












几个月前,来自 KAUST(沙特阿卜杜拉国王科技大学)的几位研究者提出了一个名为 MiniGPT-4 的项目,它能提供类似 GPT-4 的图像理解与对话能力。
例如 MiniGPT-4 能够回答下图中出现的景象:「图片描述的是生长在冰冻湖上的一株仙人掌。仙人掌周围有巨大的冰晶,远处还有白雪皑皑的山峰……」假如你接着询问这种景象能够发生在现实世界中吗?MiniGPT-4 给出的回答是这张图片在现实世界中并不常见,并给出了原因。

短短几个月过去了,近日,KAUST 团队以及来自 Meta 的研究者宣布,他们将 MiniGPT-4 重磅升级到了 MiniGPT-v2 版本。

论文地址:https://arxiv.org/pdf/2310.09478.pdf
论文主页:https://minigpt-v2.github.io/
Demo: https://minigpt-v2.github.io/
具体而言,MiniGPT-v2 可以作为一个统一的接口来更好地处理各种视觉 - 语言任务。同时,本文建议在训练模型时对不同的任务使用唯一的识别符号,这些识别符号有利于模型轻松的区分每个任务指令,并提高每个任务模型的学习效率。
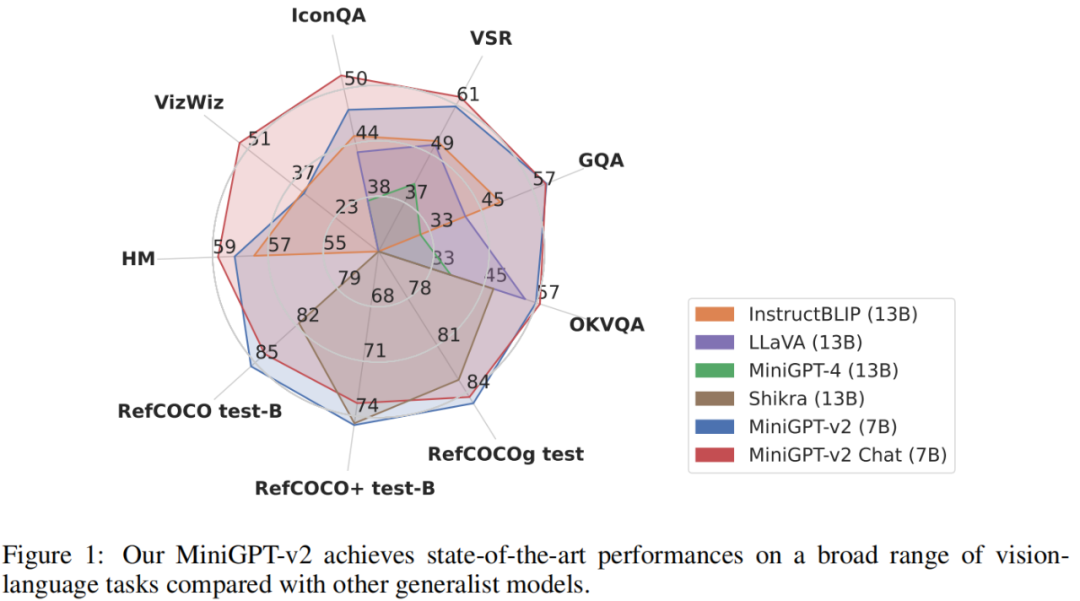
为了评估 MiniGPT-v2 模型的性能,研究者对不同的视觉 - 语言任务进行了广泛的实验。结果表明,与之前的视觉 - 语言通用模型(例如 MiniGPT-4、InstructBLIP、 LLaVA 和 Shikra)相比,MiniGPT-v2 在各种基准上实现了 SOTA 或相当的性能。例如 MiniGPT-v2 在 VSR 基准上比 MiniGPT-4 高出 21.3%,比 InstructBLIP 高出 11.3%,比 LLaVA 高出 11.7%。
下面我们通过具体的示例来说明 MiniGPT-v2 识别符号的作用。
例如,通过加 [grounding] 识别符号,模型可以很容易生成一个带有空间位置感知的图片描述:

通过添加 [detection] 识别符号,模型可以直接提取输入文本里面的物体并且找到它们在图片中的空间位置:

框出图中的一个物体,通过加 [identify] ,可以让模型直接识别出来物体的名字:
 通过加 [refer] 和一个物体的描述,模型可以直接帮你找到物体对应的空间位置:
通过加 [refer] 和一个物体的描述,模型可以直接帮你找到物体对应的空间位置:

你也可以不加任何任务识别符合,和图片进行对话:

模型的空间感知也变得更强,可以直接问模型谁出现在图片的左面,中间和右面:

方法介绍
MiniGPT-v2 模型架构如下图所示,它由三个部分组成:视觉主干、线性投影层和大型语言模型。

视觉主干:MiniGPT-v2 采用 EVA 作为主干模型,并且在训练期间会冻结视觉主干。训练模型的图像分辨率为 448x448 ,并插入位置编码来扩展更高的图像分辨率。
线性投影层:本文旨在将所有的视觉 token 从冻结的视觉主干投影到语言模型空间中。然而,对于更高分辨率的图像(例如 448x448),投影所有的图像 token 会导致非常长的序列输入(例如 1024 个 token),显着降低了训练和推理效率。因此,本文简单地将嵌入空间中相邻的 4 个视觉 token 连接起来,并将它们一起投影到大型语言模型的同一特征空间中的单个嵌入中,从而将视觉输入 token 的数量减少了 4 倍。
大型语言模型:MiniGPT-v2 采用开源的 LLaMA2-chat (7B) 作为语言模型主干。在该研究中,语言模型被视为各种视觉语言输入的统一接口。本文直接借助 LLaMA-2 语言 token 来执行各种视觉语言任务。对于需要生成空间位置的视觉基础任务,本文直接要求语言模型生成边界框的文本表示以表示其空间位置。
多任务指令训练
本文使用任务识别符号指令来训练模型,分为三个阶段。各阶段训练使用的数据集如表 2 所示。

