性和真实性,这里采用的是 top-k 采样来采样下一个图像token。最终得到的世界模型可以在给定起始背景下,也可以不需要任何上文从头推理出可能的未来。
对于长视频生成,如果视频的长度 超过世界模型的上下文长度,可以采用滑动窗口的方式。
Text-conditioning
可以用文本来提示并指导视频预测。训练时,可以将在线的旁白描述或者是离线的文本和视频一起输入。由于这些文本源有noise,为了提高生成的futures与文本prompt之间的对齐效果,在推理时采用classifier-free guidance的方式.Classifier-free guidance 的效果是通过减少可能的多样性来增强文本图像对齐效果 。更准确地说,对于每个要预测的下一个token,
同时计算有文本作为prompt时的logits, 和无文本作为prompt时的logits, 然后用系数 来控制两个logits占的比例, 如下公式

通过将无提示的 logits 替换为以另一个文本提示得到的 logits,可以 进行Negative提示。并且把negative prompt 与 positive prompt 推远, 可以使得future tokens 更多地包括 positive prompt features.
用于 guidance 的scale 系数非常重要, 如下图, 文本prompt是 "场景中包含一量红色的公交车",

可以看到, SCALE=1的时候, 就没有红色的公并车, SCALE=20的时候,恰好有一辆, SCALE=20的时候, 不止有一辆红色公交车, 而且还有一辆白色公交车.
Video Decoder
为了解码从世界模型生成的token序列,具体的方法如下:
- 以对应的 T' image tokens,解码前 T ′ = 7 帧;如下图所示

- 使用过去的 2 个重叠帧作为图像context, 以及接下来的T ′ -2 图像tokens自回归解码接下来的 T ′ -2 帧。如下图所示

- 重复自回归过程,直到以 6.25 Hz 生成 N 帧。
- 将 N 帧从 6.25 Hz 做Temporally上采样得到 12.5 Hz
- 将 2N- 1 帧从 12.5 Hz Temporally上采样到 25.0 Hz
在自回归decoding过程中, 需要同时考虑生成的图片质量以及时间一致性, 因此这里做了一个加权,
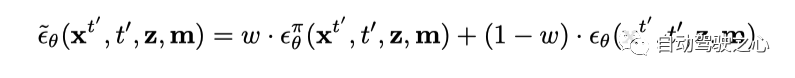
其中等式右边第一项将每个帧分别作为图像进行去噪, 等式右边第二项将帧序列联合降噪为视频。在实际应用中,只需打开或者关闭时间层。这里对每个diffusion step 用的概率用这个加权平均, 并且采取的.
在探索视频解码的不同推理方法时,发现解码视频 从序列末尾开始自回归地向后会导致更稳定的物体, 并且地面上的闪烁也更少。因此在整个视频解码方法中,先解码最后的 T ′ 帧, 之后从后往前解码剩余的桢。
Scaling
GAIA-1 中世界建模任务的方法经常在大型语言模型(LLM)中使用, 类似于GPT。在这两种情况下,任务都被简化为预测下一个token。尽管GAIA-1中的世界模型建模的任务和LLM中的任务不同, 但是与LLM中类似, Scaling laws同样对于GAIA-1适用.这说明Scaling laws对于很多领域都是适用的, 包括自动驾驶。
为了探索 GAIA-1 的Scaling Laws,我们使用以下方法预测了世界模型的最终性能 使用小于 20 倍计算量训练的模型。对比的标准是看cross-entropy, 并且采用下面的函数来拟合 数据点。在图8a中,可以看到GAIA-1的最终交叉熵预测精度很高。
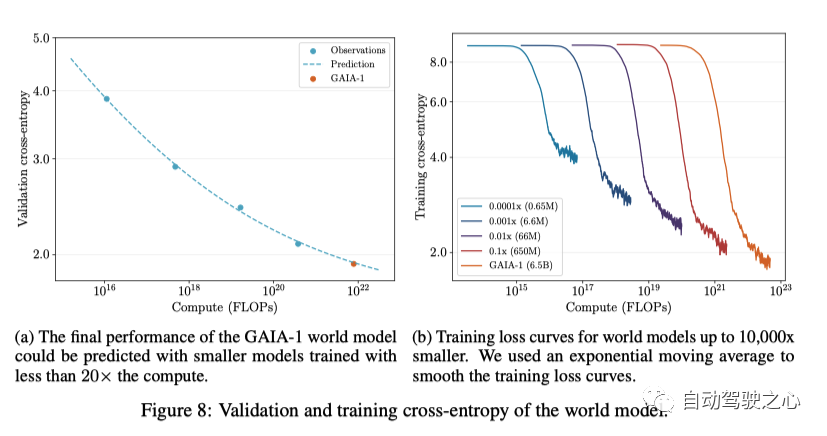
如图 8b 所示, 可以看出, 随着模型变大, 训练时候的cross-entropy 会收敛地越来越低,上面说明可以通过扩展数据和计算资源来进一步提升模型的性能。
Capabilities and Emerging Properties (能力和新兴特性)
这一节主要是效果展示的例子。这里有个youtube的连接: https://www.youtube.com/playlist?list=PL5ksjZd5b6SI-6MQi6ghoD-GilTPmsQIf
下面图9显示了GAIA-1可以生成各种场景。

