












本文经自动驾驶之心公众号授权转载,转载请联系出处。
一、Tesla FSD V12 2023
方案
具体方案暂未公开,只有以前的一些非完整端到端的方案资料:
视频
https://www.bilibili.com/video/BV1nh4y1g7kN/?spm_id_from=333.337.search-card.all.click&vd_source=bd235d6e6aad74d3a6ab16cc9c111560

这里的视频里讲的是基于Occupancy Network + Occupancy Prediction + 基于Occupancy的规划,这种方案可以弱化算法对在线建图的依赖,也更有利于感知与规控间信息减少多模态信息丢失。但需要很强的数据基建。
效果
端到端能做到这样确实很惊人,但是要真论实际效果,当前比起现在业界L4的规则方案肯定是差很多的,但如果真的宣传的水分不是很大的话,确实是很快会革新行业的。
二、UniAD 2023
方案
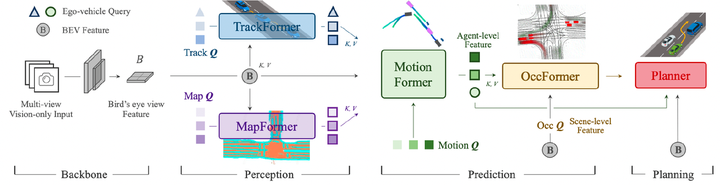
走的是Tesla的OccNetwork + Occ Pred的路子,不过地图使用语义分割有一个显式的在线建图过程。主要思路是每个模块单独训练,训完之后拿单独训练到的模型初值,串在一起拿Planner的cost为主进行整体refine。
论文:https://arxiv.org/pdf/2212.10156.pdf
效果
2023 CVPR Best Paper,但只评估了开环效果,闭环应该是不是很好。
三、Momenta新方案 2023
方案
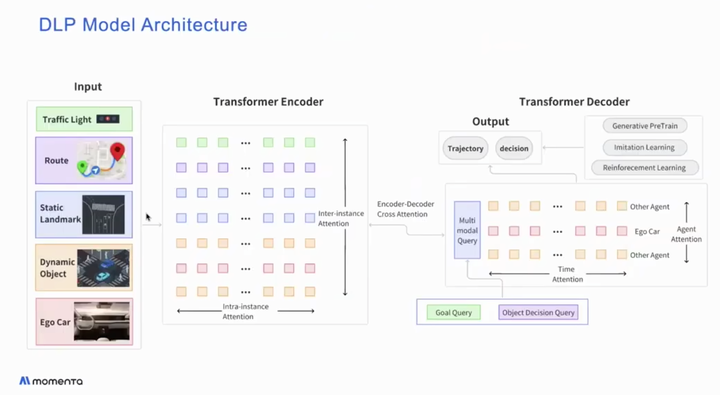
- 看这个图只确认了Decision & Goal是Transformer出来的,对于Trajectory画得比较模糊,预计当前依然是值优化方法,不清楚未来想如何解决梯度回传问题。
- 没有使用Occupancy Network表达地图,而是直接Online HDMap Construction来解决无图问题
视频:
https://www.bilibili.com/video/BV1gj411Z7PL/?spm_id_from=333.337.search-card.all.click&vd_source=bd235d6e6aad74d3a6ab16cc9c111560
效果