阶段 1:预训练。本文对弱标记数据集给出了高采样率,以获得更多样化的知识。
阶段 2:多任务训练。为了提高 MiniGPT-v2 在每个任务上的性能,现阶段只专注于使用细粒度数据集来训练模型。研究者从 stage-1 中排除 GRIT-20M 和 LAION 等弱监督数据集,并根据每个任务的频率更新数据采样比。该策略使本文模型能够优先考虑高质量对齐的图像文本数据,从而在各种任务中获得卓越的性能。
阶段 3:多模态指令调优。随后,本文专注于使用更多多模态指令数据集来微调模型,并增强其作为聊天机器人的对话能力。
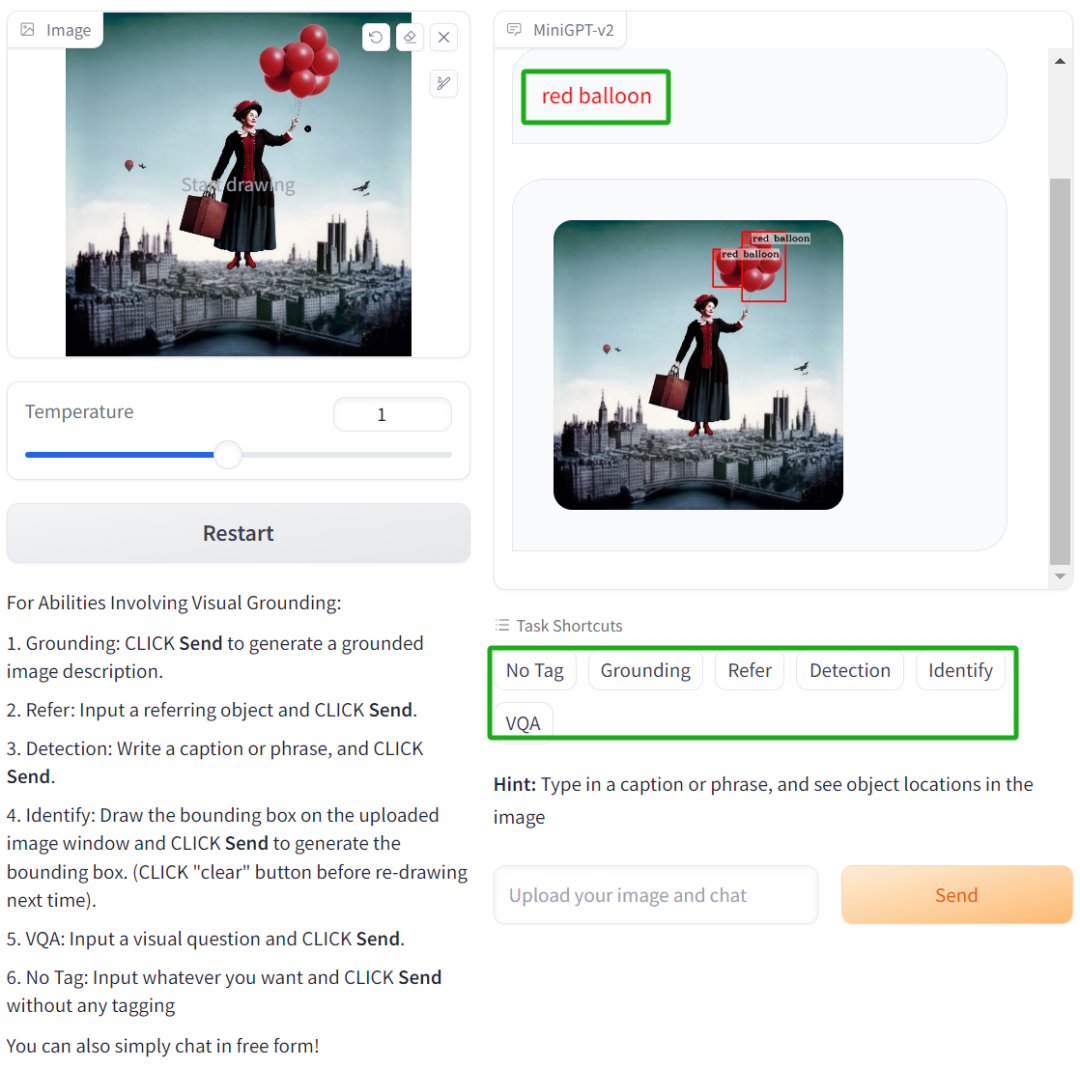
最后,官方也提供了 Demo 供读者测试,例如,下图中左边我们上传一张照片,然后选择 [Detection] ,接着输入「red balloon」,模型就能识别出图中红色的气球:
感兴趣的读者,可以查看论文主页了解更多内容。
