下面是GAIA-1通过一些新兴特性展示了对世界的生成规则的一定程度的理解和总结:
- 学习高级结构和场景动态:它生成与连贯的场景 并且物体放置在合理的位置上, 并展示真实的物体之间的交互,例如交通 灯光、道路规则、让路等。这表明该模型不仅仅是记忆 统计模式,而是理解了我们生活的世界中关于物体的底层规则, 比如物体是如何摆放, 有何行为。
- 泛化性和创造性:可以生成不在训练集里的新颖多样的视频 。它可以产生物体、动作的独特组合, 以及训练数据中未明确出现的场景,这表现出它有显著的泛化能力,并且表现出了一定程度的概括性和创造性, 这表明GAIA-1对视频序列的生成规则有较好的理解.
- 情境感知:GAIA-1 可以捕获情境信息并生成视频 来体现这种理解。例如,它可以基于初始条件或提供的上下文 产生连贯的动作和响应。此外,GAIA-1 还展示了对 3D 几何的理解,有效捕获到由于道路不平整(例如减速带)引起的侧倾。这种情境意识表明这些模型不仅能常握训练集中数据的统计规律,而且还积极地处理和总结给定的信息以生成适当的视频序列。
长时间驾驶场景的生成
GAIA-1 可以完全凭想象生成稳定的长视频, 如下图所示表现了40s的生成数据:

这主要是该模型利用其学习到的世界隐式先验分布来生成完全 想象的真实驾驶场景。这里应该采用了类似于MILE里的先验分布做法。生成的驾驶场景中具有复杂的道路布局、建筑物、汽车、行人等。这证明 GAIA-1 理解了支撑我们所居住的世界的规则及其结构和动力学。
多个合理未来的生成
GAIA-1 能够根据单个初始提示生成各种不同的未来场景。当以简短的视频作为输入时, 它可以通过不断地sampling产生大量合理且多样化的内容。GAIA-1 针对视频提示能够准确模拟多种潜在的未来场景,同时与在初始视频中观察到的条件保持一致。
如下图所示, 世界模型可以推理 (i) 道路使用者(例如让路或不让路)

上面两个分别对应着, 他车不让路, 和他车让路的情况。(ii)多种自车行为(例如直行或右转)

(iii) 多种动态场景(例如可变的交通密度和类型)

自车行为和驾驶场景的细粒度控制
GAIA-1可以仅根据文字提示生成视频,完全想象场景。我们展示了如何根据文本提示模型生成驾驶场景, 如下所示展示的是对天气和光照的细粒度控制.


下面是个令人信服的示例,其中模型展示了对车辆的细粒度控制。通过利用此控制,我们可以提示模型生成视频描述训练数据范围之外的场景。这表明 GAIA-1 能够将自车的动态与周围环境分开并有效地应用于 不熟悉的场景。这表明它能够来推理我们的行为对世界的影响,它可以更丰富地理解动态场景,解锁 基于模型的Policy learning(在world model中做planning),它可以实现闭环仿真探索(通过将世界模型视为模拟器)。为了展示这一点,这里展示了 GAIA-1 生成 未来,自车向左或向右转向,偏离车道等场景, 如下图所示:

GAIA-1 在训练数据集中从未见过这些不正确的行为,这表明 它可以推断出之前在训练数据中未见过的驾驶概念。我们也看到了现实 其他智能体对自车受控行为的反应。最后,这个例子展示了 GAIA-1 利用文本和动作来充分想象 驾驶场景。在这种特殊情况下,我们提示模型自车要超车公交车。

GAIA_1的总结和未来方向
GAIA-1 是自动驾驶领域的生成式世界模型。世界模型使用矢量量化 将未来预测任务转变为下一个token的预测任务,该技术 已成功应用于大型语言模型。GAIA-1 已展示其具有 全面了解环境,区分各种概念 例如汽车、卡车、公共汽车、行人、骑自行车的人、道路布局、建筑物和交通灯的能力, 这些全是通过自监督的方式学到的。此外,GAIA-1 利用视频扩散模型的功能 生成真实的驾驶场景,从而可以作为先进的模拟器使用。GAIA-1 是 一种多模态的方法,通过文本和动作指令相结合可以控制自车的动作和其他场景属性。虽然该方法展示了有潜力的结果,有可能突破自动驾驶的界限,但是重要的是也要承认当前的局限性。例如,自回归的生成过程虽然非常有效,但尚未实时运行。尽管如此,这个过程非常适合并行化,允许并发生成多个样本。GAIA-1 的重要性超出了其生成能力。世界模型代表了向 实现能够理解、预测和适应复杂环境的自动驾驶系统迈出的关键一步。此外,通过将世界模型融入驾驶模型中, 我们可以让他们更好地理解自车的决策,并最终推广到更多 现实世界的情况。最后,GAIA-1 还可以作为一个有价值的模拟器,允许 生成无限数据,包括corner-case和反例,用于训练和验证自动驾驶系统。
文章链接: https://browse.arxiv.org/pdf/2309.17080.pdf
官方博客1: https://wayve.ai/thinking/introducing-gaia1/
官方博客2: https://wayve.ai/thinking/scaling-gaia-1/

原文链接:https://mp.weixin.qq.com/s/dPfqukDLUvhrfZ0a0b6X6A