端到端方案还未完成上线,说是计划2023年底Planner端到端,2025年中整体端到端。
暂时不清楚效果,但Momenta这个是自动驾驶工业界里很少的直接公开自己要全面做端到端自动驾驶的,于是列在前头。
四、地平线nuPlan参赛方案
方案
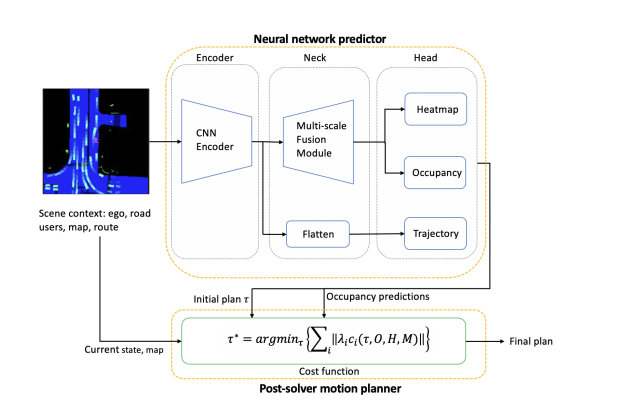
先用模型生成一个粗轨迹和OCC及heat map,然后用heat map + OCC作为势场,利用数值优化方法,推动粗轨迹优化出一条安全轨迹。
论文:https://arxiv.org/pdf/2306.15700.pdf
效果
NuPlan比赛第二名
五、云骥智行方案 2023
方案
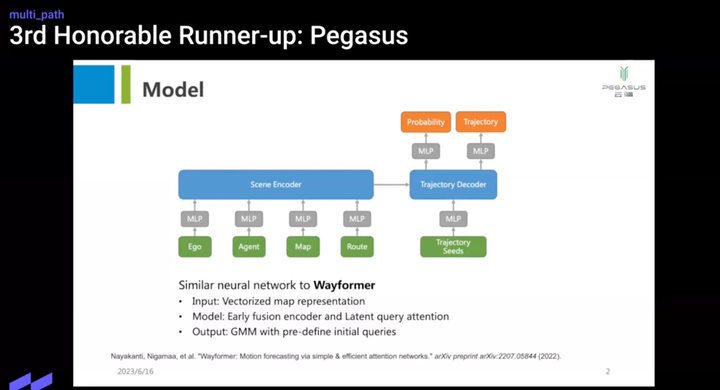
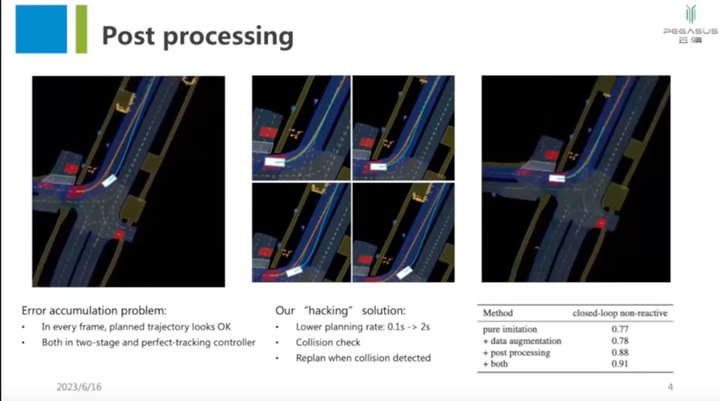
看起来就是直接拿了个预测算法当planner用,然后做了些Tricky,比如2s才规划一次,检测到碰撞的话replan。
个人感觉这个方案对做规划参考意义有限。
论文
https://opendrivelab.com/e2ead/AD23Challenge/Track_4_pegasus_weitao.pdf
效果
nuPlan比赛第三名
六、Motional的L4 RoboTaxi方案 2022
方案
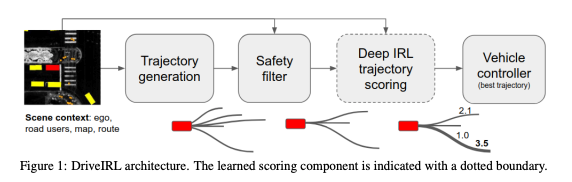
论文:https://arxiv.org/pdf/2206.03004.pdf
先用规则生成大批待选轨迹,然后用规则进行剪枝,确保安全性,再用IRL训出来的模型来给剩余轨迹打分,最终选择排序最高的轨迹。
思路很简单直接,但该方案胜在与Rule可以很好的结合来确保绝对安全,又可以充分利用Learning Based算法来确保长时规划合理性,确保体感和避免走入潜在风险场景。
效果
不完全是端到端,仅是部分替换motion planning。
论文不怎么出名,但实车验证过效果不错,安全性优于IDM
国内也有公司使用与此类似的方案做L4实车全无人RoboTaxi的,因为可以与规则类方法很好的协同,效果比较好。
七、一些学术界基于Occ + Occ Pred的论文
方案
以Occupancy Prediction-Guided Nerual Planner for Autonomous Driving为例:
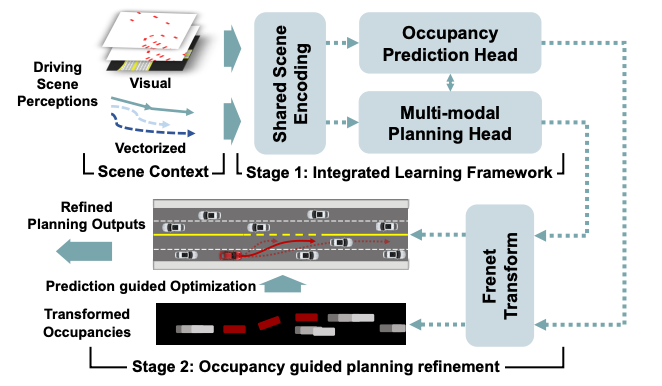
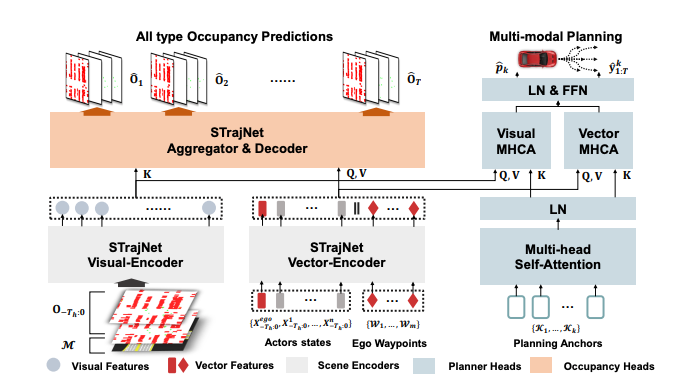
输入信息比较杂,有Occ Visual Feature,也有一些Vector Feature。
用多种Prediction(如ChauffeurNet等)混合起来做Occ Prediction
然后且主车预测轨迹和Occ预测结果作为做数值优化的输入,设计了几种cost,然后用非线性数值优化求解器求解。
除去输入是Occ Network,后边这块儿方案和地平线的还有点像。
论文:https://export.arxiv.org/pdf/2305.03303
八、其他
暂调研了这些。强化学习相关的方案本次暂未调研。
总结
一个不得不提的重要信息
在CVPR 23 AD Challenge NuPlan挑战中,夺得第一的,是一个Rule Based算法。
论文
https://arxiv.org/pdf/2306.07962.pdf
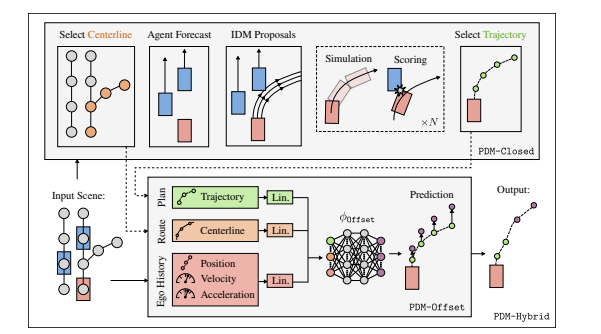
该论文中做了几个实验:
- 20年前就提出的IDM算法,比他找的几个SOTA的Learning Based算法闭环分数都高。但开环评分Learning Based算法一般更优。
- 他们试验,使用一个仅使用中心线而不使用障碍物的方法,开环评分就直接击败了众多SOTA方案。
- 他前2秒轨迹用IDM稍微改装的算法,后n秒轨迹用前述Learning Based方法生成,出了一个混合模型,开闭环效果都最优,击败了一众对手获得第一名。要知道,后n秒轨迹实际上闭环跑的时候根本用不上,所以这个方法本质上可以说就是个纯Rule Based方法。这个算法甚至连变道都不支持...
得到结论:
- Learning Based算法擅长长时规划,Rule Based算法擅长短时规划。
- 闭环效果更需要好的短时规划能力,开环效果主要看长时规划能力。
对我们来说,启发就是,目前学术界的方法效果与工业界差得还是有点多的,想要达成好的效果,短期来看,依然是要强依赖规则,如何让规则与模型更好的融合,才是当前最有希望的路子。
因此前述论文,个人感觉对于工业界,最有希望效果比较好的路子是多参考Motional的Driving in Real Life with Inverse Reinforcement Learning 这篇,以及地平线的方案,这两个方案都相对容易与现有的规则算法一起工作。





























